Essence
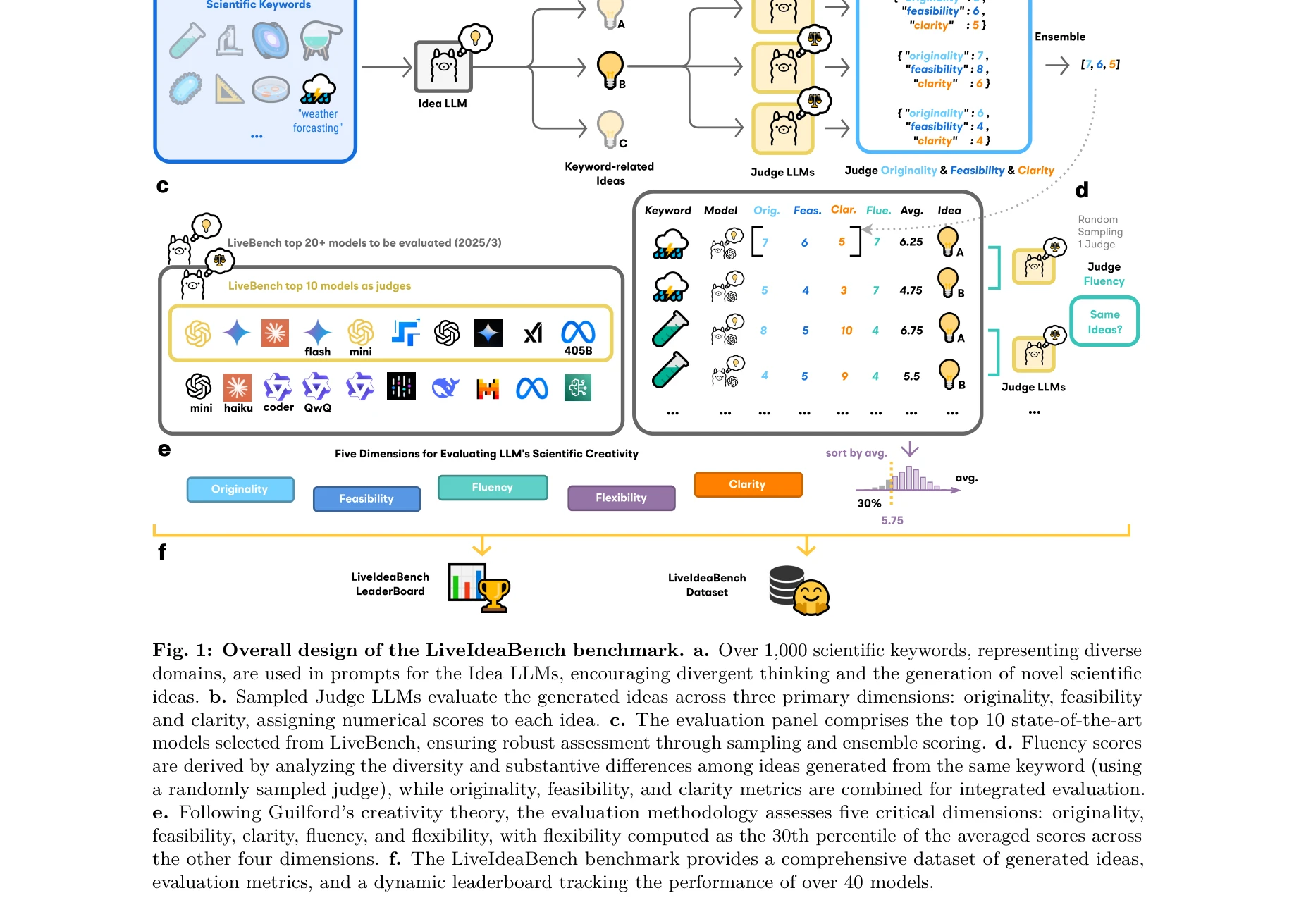
LiveIdeaBench의 전체 설계: (a) 1,000개 이상의 과학 키워드를 사용한 발산적 사고 촉진, (b) 판정 LLM이 5가지 차원으로 평가, (c) 상위 10개 최첨단 모델로 구성된 동적 평가 패널, (d-f) Guilford 창의성 이론 기반 5가지 차원 평가 방법론
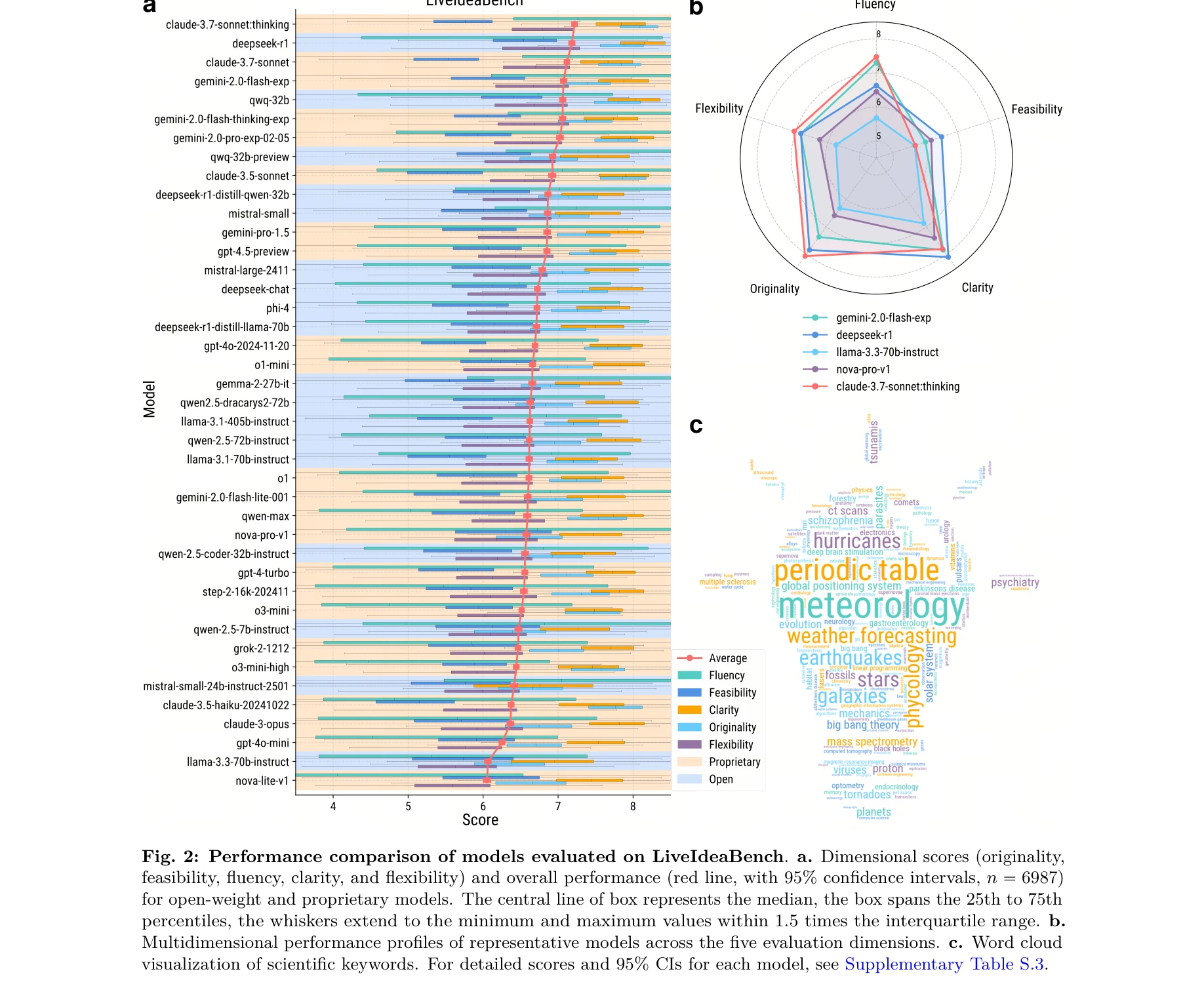
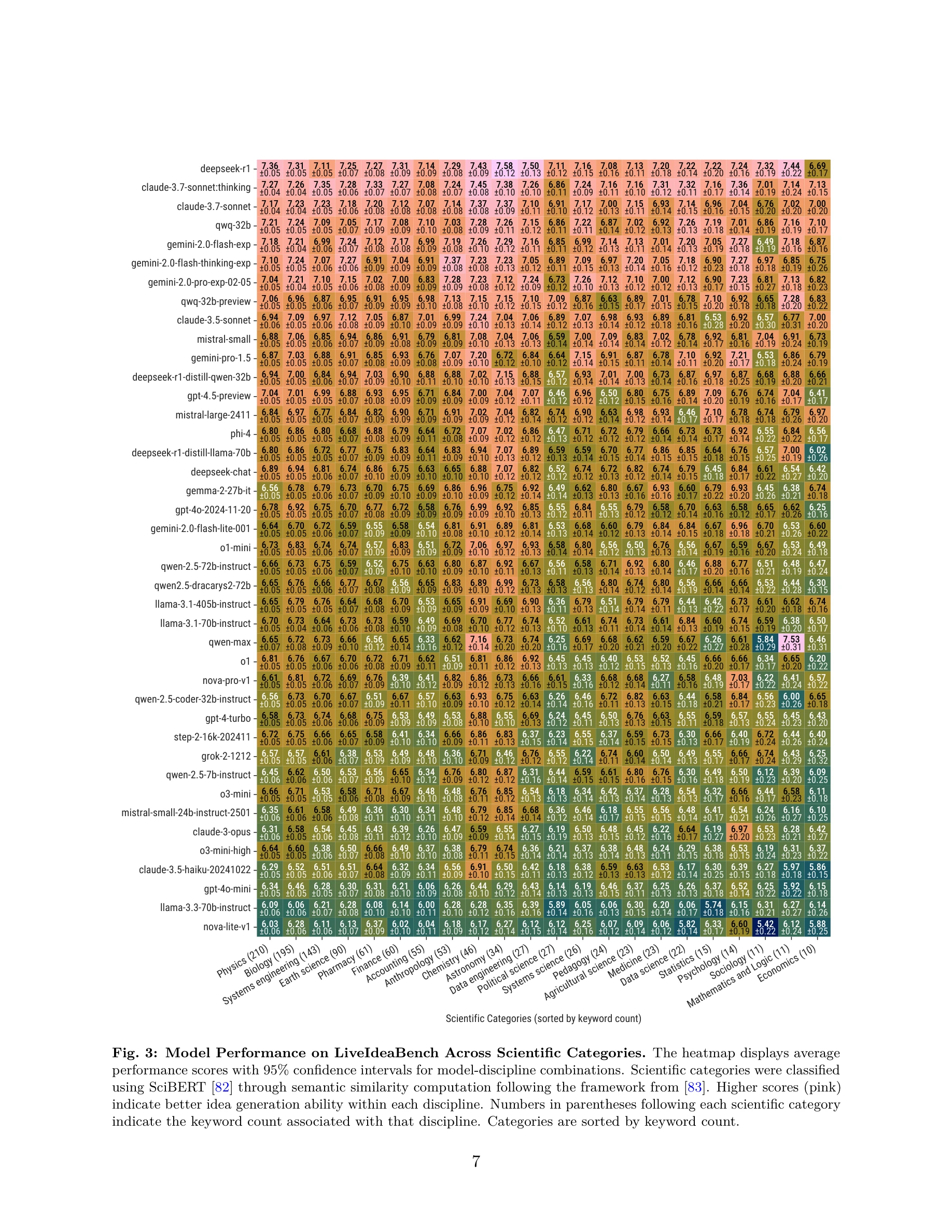
본 논문은 최소한의 맥락(단일 키워드)을 사용하여 대규모 언어모델(LLM)의 과학적 아이디어 생성 능력과 발산적 사고(divergent thinking) 능력을 평가하는 포괄적인 벤치마크 LiveIdeaBench를 제시한다. 40개 이상의 모델을 22개 과학 분야의 1,180개 키워드로 평가한 결과, 과학적 아이디어 생성 능력이 일반 지능 점수로 잘 예측되지 않음을 보여준다.