Achievement
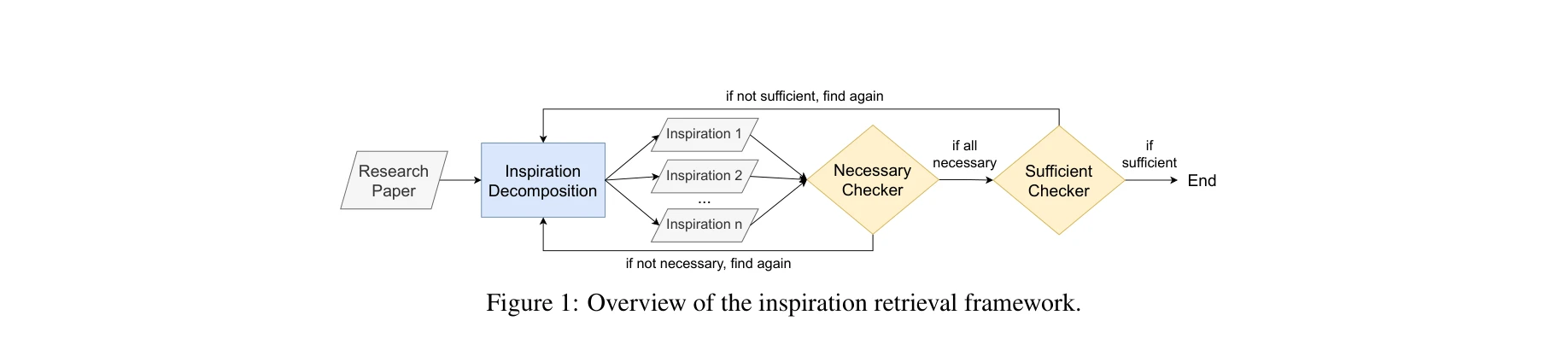
영감 검색 프레임워크: 논문에서 추출된 잠재적 영감을 필요성 검증(Necessary Checker)과 충분성 검증(Sufficient Checker)을 거쳐 확정
- 첫 번째 대규모 과학 발견 벤치마크 구축: 12개 분야(화학, 물리학, 천문학, 생물학, 재료과학, 에너지과학, 환경과학, 비즈니스, 법학, 수학 등) 1,386편의 Nature/Science 급 논문으로 구성. 전문가 검증 결과 91.9% 정확도(주요 이슈만 고려) 달성.
- 혁신적 LLM 기반 자동 추출 프레임워크: 연구 질문, 배경 조사, 가설의 직접적 추출과 달리, 영감 추출을 위해 필요성/충분성 검증 이중 구조를 설계하여 정확도 향상. 향후 LLM 학습 데이터 커트오프 이후에도 자동 확장 가능한 설계.
- 데이터 오염 방지 및 분포 외(OOD) 작업 발견: 2024년 이후 논문만 선택하여 기존 LLM 사전학습 데이터와의 중복 최소화. 영감 검색이 본질적으로 OOD 작업임을 인식하고 평가—GPT-4o가 상위 4% 후보 중 지면 영감을 포함할 확률이 45.7%에 달하는 놀라운 성능 발견.
- LLM을 "연구 가설 채굴 기계(research hypothesis mines)"로 위치 지음: 세 가지 기본 작업에서의 우수한 성능이 LLM을 대규모 혁신 과학 통찰 자동 생성 도구로서의 가능성을 제시.