Achievement
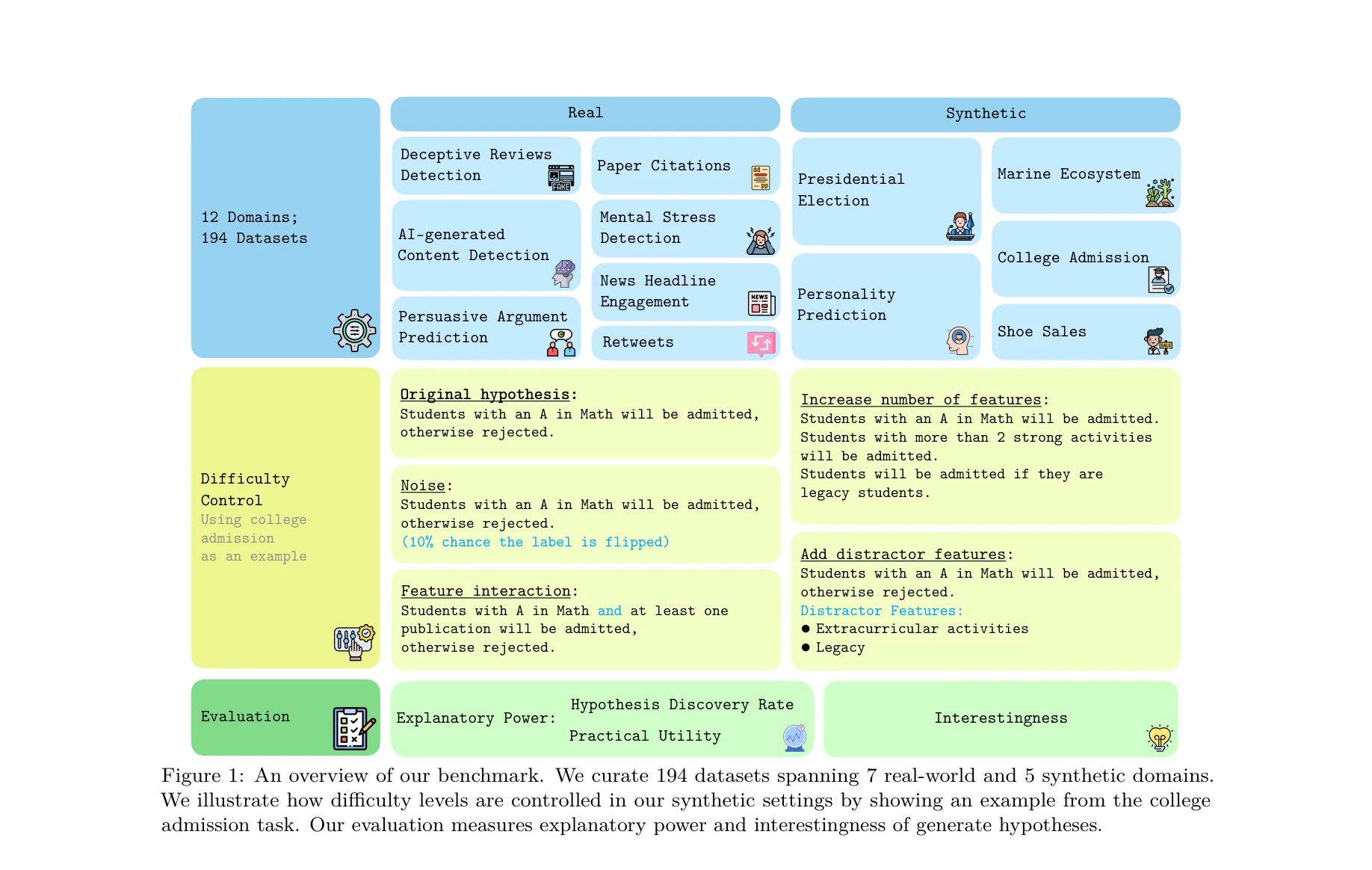
대학 입시 예시를 통해 합성 데이터셋의 난이도 제어 메커니즘을 보여줌: 특성 개수 증가, 노이즈 추가, 특성 상호작용, 방해 특성 추가
- 최초의 체계적 벤치마크 구축: 실제 과제 7개(사기 리뷰 탐지, AI 생성 콘텐츠 식별, 설득력 있는 주장 예측, 정신 스트레스 감지, 뉴스 헤드라인 참여도, 리트윗, 논문 인용)와 합성 과제 5개(대선, 성격 예측, 해양 생태계, 대학 입시, 신발 판매)로 구성된 194개 데이터셋 제공.
- 방법론 비교 분석: 4개 최신 LLM(GPT-4, Claude, Qwen, Llama)과 6개 기존 가설 생성 방법(Zero-shot, Few-shot, Literature-Only, Data-Only, Literature+Data, HypoGeniC)을 종합 평가. 실제 데이터에서는 Literature+Data 방식과 Qwen 모델이 최고 성능.
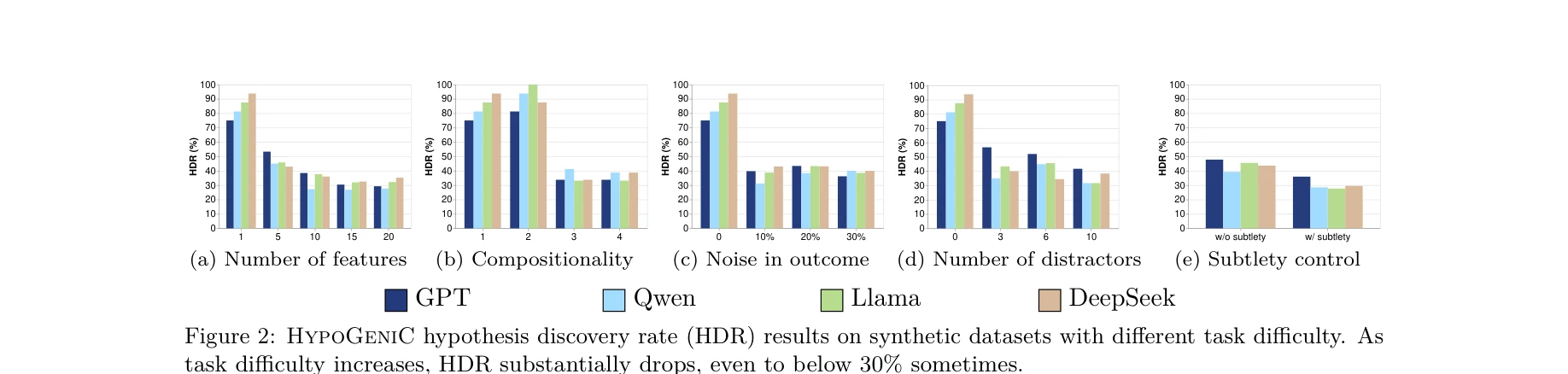
- 난이도 제어를 통한 성능 저하 분석: 기본 합성 과제에서 93.8% 가설 발견율(HDR)을 보이나, 난이도 증가(특성 상호작용, 노이즈 추가, 방해 특성)에 따라 38.8%까지 급격히 저하되어 개선 여지 입증.
- 일반화 능력 평가: 도메인 내(IND)와 도메인 외(OOD) 분할을 통해 발견된 가설의 실제 일반화 능력 측정, 기존 방법들의 플로시빌리티(plausibility)와 참신성(novelty) 간 균형 문제 지적.