Essence
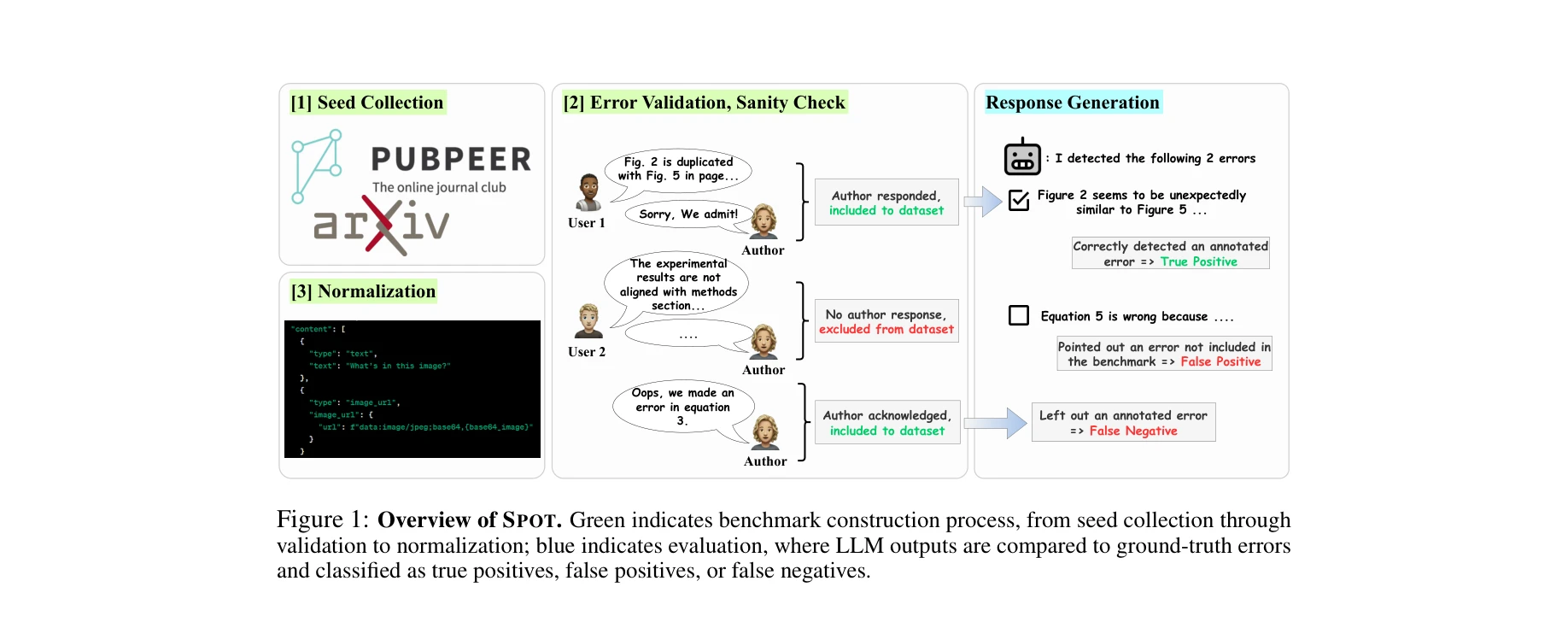
SPOT 벤치마크의 구축 과정: 시드 수집(녹색)부터 검증, 정규화를 거쳐 평가 단계(파란색)까지 LLM 출력을 기준 오류와 비교
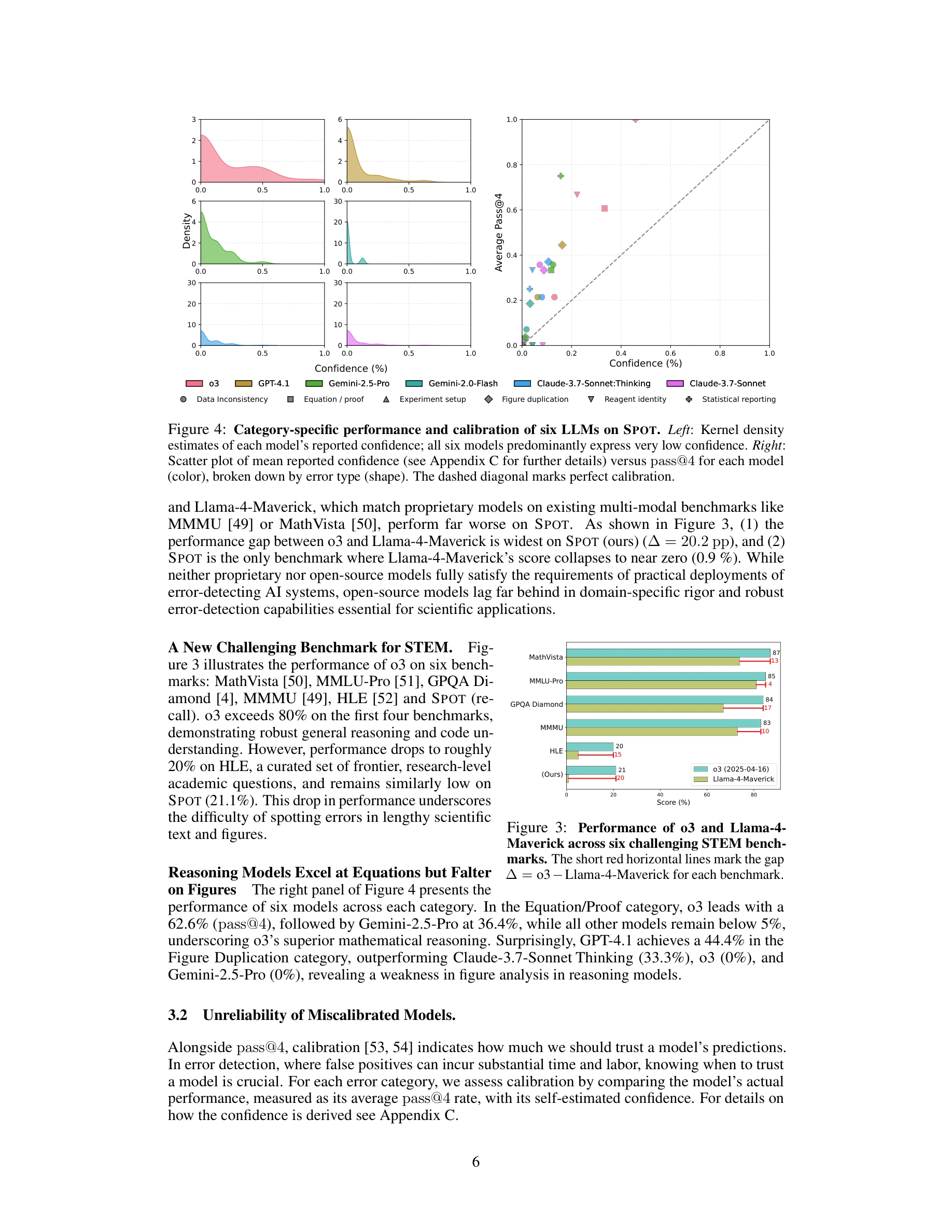
대규모 언어모델(LLM)이 과학 논문의 오류를 자동으로 검증할 수 있는가를 묻는 본 논문은 83개 출판 논문과 91개의 검증된 오류로 구성된 SPOT 벤치마크를 제시하며, 최신 LLM들도 21.1% 이하의 재현율(recall)에 머물러 신뢰성 있는 학술 검증 자동화는 아직 불가능함을 보여준다.
저자: Guijin Son, Jiwoo Hong, Honglu Fan, Heejeong Nam, Hyunwoo Ko, Seungwon Lim, Jinyeop Song, Jinhang Choi, Gonçalo Paulo, Youngjae Yu, Stella Biderman | 날짜: 2025 | DOI: N/A
SPOT 벤치마크의 구축 과정: 시드 수집(녹색)부터 검증, 정규화를 거쳐 평가 단계(파란색)까지 LLM 출력을 기준 오류와 비교
대규모 언어모델(LLM)이 과학 논문의 오류를 자동으로 검증할 수 있는가를 묻는 본 논문은 83개 출판 논문과 91개의 검증된 오류로 구성된 SPOT 벤치마크를 제시하며, 최신 LLM들도 21.1% 이하의 재현율(recall)에 머물러 신뢰성 있는 학술 검증 자동화는 아직 불가능함을 보여준다.
오류의 학문 분야별, 유형별 분포: 수학/물리/컴퓨터과학은 수식/증명 오류에 집중, 생물학은 그림 중복에 편향
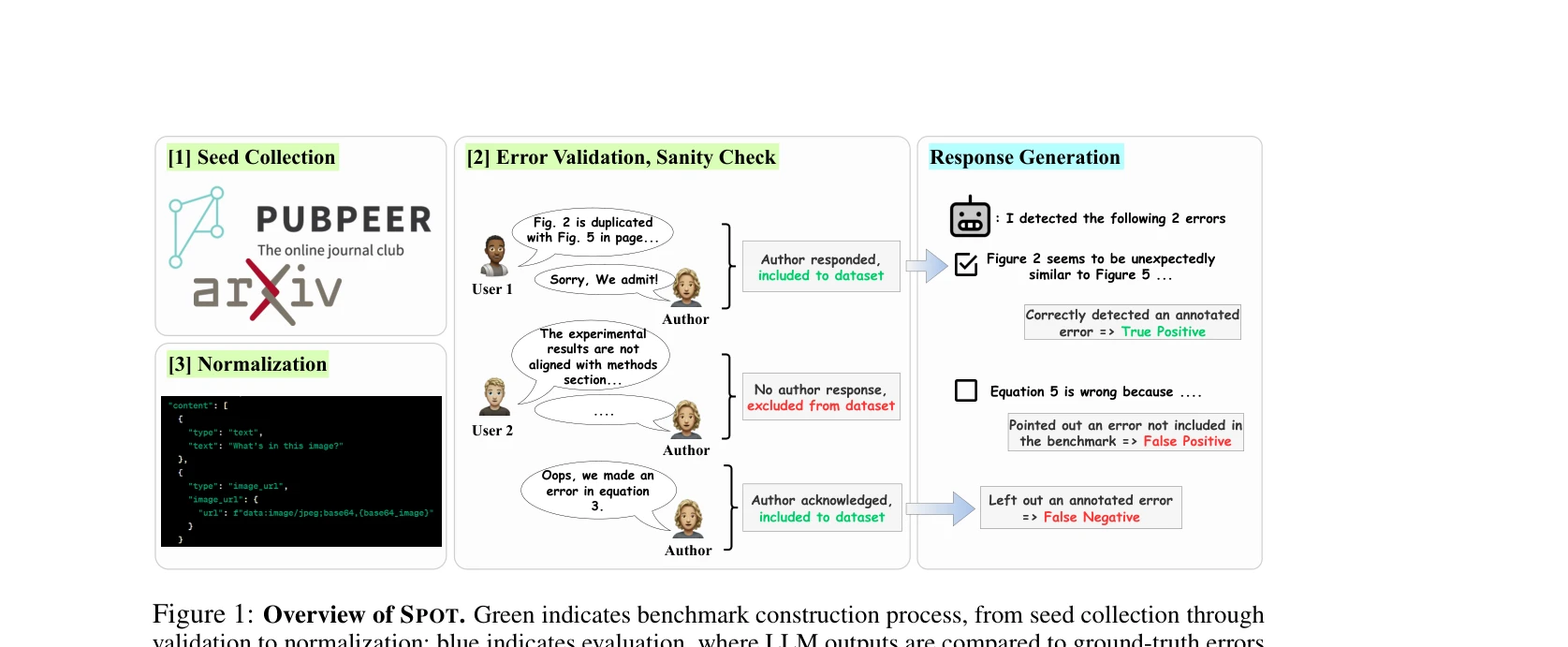
TP/FP/FN 분류: 모델이 정확한 위치의 오류를 발견하면 TP, 벤치마크에 없는 오류를 지적하면 FP, 실제 오류를 놓치면 FN
데이터 수집 및 정규화:
평가 프로토콜:
오류 분류:
한계:
후속 연구:
총평: SPOT은 LLM의 약점을 체계적으로 드러내는 견고한 벤치마크로, 현재 AI 시스템이 신뢰성 있는 과학 검증자가 되기 위해 넘어야 할 실질적 거리가 얼마나 큰지를 증명한다. 규모 한계는 있으나, 저자 확인 + 이중 검증을 통한 질적 우수성과 다중모달 장문맥의 현실적 복잡도에서 의의가 크다.