- Gaussian Process 연습입니다.
- scikit-learn을 비롯한 예제를 재구성하여 연습합니다.
- 오차가 없을 때와 있을 때를 비교합니다.
1. Data Preparation
scikit-learn: Gaussian Process Regression: basic introductory example
1.1. example data
- Gaussian Process 연습을 위한 데이터를 준비합니다.
- scikit-learn의 예제를 일부 변형합니다.
- 1000개로 이루어진 매끈한 곡선을 만듭니다.
- 이번 글에서는 랜덤 함수를 많이 사용합니다. random number generator를 정의해 재현성을 확보합니다.
1 | %matplotlib inline |
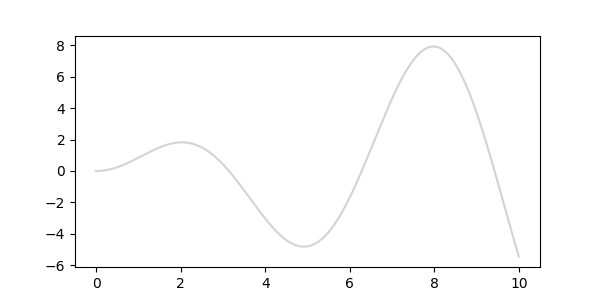
- 지금 그린 그래프는 우리가 Gaussian Process로 찾아야 할 참값입니다.
1.2. 6 training points
- 임의의 x 좌표 6개를 골라 예제 데이터를 뽑습니다. 측정값(evidence)이라 볼 수 있습니다.
- 두 가지 상황을 가정해 이 지점들로 참값 곡선을 찾아갈 것입니다.
- ① 측정을 하면 정확한 값을 찾아내는 경우: 딱 6개만 뽑으면 됩니다.
- ② 측정이 불확실성을 안고 있는 경우: x 하나당 10번씩 측정했다고 하겠습니다. 표준 편차 = 1입니다.
1 | training_indices = rng.choice(np.arange(y.size), size=6, replace=False) |
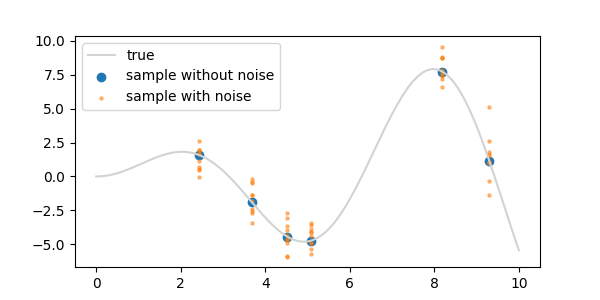
2. Gaussian Process
2.1. Without Noise
scikit-learn: Radial basis function kernel
The Gradient: Gaussian Process, not quite for dummies
- evidence가 참값인 경우의 Gaussian Process를 실행합니다.
- 커널에는 Radial Bassis Function 커널을 사용합니다.
- length_scale 초기값은 1, 범위는 0.01부터 100 안에서 fitting합니다.
1 | from sklearn.gaussian_process import GaussianProcessRegressor |
- 실행 결과
1 | 5.02**2 * RBF(length_scale=1.43) |
-
fitting 결과 1로 지정했던 계수와
length_scale이 변경되었습니다. -
계수는 신뢰구간의 폭,
length_scale은 곡선의 매끈함(smoothness)에 해당합니다.
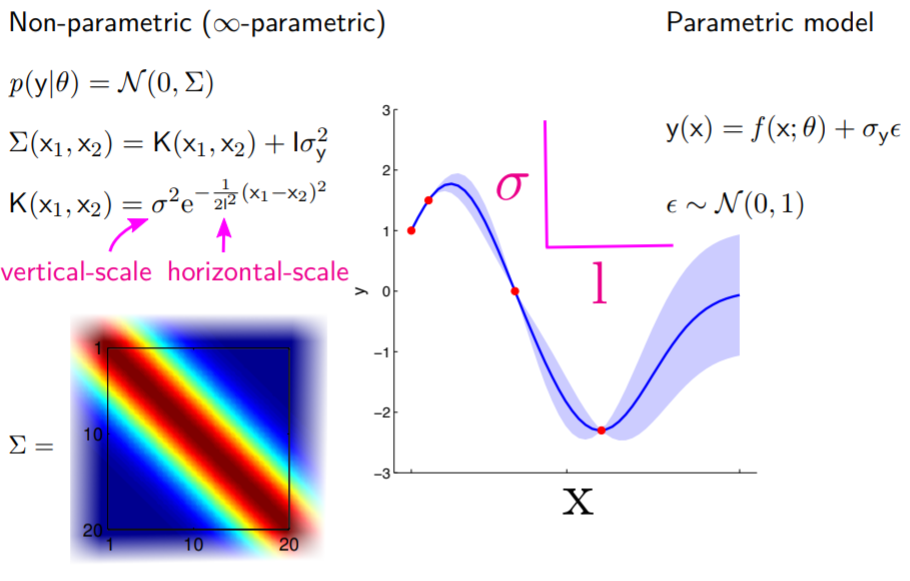
-
다음 명령으로 추가 정보를 얻을 수 있습니다.
1 | gpr.kernel_.theta |
- 실행 결과
1 | array([3.22768806, 0.36021977]) |
gpr.kernel_theta는(flattened, log-transformed) non-fixed hyperparameters입니다.- 전체 X를 넣고 Gaussian Process 결과를 그림으로 확인합니다.
1 | # prediction |
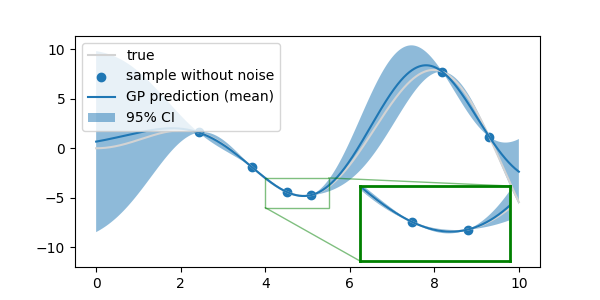
- 확대를 해도 측정값은 신뢰구간의 폭이 0임을 확인할 수 있습니다.
- 측정된 데이터를 참값으로 가정했으므로 측정값의 분산은 0입니다.
2.2. With Noise
- 이번에는 측정 데이터에 오차가 포함된 경우를 살펴봅니다.
- 오차가 있는 데이터는
GaussianProcessRegressor()에 측정 오차를 의미하는 매개변수alpha를 추가해야 합니다. - 수식에서는 커널 행렬의 대각 요소에 추가되는 값으로 fitting시 발생하는 numerical issue를 예방합니다.
2.2.1. 오차 데이터 직접 입력
- 아까와 동일하게 Gaussian Process fitting을 수행합니다.
1 | kernel = 1*RBF(length_scale=1.0, length_scale_bounds=(1e-2, 1e2)) |
- 실행 결과
1 | 4.92**2 * RBF(length_scale=1.37) |
- 아까와는 다른 값으로 수렴했습니다.
- 다시 전체 X를 넣고 예측 결과를 확인합니다.
- 참값은 입력하지 않았지만 대조를 위해 함께 도시합니다.
1 | # prediction |
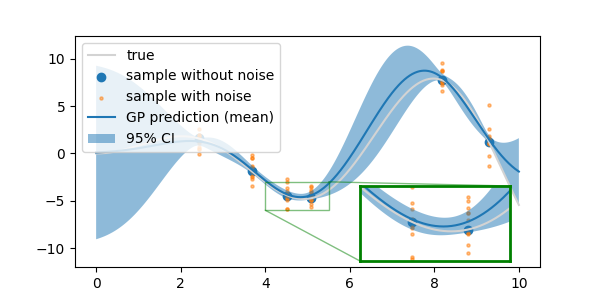
- 데이터를 확보한 곳에서도 불확실성에 의해 신뢰구간이 한 점으로 수렴하지 않습니다.
- 아울러 전체의 평균값도 참값에서 조금씩 어긋나 있음을 확인할 수 있습니다.
2.2.2. 오차 분산 입력
- 이번에는 모든 데이터를 입력하는 대신 참값데이터와 함께 분산을 입력합니다.
- 앞서 noise를 만들 때 표준 편차 = 1을 입력했는데 정말 그런지 확인합니다.
1 | import pandas as pd |
- 실행 결과
1 | 1.0616168585081918 |
- 의도한 바와 같이 데이터의 평균 분산은 1과 유사한 값으로 나왔습니다.
- 애초에 의도한 값 1을 제곱하여
alpha에 입력하고 Gaussian Process를 진행합니다. - 계수가 아까보다 작게 나왔습니다.
1 | kernel = 1*RBF(length_scale=1.0, length_scale_bounds=(1e-2, 1e2)) |
- 실행 결과
1 | 4.39**2 * RBF(length_scale=1.16) |
- 같은 코드로 그림을 그려 확인합니다.
- 줄어든 계수가 무색하게 전체적으로 신뢰구간이 더 넓은 듯한 느낌입니다.
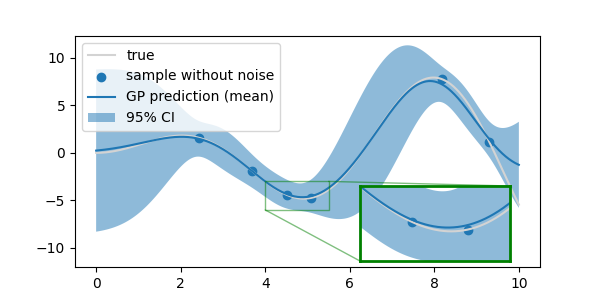
2.2.3. alpha가 같을 때 데이터 수에 따른 비교
- noisy data를 직접 입력했을 때와 모양이 달라진 것이 데이터에 무관한, alpha에 따른 차이가 아닐까 의구심이 듭니다.
alpha=1로 설정하고 noisy data로 학습시킨 후 양상을 확인합니다.
1 | kernel = 1*RBF(length_scale=1.0, length_scale_bounds=(1e-2, 1e2)) |
- 실행 결과
1 | 4.84**2 * RBF(length_scale=1.34) |
- 값이 조금 다르기는 하지만 noisy data를 입력했을 때에 가깝습니다.
- 그래프 모양을 보면 더 확연하게 드러납니다.
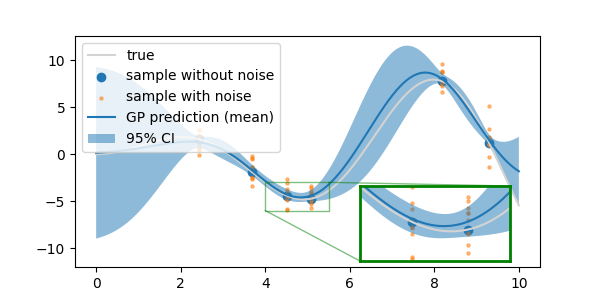
2.2.4. 커널 parameter 범위에 따른 결과
- 앞서 kernel을 다음과 같이 정의했습니다.
1 | kernel = 1*RBF(length_scale=1.0, length_scale_bounds=(1e-2, 1e2)) |
- RBF kernel의 length scale이 가질 수 있는 범위를 0.01 ~ 100으로 지정한 것입니다.
- 그리고 결과적으로 입력된 데이터에 의해
length scale = 1.16로 결정되었습니다. - 그런데 초기값의 범위가 이 밖에 있으면 전혀 다른 결과가 얻어집니다.
- 먼저, length scale이 너무 클 때입니다.
1 | kernel = 1*RBF(length_scale=100, length_scale_bounds=(10, 1e3)) |
-
초기값을 100, 범위를 10~1000으로 잡으면 결과적으로
316**2 * RBF(length_scale=10)에 수렴합니다. -
이 때 결과는 다음과 같습니다.
-
지나친 과소적합(underfitting)으로 인해 x=0 부근에서 참값을 따라가지 못하고 평균값이 40 가까이 발산해 버렸습니다.
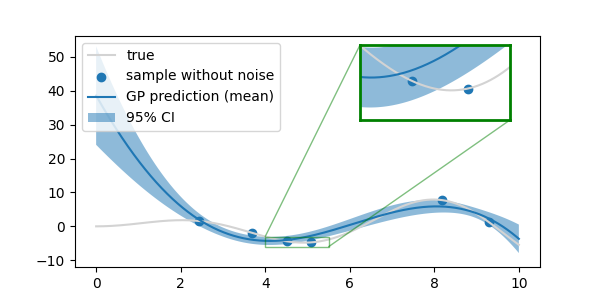
-
이번에는 거꾸로 kernel의 length_scale이 너무 작은 경우입니다.
1 | kernel = 1*RBF(length_scale=0.01, length_scale_bounds=(1e-4, 1e-1)) |
- 학습 결과 kernel이
4.16**2 * RBF(length_scale=0.01)로, length scale이 입력된 범위의 최대값에 닿았습니다. - 결과적으로 과대적합(overfitting)이라고 불러야 할지 애매하지만 측정값 외에는 미동도 하지 않았습니다.
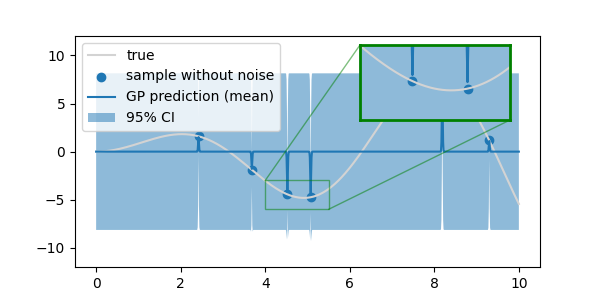
3. 결론
- Gaussian Process는 적은 데이터로 오차를 포함한 결과를 효과적으로 추론합니다.
- 그러나 커널의 제약에 민감하기 때문에 주의깊게 살펴볼 필요가 있습니다.
