- 데이터 시각화는 머신러닝 과정을 확인하기 좋습니다.
- 하이퍼파라미터에 따라 확인할 값이 여럿 있고,
- 숫자로 확인할 수도 있지만 눈에 잘 들어오지 않아 그림으로 표현해 보았습니다.
1. 데이터 & 분석 설정
- 필요한 라이브러리들을 불러옵니다.
- 업데이트된 matplotlib 버전 3.4.1을 사용합니다.
- 새로 생긴 기능을 사용해 볼 것입니다.
1 | %matplotlib inline |
- 실행 결과 :
1 | '3.4.1' |
-
현업 데이터를 가져왔습니다.
-
범주형 2개, 수치형 3개, 400줄짜리 단촐한 데이터입니다.
-
수치형 변수를 맞추는 regression 문제입니다.
-
train : test = 8 : 2로 분리합니다.
-
제겐 굳이 index를 뽑아서 분리하는 버릇이 있습니다.
-
여차할 때 확인해보기 좋습니다.
1 | df_vcv = pd.read_csv("df_vcv.csv") |
2. 데이터 분포 확인
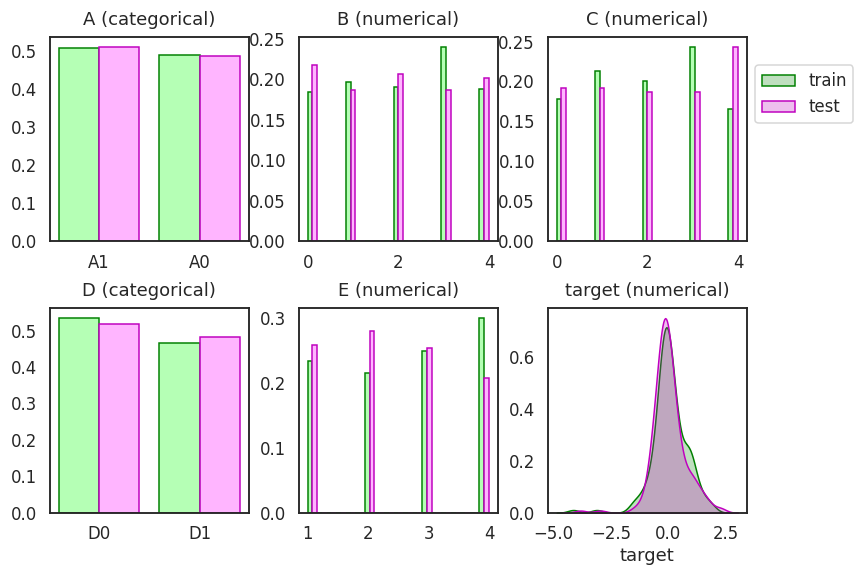
- 쪼갠 trainset, testset을 확인합니다.
- 데이터 분포를 비율로 그려서 trainset과 testset이 비슷한지 봅니다.
- train을 green, test를 magenta로 나란히 그려서 비교합니다.
코드 보기/접기
1 | fig, axes = plt.subplots(ncols=3, nrows=2, figsize=(12, 8)) |
3. Machine Learning
- 데이터 전처리와 선형회귀에 필요한 라이브러리를 불러옵니다.
1 | # encoder |
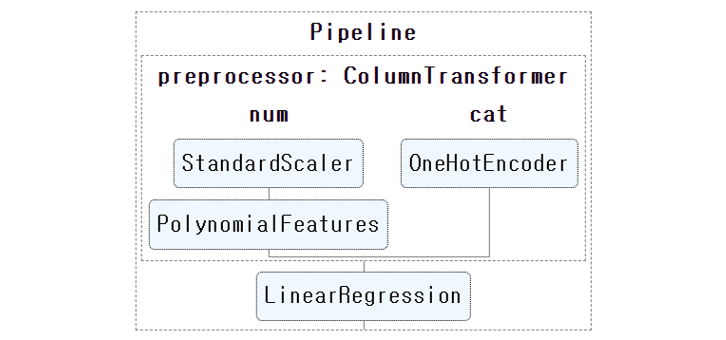
3.1. Pipeline 구축
-
scaler와 one-hot encoder 등을 수행하며 데이터가 바뀌는 과정을 바라볼 수 있습니다.
-
변환이 눈과 손에 익지 않았을 때는 유용한 방법이지만 깊이 분석하기엔 한계가 있습니다.
-
예를 들어 feature importance를 도출할 때, one-hot encoding이 수행된 범주형 인자는 원소 하나하나에 대한 중요도가 나와버려 정작 인자의 중요도를 구하기 어렵습니다.
-
체계적으로 분석할 수 있도록 pipeline을 구축합시다.
-
범주형 데이터와 수치형 데이터에 다른 전처리를 수행합니다.
-
sklearn의
set_config(display='diagram')을 이용하면 그림으로 볼 수 있습니다.
코드 보기/접기
1 | # linear regression model |
set_config(display='text')를 통해 출력 모드를 바꿀 수 있습니다.
1 | set_config(display='text') |
- 실행 결과
1 | Pipeline(steps=[('preprocessor', |
3.2. 평가: metrics
- 파이프라인으로 구축한 머신러닝 모델의 성능을 평가합니다.
- 평가 지표로는 MAE(mean absolute error), RMSE(root mean squared error), R2(coefficient of determination)를 사용합니다.
- 모델과 데이터를 넣으면 예측결과와 평가지표를 뽑아주는 함수를 만듭니다.
코드 보기/접기
1 | # evaluation metrics |
- 실행 결과:
1 | # train dataset |
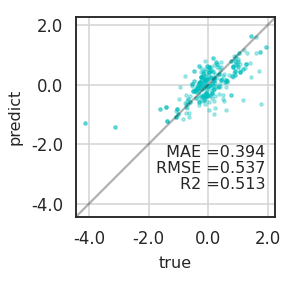
3.3. Visualization: Parity Plot
-
머신러닝 모델의 예측력은 평가 지표와 같은 수치로 도출되지만 충분하지 않습니다.
-
어떤 부분이 잘 맞고 어디가 틀린지 확인해야 보완할 수 있습니다.
-
데이터 시각화를 통해 확인해 봅시다.
-
참값과 예측값을 비교하는 방법으로 parity plot을 흔히 사용합니다.
-
참값과 예측값이 $$y = x$$에 가까울 수록 좋습니다.
-
x와 y축 범위를 일치시켜 그립니다.
-
return ax로 axes를 받을 수 있도록 설계합니다.
코드 보기/접기
1 | def plot_parity(true, predict, c="c", mae=None, rmse=None, r2=None, equal=False, |
1 | ax = plot_parity(y_train, y_pred_train, mae=mae_train, rmse=rmse_train, r2=r2_train, equal=True) |
3.4. Visualization: Parity Plots
- train data와 test 데이터를 함께 그리려고 합니다.
- 방금 만든
plot_parity()함수를 두 번 사용합니다.
코드 보기/접기
1 | def plot_parities(X_train, X_test, y_train, y_test, title): |
1 | plot_parities(X_train, X_test, y_train, y_test, "linear regression (degree=3)") |
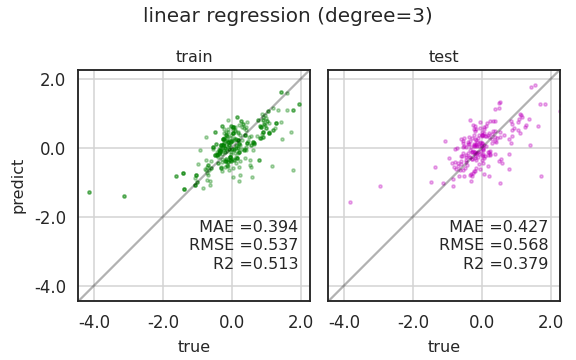
- train, test 결과가 모두 마음에 들지 않습니다.
- 선형회귀 차수를 바꿔서 확인합시다.
- 먼저, 1차 함수를 시도해 봅니다.
코드 보기/접기
1 | model = linear(1) |
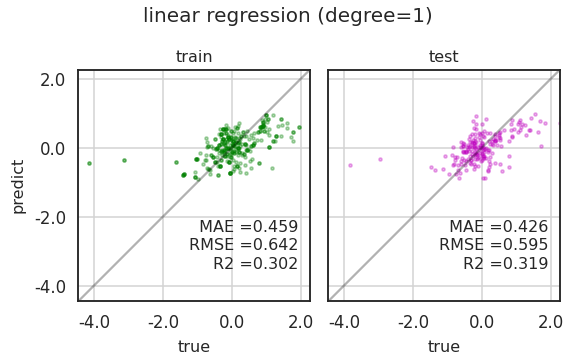
- 역시 별로입니다.
- 이번에는 5차 함수를 시도합니다.
코드 보기/접기
1 | model = linear(5) |
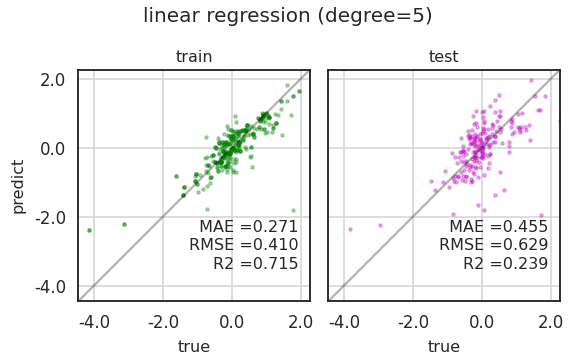
- 1, 3, 5차 모두 마음에 들지 않습니다.
- 차수에 대한 경향을 보면 답에 가까워질 것 같습니다.
- Grid Search를 사용하면 좋을 것 같습니다.
3.5. Grid Search: polynomial order
- sklearn에서 제공하는 GridSearchCV는 다음에 씁시다.
- 변수가 하나뿐이니 수동으로 바꾸어가면서 성능을 평가합니다.
코드 보기/접기
1 | def plot_metrics(X_train, X_test, y_train, y_test, title): |
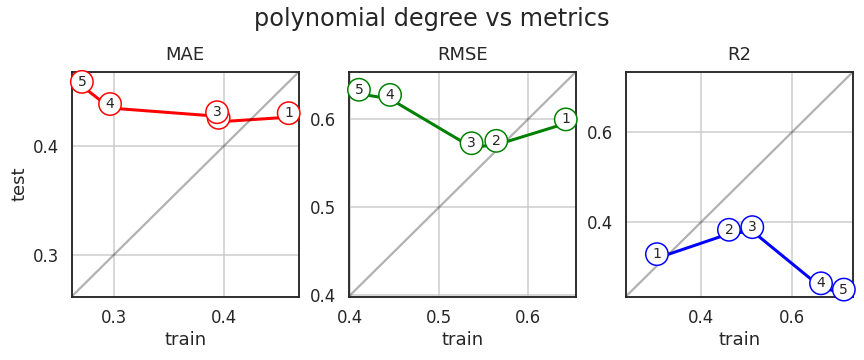
-
가로축은 trainset, 세로축은 testset입니다.
-
차수가 거듭될수록 MAE와 RMSE, R2 모두 overfitting이 관찰됩니다.
-
1차나 2차를 고르면 되나 싶지만, 한번 더 확인합시다.
-
train과 test 데이터 분할을 다시 해서 확인합니다.
-
split에 사용된 numpy random seed를 교체해서 데이터를 다시 만들고 똑같이 진행합니다.
코드 보기/접기
1 | np.random.seed(0) |
1 | plot_metrics(X_train_2, X_test_2, y_train_2, y_test_2, "polynomial degree vs metrics (2)") |
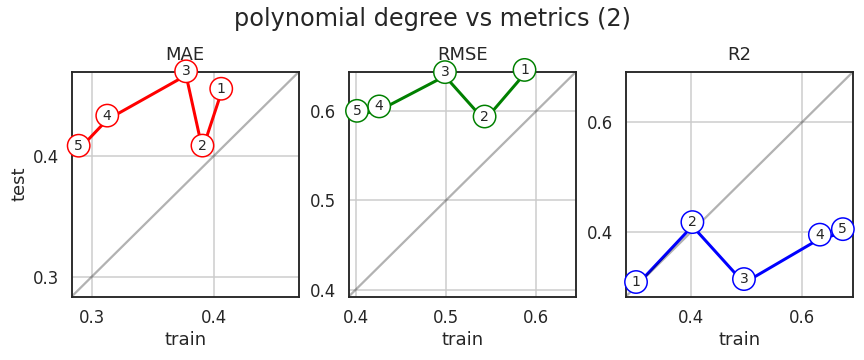
- 1차보다 2차가 $$y = x$$에 가깝습니다.
- 그런데 그게 문제가 아닐 것 같습니다. 거동이 완전히 바뀌었습니다.
- 데이터에 따른 편차가 상당히 큽니다.
3.6. Grid Search Cross Validation: polynomial order
-
그런데 하나 잊은 것이 있습니다.
-
test data는 최종 검증용으로만 사용해야지, 이렇게 성능을 테스트셋에 맞추면 결국 테스트셋에 오버피팅될 뿐입니다.
-
이건 안봤다고 치고 덮어놓고, train data만 가지고 최적을 찾아봅시다.
-
Grid Search + Cross Validation이 필요합니다.
-
다항식의 차수만 바꾸면서 각각의
cross validataion score를 측정합니다. -
cv=5로 다섯 번 수행한 교차검증의 평균과 표준편차를 구합니다. -
성능이 좋으려면 평균이 높아야 하고, 표준편차는 작아야 합니다.
-
교차검증을 신뢰하려면 적어도 표준편차라도 작아야 합니다.
-
과연 그럴지 확인합니다.
코드 보기/접기
1 | def plot_cv(X_train, y_train, title): |
- Grid Search 결과를 곧장 그려봅니다.
1 | plot_cv(X_train, y_train, "polynomial order vs metrics (cross validation)") |
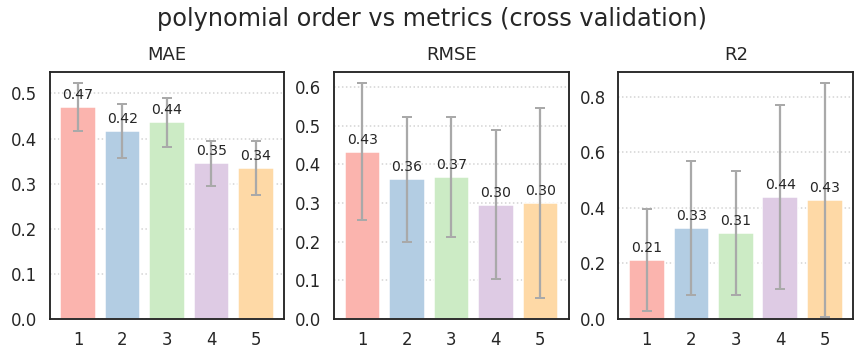
- 바꾸었던 데이터를 적용해 봅니다.
1 | plot_cv(X_train, y_train, "polynomial order vs metrics 2 (cross validation)") |
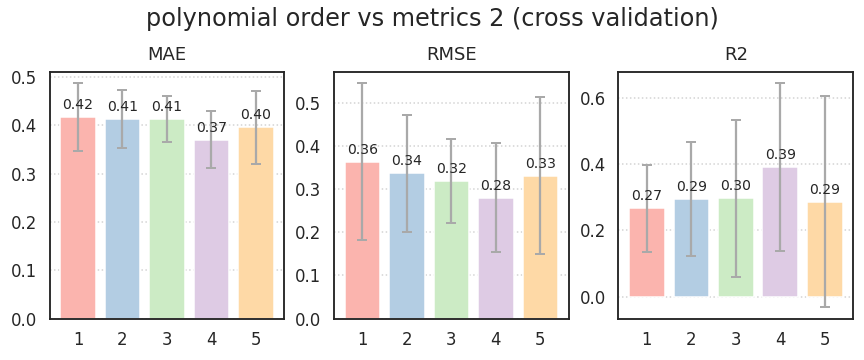
-
두 경우 모두, 결과를 신뢰하기에는 RMSE와 R2의 표준편차가 너무나 큽니다.
-
특히 MAE보다 RMSE의 표준편차가 크다는 점에서 이상치의 역할이 큼을 짐작할 수 있습니다.
-
5차에서는 $$R^2 < 0$$ 마저 등장하는데, 모든 범위에서 선형 회귀가 힘을 쓰지 못합니다.
-
선형 회귀가 엉망이라는 점에서 비선형성이 매우 강하다는 추측을 할 수 있습니다.
-
다음 글에서는 비선형 회귀에 도전하겠습니다.
