- Gaussian Process 연습입니다.
- scikit-learn을 비롯한 예제를 재구성하여 연습합니다.
- 주의사항을 알려드립니다. Gaussian Process는 경계조건에 매우 취약합니다.
1. Gaussian Process의 한계
scikit-learn: Gaussian Process Regression: basic introductory example
-
Gaussian Process는 적은 데이터로도 꽤 믿을만한 결과를 출력합니다.
-
심지어 신뢰 구간까지 알 수 있어서 매우 정직해 보입니다.
-
하지만 치명적인 단점이 있습니다.
-
지난 글과 같은 예제를 사용합니다.

-
모든 것이 정상으로 보입니다.
-
합리적인 범위의 평균값(
GP prediction (mean))과 신뢰 구간(95% CI)을 보이고 있습니다. -
하지만 오른쪽 끄트머리를 보면, 조금 미심쩍습니다.
-
참값이 신뢰 구간의 바닥에 겨우 걸려있습니다.

-
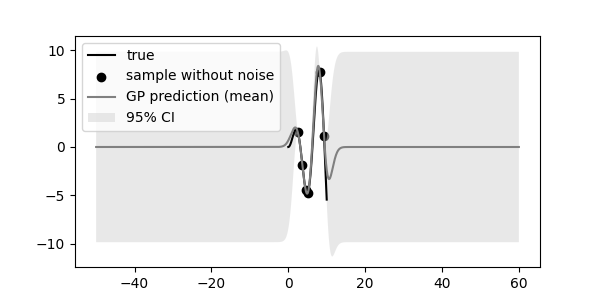
극단적인 경우를 살펴봅니다.
-
X 값의 범위로 참값의 좌우에 50씩을 보태 -50 ~ 60을 입력합니다.
-
평균이 0, 95% 신뢰구간이 무려 10에 가까운 커다란 밴드가 생겼습니다.
-
다항회귀를 해도 이렇지는 않을 것 같습니다.
-
Gaussian Process의 원리에 답이 있습니다.
-
Gaussian 분포를 prior로 놓기 때문에 평균이 0입니다.
-
학습 데이터(evidence)가 반영된 구간 안쪽은 그나마 괜찮지만 바깥쪽이 문제입니다.
-
안쪽에서 학습을 시켜봐야 바깥쪽의 중심값이 0이라고 가정되어 있기 때문에 저런 일이 벌어집니다.
2. 비교
-
조금 더 확실하게 확인합니다.
-
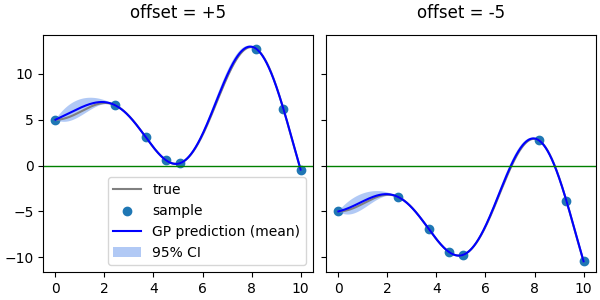
위의 예제에 offset = $\pm 5$를 해서 새로운 참값을 만듭니다.
-
그리고, 여기서 같은 X 좌표의 데이터들을 학습용으로 추출합니다.

-
여기에 똑같은 RBF 커널을 적용한 Gaussian Process를 적용하면 아래와 같은 결과가 나옵니다.
-
좌우 그림에서 파란 선으로 표시한 평균값의 양 끝이 향하는 방향이 반대입니다.
-
offset=+5인 왼쪽 그림은 양 끝이 아래를 향하고 있고,
-
offset=-5인 오른쪽 그림은 양 끝이 기를 쓰고 고개를 들려고 하고 있습니다.
-
모두 0을 향하고 있습니다.

-
양 끝만 영향을 받는 것이 아닙니다.
-
X = 6~8 사이 구간도 offset에 따라 달라집니다.
-
0에서 먼 왼쪽 그림은 신뢰 구간이 비교적 얇은 반면 오른쪽은 두텁고 mean 값도 참값과 더 벌어져 있습니다.
3. Solution
- 해결 방법은 생각보다 간단합니다.
- 외삽(extrapolation)이 문제라면 외삽을 하지 않으면 됩니다.
- 학습 데이터에 데이터 범위의 양 끝을 추가하면 모든 범위가 내삽이 됩니다.
1 | # sample including ends |
- 그리고 같은 학습을 시키면 offset에 관계 없이 동일한 결과를 얻을 수 있습니다.
1 | kernel = 1*RBF(length_scale=1.0, length_scale_bounds=(1e-2, 1e2)) |
4. 결론
- 머신 러닝 기법들이 모두 그렇지만 외삽은 주의해야 합니다.
- Gaussian Process는 prior의 존재로 인해 외삽에 더 취약할 수 있으니 각별히 주의해야 합니다.
- 본 글에 사용된 코드는 여기에서 다운받으실 수 있습니다.
