-
PyTorch는 현재 가장 인기있는 딥러닝 라이브러리 중 하나입니다.
-
학습 세부 사항을 지정하기 위해 Callback으로 다양한 기능을 지원합니다.
-
skorch는 PyTorch를 scikit-learn과 함께 사용할 수 있게 해 줍니다.
-
skorch도 PyTorch callback을 이용할 수 있습니다.
-
글이 길어 세 개로 나눕니다.
-
두 번째로, scikit-learn을 사용해 전처리 파이프라인을 구성하고
-
PyTorch neural network를 만들어 여기에서 나온 결과물을 학습시킵니다.
3. Neural Network
3.1. PyTorch
3.1.1. network and loss
- skorch는 scikit-learn Pipeline 안에 PyTorch Neural Network를 담을 수 있게 해줍니다.
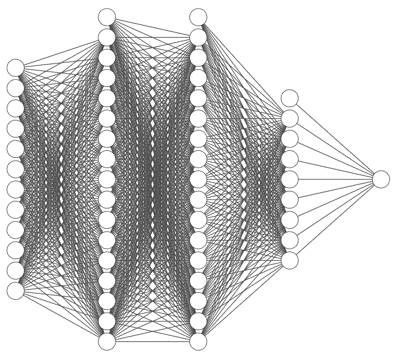
- input node 수를 가변적으로 입력받을 수 있는, input-16-16-12-8-1 구조를 설계합니다.
- loss function은 RMSE를 만들어 사용합니다.
- PyTorch에서 MSE를 제공하긴 하지만, 오차의 범위가 직관적으로 보이는 RMSE를 더 선호합니다.
1 | # neural network: ninput(12)-16-16-12-8-1 |
3.1.2. preprocessor using Pipeline
Pega Devlog: pytorch & sklearn pipeline
scikit-learn: sklearn.preprocessing.OneHotEncoder
scikit-learn: sklearn.preprocessing.PolynomialFeatures
scikit-learn: sklearn.compose.ColumnTransformer
-
펭귄 데이터셋에는 categorical feature가 세 개나 있습니다.
-
species,island,sex에는 숫자가 아닌 문자가 들어있기 때문에 신경망에 투입될 수 없습니다. -
여러 방법을 사용해 숫자로 바꿔주어야 합니다. 여기서는 one-hot-encoder를 사용하기로 합니다.
-
한편 numerical feature는 scaling이 필요합니다.
-
신경망의 weight를 수렴시키는 gradient descent를 안정적으로 만들기 위해서입니다.
-
관련해서는 지난 글에서 언급한 적이 있으니 여기서는 생략합니다.
-
다만, 지난 글보다 파이프라인을 분할해서 구성합니다.
-
부품이 잘 준비돼있으면 활용성이 높아지기 때문입니다.
-
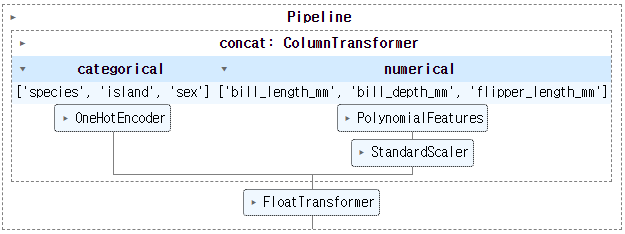
categorical feature와 numerical feature에 각기 one-hot-encoding과 scaling을 적용해 합칩니다.
-
numerical feature에는 polymomial feature 생성기를 붙여 교호작용을 고려할 수 있는 장치를 만듭니다.
-
feature 유형에 따라 다른 길을 타고 들어간 데이터는
ColumnTransformer로 결합됩니다. -
마지막으로, float64 데이터 타입으로 float32로 변환하는
FloatTransformer를 추가합니다. -
OneHotEncoder등에서 생성되는 데이터 타입이 float64인데, PyTorch은 float32만 입력받기 때문입니다.
1 | # preprocessors |
- 작성한 전처리 파이프라인을 그림으로 출력해 확인합니다.
1 | from sklearn import set_config |
- preprocessor에 train, validation, test용으로 준비한 X 데이터를 투입합니다.
- preprocessor를 통한 데이터는
numpy.ndarray로 변합니다. - PyTorch에 넣기 위해
torch.Tensor로 한번 더 바꿔줍니다. - y 데이터는 preprocessor에 넣을 필요가 없으니
torch.Tensor()에만 통과시킵니다.
1 | # Xs |
- 변환된 데이터의 타입을 확인합니다.
- preprocessing후, 그리고
torch.Tensor()를 거치며 변하는 모습이 관찰됩니다.
1 | # Xs |
- 실행 결과
1 | # dtype of X_train: [dtype('O') dtype('O') dtype('float64') dtype('float64') dtype('float64') dtype('O')] |
3.1.3. training & validation
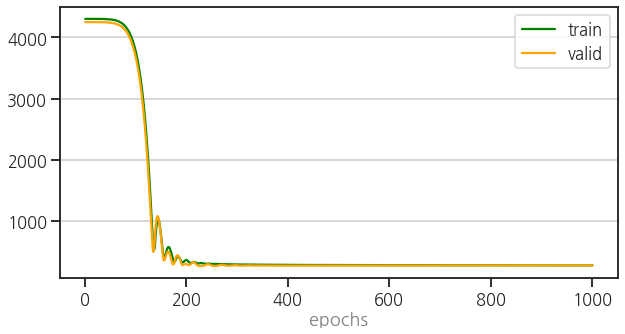
- neural network와 preprocessor가 준비됐습니다.
- loss_function, optimizer, 최대 epochs를 지정하고,
- 한편으로 leanring rate scheduler와 early stopping도 동원합니다.
- train과 validation 함수와 함께 epoch에 따른 loss를 시각화하는 함수도 준비합니다.
1 | from torch.optim.lr_scheduler import OneCycleLR |
- 실행 결과
1 | 100% ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 1000/1000 [00:04<00:00, 222.90it/s] |
3.1.4. parity plot
- training, valiation, testing set의 학습 결과를 비교하는 함수를 만듭니다.
- 참값(
true)과 예측값(pred)을 scatter plot으로 그립니다. - 여기에 MAE, RMSE, R2를 동시에 출력하는 함수를 만듭니다.
1 | import matplotlib.colors as colors |
3.1.5. testing
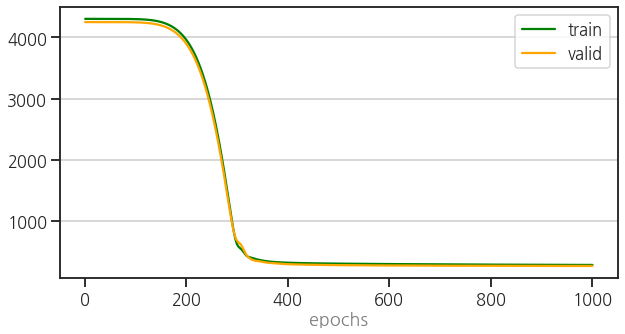
- training set으로 신경망을 학습시키고,
- validation set으로 학습 현황을 모니터링하며
- validation set의 성능이 마음에 들지 않을 경우 신경망의 구조나 learning rate와 같은 hyperparameter를 수정하여 성능을 높입니다.
- 이 과정을 거쳤다고 치고, training + validataion set으로 재학습을 시킨 후 testing data로 최종 결과를 얻습니다.
1 | # evaluate training and validataion set |
- 실행 결과
1 | 100% ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 1000/1000 [00:04<00:00, 270.43it/s] |
- testing 결과까지 얻은 후, 최종적으로 parity plot 세 개를 같이 그립니다.
1 | # evaluate testing set |
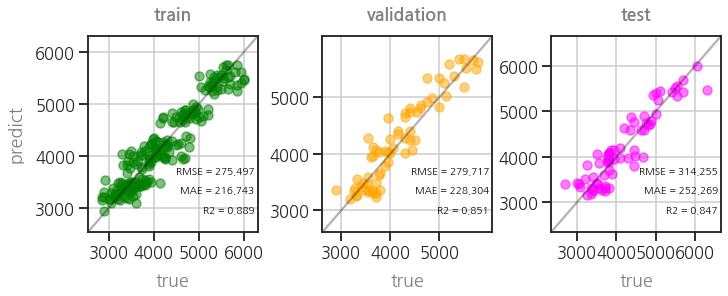
-
펭귄 체중이 제법 괜찮게 예측되고 있습니다.
-
scikit-learn Pipeline으로 categorical feature와 numerial feature에 적절한 처리를 마친 후,
-
PyTorch로 딥러닝 학습을 잘 시킨 것입니다.
-
Pipeline으로 전처리 과정을 모두 묶었고, PyTorch 딥러닝을 함수화 했습니다.
-
하지만 PyTorch로 따로 넘어가는 과정이 따로 노는 느낌이 듭니다.
-
이제 하나로 묶어볼 차례입니다.
-
넘어가기 전에, parity plot을 그린 명령도 함수로 정리합니다.
1 | def plot_parity3(model, target=["train", "val", "test"], figsize=(10, 4), |
