Achievement
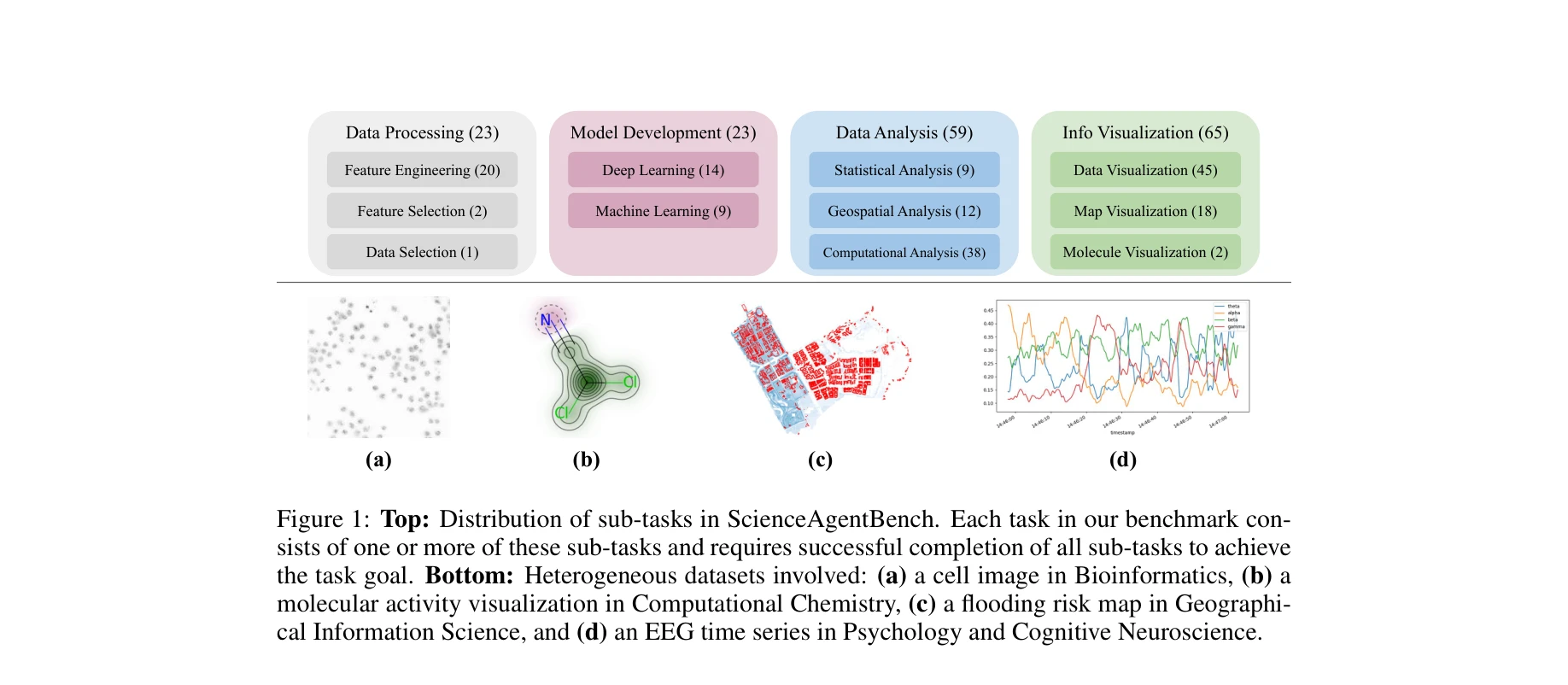
Figure 1: ScienceAgentBench의 세부 작업 분포(상) 및 생물정보학, 계산화학, 지리정보과학, 심리신경과학의 이질적 데이터 유형(하)
- 포괄적 벤치마크 구축: 4개 분야, 44개 논문, 102개 작업으로 구성된 과학적으로 검증된 벤치마크 개발. 각 작업은 피어리뷰 논문의 공개 코드/데이터에서 직접 추출되어 실제 과학 문제의 높은 대표성 확보.
- 엄격한 평가 체계 수립: 생성 프로그램, 실행 결과(렌더링된 그림, 테스트셋 예측), 계산비용을 모두 검토하는 다차원 평가 메트릭과 작업 특화 루브릭 제시. 주석자-전문가 다단계 검증으로 데이터 품질 보증.
- 현실적 성능 평가: 5개 LLM(오픈웨이트/독점)을 3개 프레임워크(직접 프롬프팅, OpenHands CodeAct, 자체 디버깅)로 평가한 결과, 최고 성능 에이전트가 3번의 시도로도 32.4%만 독립적 완수, 전문가 지식 제공 시 34.3% 달성. OpenAI o1은 42.2%이나 비용이 10배 이상 높음.
- 효율성-성능 트레이드오프 분석: Claude-3.5-Sonnet 자체 디버깅이 OpenHands CodeAct 대비 10.8% 더 높은 정확도를 17배 낮은 API 비용으로 달성함을 입증, 실무적 에이전트 설계에 대한 통찰 제공.