- 부족한 데이터는 기존 분포를 반영해 만들 수 있습니다.
- 마르코프 체인 몬테카를로(MCMC) 방법의 일종인 깁스 샘플링(Gibbs Sampling)을 사용합시다.
- matplotlib 3.4. 버전에서 추가된
subfigure와subplot_mosaic기능도 실습해보고, - matplotlib을 이용해 3D plot 애니메이션도 만들어 봅니다.
contributor
장령우님: 조건부확률 implementation 관련 조언 제공
배수민님: Gibbs Sampling module 공동 개발
안수빈님: 원본과 Gibbs Sampling 구분 시각화 아이디어 제공
1. Gibbs Sampling
ratsgo’s blog: Gibbs Sampling
Sampling distributions with an emphasis on Gibbs sampling, practicals and code
Gibbs Sampling
- Gibbs Sampling은 기존 데이터의 분포를 재현하는 마르코프 체인 몬테카를로(MCMC: Markov-Chain Monte Carlo)방식의 일환입니다.

-
위 그림처럼 $p(X, Y)$로 표현되는 다변수함수를 모사한다고 합시다.
-
$X$와 $Y$의 상관관계는 조건부 확률 $p(X|Y)$과 $p(Y|X)$로부터 구할 수 있습니다.
- 시작점 $(X_0, Y_0)$을 지정하고,
- $p(X|Y_0)$로부터 다음 데이터의 $X$인 $X_1$을 랜덤으로 추출,
- $p(Y|X_1)$로부터 다음 데이터의 $Y$인 $Y_1$을 랜덤으로 추출합니다.
- 이렇게 구한 $(X_1, Y_1)$로부터 같은 방법으로 $(X_2, Y_2)$를 구한 뒤
- 이 작업을 n번 반복해서 $(X_n, Y_n)$을 구합니다.
- 시작점 $(X_0, Y_0)$을 지정하고,
-
이 작업을 영상으로 표현하면 다음과 같습니다.

-
N차원 데이터라면 $(X_{0,N}, X_{1,N}, X_{2,N}, \ldots , X_{n,N})$에 대해 적용합니다.
-
조건부 확률을 구하기 위해서 확률분포가 수식으로 주어지거나 공분산을 알 수 있으면 좋습니다.
-
하지만 많은 경우 공간상에 흩뿌려져있기 때문에, 이를 해결하고자 맡바닥부터 코딩을 해봤습니다.
-
소스코드는 여기에서 받을 수 있습니다.
-
하지만 아직 충분히 테스트가 이루어지지 않았기 때문에 다운로드를 권하지는 않습니다.
-
정리되면 pypi를 통해 공개하고자 합니다.
2. Discrete Data
- 매개변수 t를 이용해서 불균일한 예제 데이터를 만듭니다.
1 | %matplotlib inline |

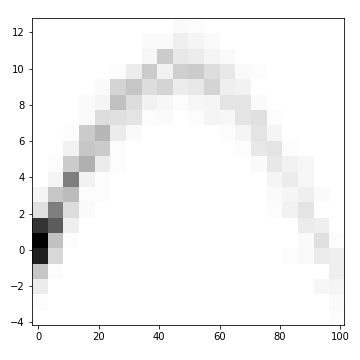
- 데이터가 왼쪽에 몰려있지만 scatter plot으로는 잘 보이지 않습니다.
- matplotlib의
hist2d()명령으로 2D histogram을 그립니다.
1 | fig, ax = plt.subplots(figsize=(5, 5)) |

- 그림 뿐 아니라 히스토그램의 구간과 데이터 수를 구하고 싶다면 이렇게 할 수도 있습니다.
numpy.histogramdd()를 사용해 데이터를 분할하고 이미지를 출력하는imshow()로 그림을 그립니다.- x와 y 범위를 index가 아닌 데이터 값으로 표현하기 위해 extent 매개변수를 사용합니다.
1 | xy_H, xy_edges = np.histogramdd((x, y), bins=20) |
3. matplotlib: Subplot Mosaic
matplotlib tutorials: Complex and semantic figure composition
matplotlib: what’s new in Matplotlib 3.4.0
Pega Devlog: Seaborn with Matplotlib (2)
-
특정 지점에서의 $P(X|Y_0)$와 $P(Y|X_0)$를 도시합니다.
-
seabron의 jointplot과 유사한 그림을 matplotlib으로 그려보겠습니다.
-
기존 기능만 사용해도 그릴 수 있지만 matplotlib 3.4 버전에 새로 도입된
subplot_mosaic()를 사용합니다. -
subplot_mosaic()는 기존 방법과 달리 axes가 dictionary 형식으로 관리되기 때문에 이름으로 부를 수 있습니다. -
단순 나열 데이터가 아닌, 위치별로 기능이 다를때 유용합니다.
-
2차원 리스트로 모양을 잡아주고, empty_sentinel 매개변수로 비울 영역을 지정합니다.
-
원래 있던 기능인 gridspec_kw를 사용하면 크기 비율을 지정할 수 있습니다.
1 | fig = plt.figure(figsize=(5, 5), constrained_layout=True) |

- 히스토그램으로 데이터 밀도가 가장 높은 지점을 찾습니다.
1 | # index |
- 실행 결과:
1 | index of maxmum count: (0, 4) |
- "hist2d"에 2D 히스토그램을 그리고 데이터 밀도가 가장 높은 지점에 가로세로 선을 긋습니다.
- “dist_x”, "dist_y"에 각기 $P(X|Y_0)$와 $P(Y|X_0)$를 히스토그램으로 표현합니다.
1 | fig = plt.figure(figsize=(5, 5), constrained_layout=True) |
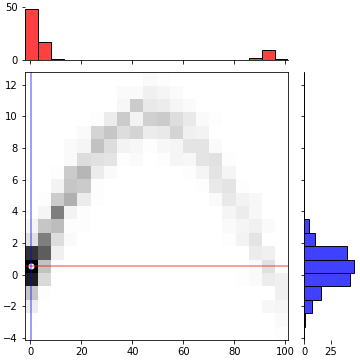
- 이번에 만든 코드에서는 이 지점을 시작으로 Gibbs Sampling을 수행합니다.
- 조건부 확률은 N-Dimensional 히스토그램으로부터 계산합니다.
- Gibbs Sampling 수행 과정은 이 글에서는 생략하겠습니다.
4. Gibbs Sampling for 2-Dimensional Data
- 모듈을 import하고 기본 데이터를 넣습니다.
1 | from gibbs_sampling import GibbsSampling |
- 실행 결과: (2, 10000)의
numpy.ndarray가 생성됩니다.
1 | # type: <class 'numpy.ndarray'> |
5. matplotlib: subfigure
- matplotlib 버전 3.4에서는 figure 속의 figure, subfigure를 지원합니다.
- figure와 axes로 나뉘어 있던 구획에서 figure와 axes 사이에 위치하는 단계입니다.
- axes를 원하는 대로 배치하기 좋고, 특정 구역에만 배경색을 깔기도 좋습니다.
1 | ### figure 생성 |
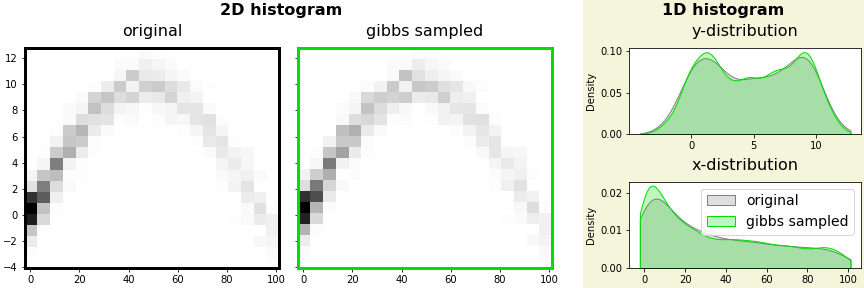
- 한번 저장된 원본 데이터의 정보를 이용해 반복 생성이 가능합니다.
- 생성 데이터 수에 따른 분포를 확인합니다.
1 | fig = plt.figure(figsize=(12, 9), constrained_layout=True) |
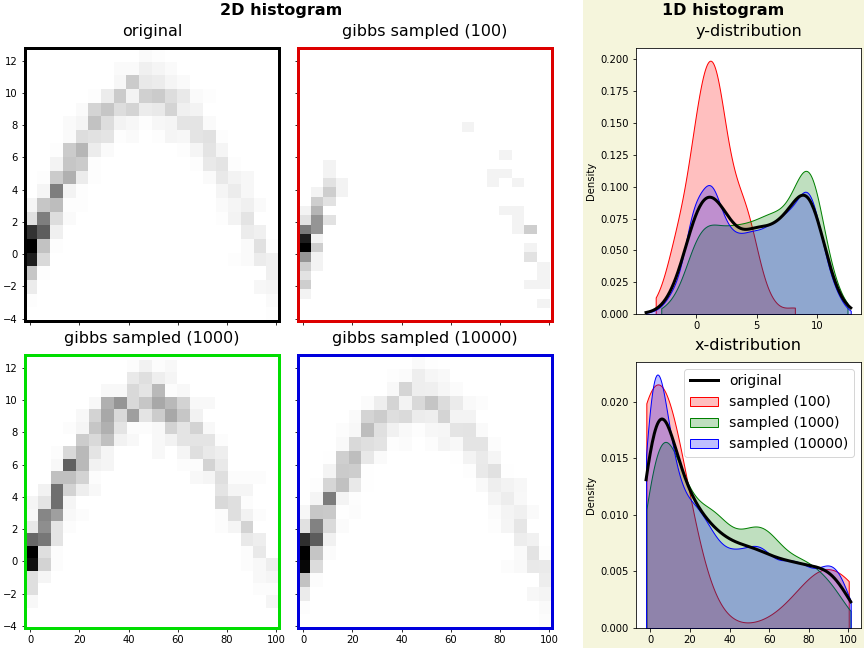
- 원본 데이터는 1000개로 구성되어 있습니다.
- 한참 못미치는 100개는 원본 데이터의 분포와 많이 어긋나는 것을 알 수 있습니다.
- 1000개와 10000개를 생성하면 원본 데이터와 상당히 유사한 분포를 재현할 수 있습니다.
- 하지만 데이터가 많다고 항상 원본에 더 근접한 것은 아니지만 신뢰할만한 수준의 분포를 얻을 수 있었습니다.
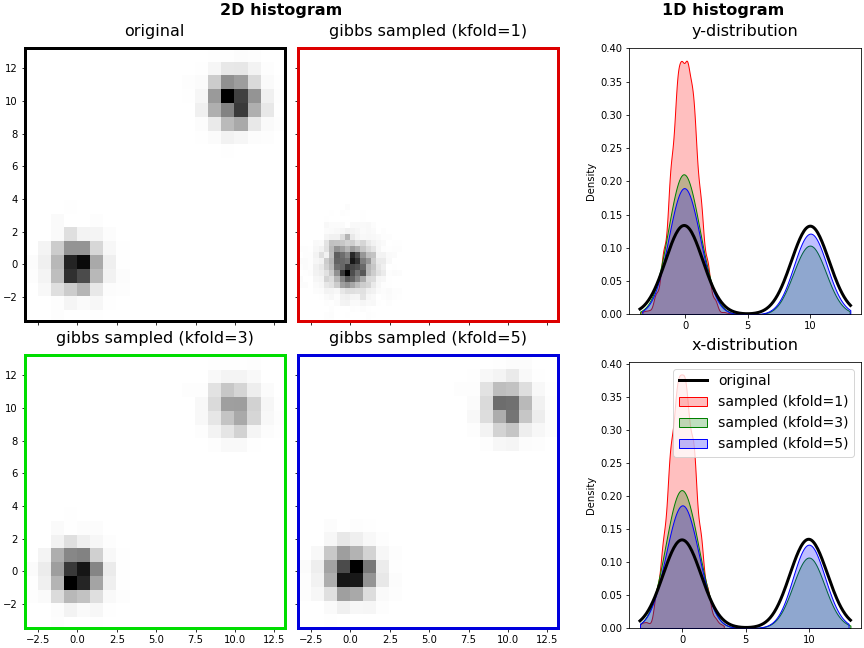
6. Gibbs Sampling의 한계: 분리된 데이터
- Gibbs Sampling은 조건부 확률을 사용해 데이터를 생성합니다.
- 따라서 데이터가 섬처럼 끊겨 있는 경우에는 그 지점을 생성할 수 없습니다.
- 제 코드에서는 이 점을 보완하기 위해 생성할 데이터의 수를 kfold로 나누어 일부를 생성한 뒤,
앞으로 생성해야 할 데이터 기준으로 조건부 확률과 시작점을 업데이트하도록 했습니다.
1 | # 분리 데이터 생성 |

- kfold를 1, 3, 5로 나누어 영향을 확인합니다.
1 | df_sep = pd.DataFrame({"x": sx, "y": sy}) |
- 시각화 코드는 반복이 많아 숨겨둡니다. 클릭하면 펼쳐집니다.
- kfold가 1일 때는 한 그룹의 데이터만 생성된 것을 볼 수 있습니다.
코드 보기/접기
1 | fig = plt.figure(figsize=(12, 9), constrained_layout=True) |
7. 부가 기능
- 활용성을 높이기 위해 몇 가지 부가 기능을 내장하고 있습니다.
7.1. 생성데이터 저장
- 생성된 데이터를
pandas.DataFrame으로 저장할 수 있습니다. .to_df()명령이며, 기본적으로 pickle(.pkl)로 저장하지만 파일 이름에.csv를 명시하면 csv 형식으로 저장됩니다.
1 | gibbs1D = GibbsSampling(10000, x, bins=30) |
- 실행 결과
1 | # (default) exporting as pickle |
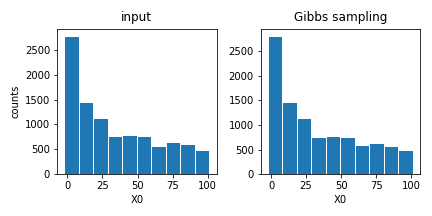
7.2. 데이터 시각화 (1D)
- 원본과 생성된 데이터를 한 눈에 보는 기능을 제공합니다.
plot()을 사용합니다. filename 매개변수를 사용하면 저장도 됩니다.- 1D data로 간단히 확인해보겠습니다.
1 | gibbs1D.plot(filename="gibbs1D_plot.png") |

7.3. 파일 입력
- 데이터 파일로부터 직접 데이터를 생성할 수 있습니다.
- GibbsSampling() 명령의 데이터 자리에 파일명을 대신 넣으면 됩니다.
- 방금 저장한 데이터를 읽어서 10개의 구간으로 샘플링한 후 함께 그려보겠습니다.
1 | gibbs1D_2nd = GibbsSampling(10000, "gibbs1D.pkl", bins=10) |
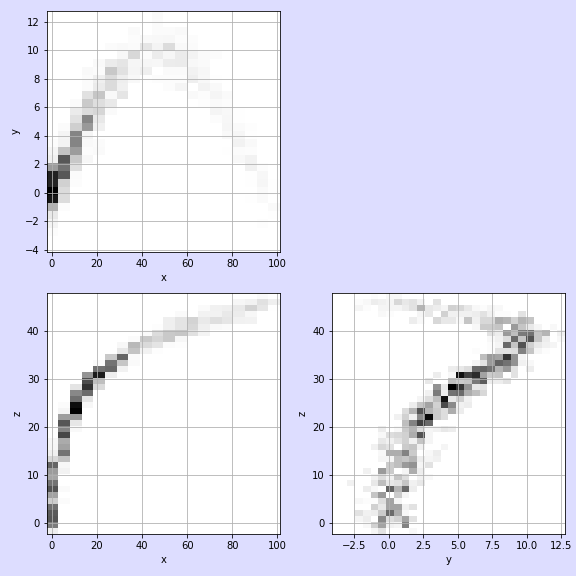
7.4. N-Dimensional Gibbs Sampling 시각화
- 1차원 데이터는 좌우에 나란히 보여주기 좋지만, 차원이 커지면 시각화가 어려워집니다.
- 이런 점을 보완하기 위해 2차원 이상의 시각화는 2D 히스토그램을 여럿 활용합니다.
ori=True를 하면 원본 데이터가, False(기본값)로 놓으면 생성된 데이터가 그려집니다.
1 | # 3차원 데이터를 만들고 |

- 생성 데이터도 그려봅니다.
- GibbsSampling의
plot()메소드는 fig를 return 하기 때문에 추가 처리도 가능합니다.
1 | fig = gibbs_3d.plot(cmap="Greys", figsize=(8, 8), org=False, filename="69_gs_10.png") |
8. Matplotlib: 3D Rotation Animation
-
3차원 공간을 2차원에 표현하는데는 한계가 있습니다.
-
3차원으로 그려도 시선 방향으로 정사영(projection)한 그림밖에 보이지 않습니다.
-
이럴 때 interactive와 함께 좋은 방법은 그림을 빙빙 돌리며 애니메이션으로 보는 것입니다.
-
matplotlib의
FuncAnimation을 활용합니다. -
사용자 정의한
animate()함수 안에 frame마다 달라지는 그림을 iteration 매개변수 i를 사용해 그립니다. -
return 값에 쉼표(,)를 붙여서 tuple 형태로 바꿔줘야 한다는 점을 주의해야 합니다.
1 | from matplotlib import animation |

- 코드는 버그를 확인하고 완성도를 높여 추후 공개하겠습니다.
