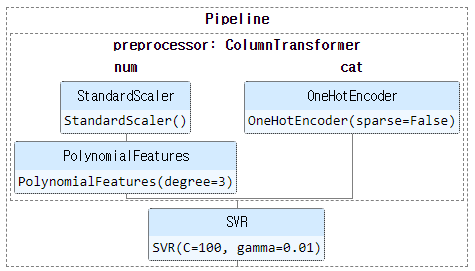
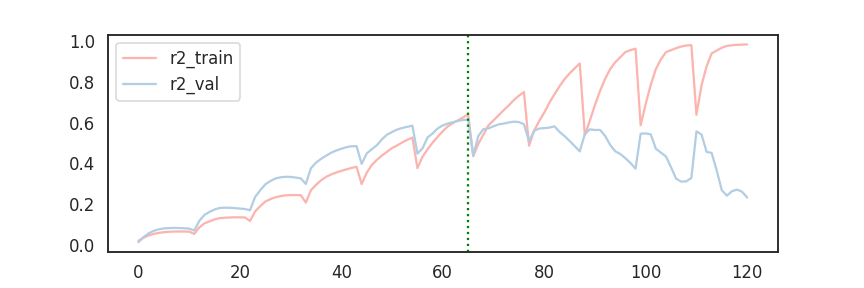
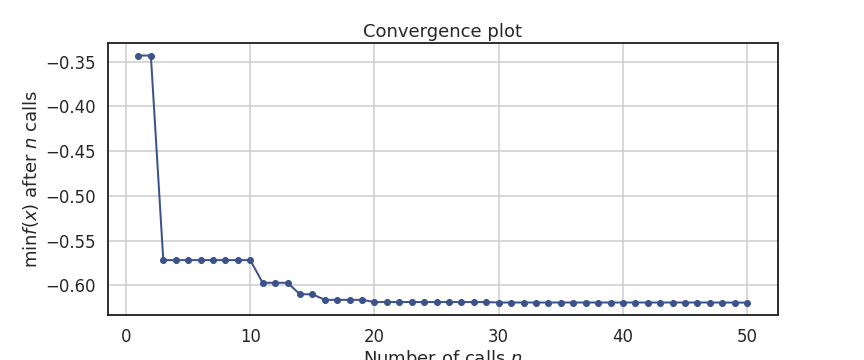
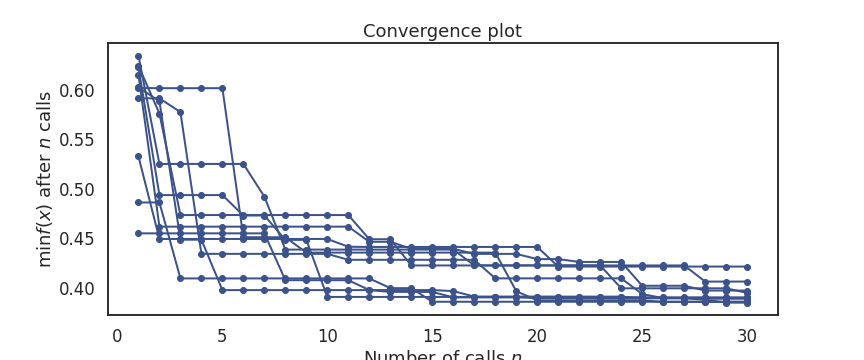
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
|
def plot_parity(true, predict, c="c", mae=None, rmse=None, r2=None,
equal=True, title=None, xlabel="true", ylabel="predict", ax=None):
if not ax:
fig, ax = plt.subplots(figsize=(4, 4))
ax.scatter(true, predict, c=c, s=10, alpha=0.3)
min_ = min(ax.get_xbound()[0], ax.get_ybound()[0])
max_ = max(ax.get_xbound()[1], ax.get_ybound()[1])
ax.set_xlim(min_, max_)
ax.set_ylim(min_, max_)
lb, ub = ax.get_ybound()
ticks =[x for x in ax.get_xticks() if x >= lb and x <= ub]
ax.set_xticks(ticks)
ax.set_xticklabels(ticks)
ax.set_yticks(ticks)
ax.set_yticklabels(ticks)
ax.set_aspect("equal")
ax.grid(axis="both", c="lightgray")
if equal:
ax.plot([lb, ub], [lb, ub], c="k", alpha=0.3)
ax.set_xlabel(xlabel, fontsize=16, labelpad=8)
ax.set_ylabel(ylabel, fontsize=16, labelpad=8)
ax.set_title(title, fontsize=16, pad=8)
if mae:
ax.text(0.95, 0.3, f" MAE ={mae:0.3f}",
transform=ax.transAxes, fontsize=16, ha="right")
if rmse:
ax.text(0.95, 0.22, f"RMSE ={rmse:0.3f}",
transform=ax.transAxes, fontsize=16, ha="right")
if r2:
ax.text(0.95, 0.14, f"R2 ={r2:0.3f}",
transform=ax.transAxes, fontsize=16, ha="right")
return ax
def plot_parities(model, X_train, y_train, X_val=None, y_val=None, X_test=None, y_test=None, title=None, train=False):
vis_val = False
if (X_val is not None) and (y_val is not None):
vis_val = True
vis_test = False
if (X_test is not None) and (y_test is not None):
vis_test = True
if train:
model.fit(X_train, y_train)
y_pred_train, mae_train, rmse_train, r2_train = get_metrics(model, X_train, y_train)
if vis_val:
y_pred_val, mae_val, rmse_val, r2_val = get_metrics(model, X_val, y_val)
if vis_test:
X_trainval = pd.concat([X_train, X_val], axis=0)
y_trainval = pd.concat([y_train, y_val], axis=0)
model.fit(X_trainval, y_trainval)
y_pred_test, mae_test, rmse_test, r2_test = get_metrics(model, X_test, y_test)
ncols = 1
if vis_val:
ncols += 1
if vis_test:
ncols += 1
ax_width = 5
if ncols > 1:
ax_width = 4
fig, axs = plt.subplots(ncols=ncols, figsize=(ax_width*ncols, 5), sharex=True, sharey=True)
if not isinstance(axs, np.ndarray):
axs = [axs]
c_train, c_val, c_test = "g", "c", "m"
axs[0] = plot_parity(y_train, y_pred_train, c=c_train, mae=mae_train, rmse=rmse_train, r2=r2_train,
title="train", ax=axs[0])
mins = [axs[0].get_xbound()[0]]
maxs = [axs[0].get_xbound()[1]]
if vis_val:
axs[1] = plot_parity(y_val, y_pred_val, c=c_val, mae=mae_val, rmse=rmse_val, r2=r2_val,
ylabel=None, title="validation", ax=axs[1])
mins.append(axs[1].get_xbound()[0])
maxs.append(axs[1].get_xbound()[1])
if vis_test:
axs[2] = plot_parity(y_test, y_pred_test, c=c_test, mae=mae_test, rmse=rmse_test, r2=r2_test,
ylabel=None, title="test (train by full trainset)", ax=axs[2])
mins.append(axs[2].get_xbound()[0])
maxs.append(axs[2].get_xbound()[1])
if title:
fig.suptitle(title, fontsize=20, ha="center")
fig.tight_layout()
fig.set_facecolor("w")
if title:
fig.savefig(f"{title.replace('(', '_').replace(')', '_').replace(':', '_')}.png")
|