- 저는 tabular data를 다룹니다.
- 간혹 딥러닝을 하고 싶지만 표준화등 전처리도 해야 합니다.
- 범주형 변수를 인코딩해서 feature importance도 보고 싶습니다.
- skorch(sklearn + pytorch)를 사용하면 가능합니다.
1. skorch = sklearn + pytorch

- 저같은 사람들을 위해 skorch라는 라이브러리가 있습니다.
- scikit-learn의 장점인 grid search 등을 딥러닝과 함께 사용할 수 있고
- tutorial에서 transfer learning, U-Net, Seq2Seq 등을 지원합니다.
2. sklearn pipeline
- scikit-learn의 파이프라인은 데이터 전처리에서 발생하는 불확실성을 줄여줍니다.
- 데이터가 거쳐갈 길을 단단하게 만들어줌으로써 실수를 사전에 예방할 수 있습니다.
- 특히 PCA나 One-hot encoding처럼 trainset의 정보를 기억해서 testset에 적용해야 할 때 좋습니다.
2.1. 예제 데이터셋
- 펭귄 데이터셋을 사용해서 펭귄 체중 예측모델을 만들어 봅니다.
- 편의를 위해 결측치까지 싹 지운 채로 시작합니다.
1 | %matplotlib inline |
- 실행 결과: 결측치가 모두 제거되었습니다.
1 | species 0 |
- 데이터셋을 준비합니다.
- 펭귄 체중만 y, 나머지는 모두 X입니다.
1 | y = df_peng["body_mass_g"] |
- trainset과 testset으로 나눕니다.
1 | # data split |
2.2. pipeline 구축
-
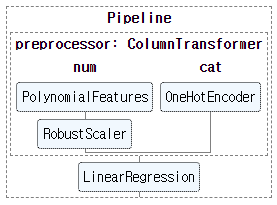
scikit-learn으로 pipeline을 구축합니다.
-
numerical feature는 회귀모델 적용을 고려한
PolynomialFeatures와 -
데이터 정규화를 위한
RobustScaler를 거칩니다. -
categorical feature는
OneHotEncoder를 거칩니다. -
필요한 라이브러리를 불러옵니다.
1 | # encoder |
- pipeline을 구축하는 함수를 만듭니다.
get_model_0()을 실행하면 파이프라인이 만들어질 것입니다.- 전처리 후 머신러닝 모델로는 선형회귀와 랜덤포레스트를 선택할 수 있습니다.
1 | def get_model_0(X_cols, degree=1, method="lr"): |
-
6번째, 10번째 행을 보시면 조금 특이한 처리가 들어가 있습니다.
-
feature selection에 사용되는 장치입니다.
-
feature 이름들을 하드코딩하면 feature selection이 불가능하기 때문에 이렇게 합니다.
-
만들어진 구조를 확인합니다.
-
일단 모든 인자를 모두 입력합니다.
1 | from sklearn import set_config |
2.3. pipeline 전처리 확인
- pipeline에서 전처리 모듈만 떼어서 실행합니다.
- pipeline의 모듈을 호출하는 방법은 모델이름[“모듈이름”]입니다.
- 따라서 우리의 전처리 모듈은 model_0[“preprocessor”]입니다.
1 | X_train_pp = model_0["preprocessor"].fit_transform(X_train) |
- 실행 결과: 첫 행만 찍어봤습니다. 숫자가 많습니다
1 | (266, 12) |
-
6개의 인자를 넣었는데 12개가 나왔습니다.
-
처음의 0은 LinearRegression에서 만든 intercept 항입니다.
-
네번째 1부터는 species, island, sex의 one-hot encoding 결과물입니다.
-
전처리 이후 데이터 분포도 확인합니다.
-
시각화 코드는 다소 길고, 여기선 중요하지 않아서 접었습니다.
코드 보기/접기
1 | # Figure 생성 |
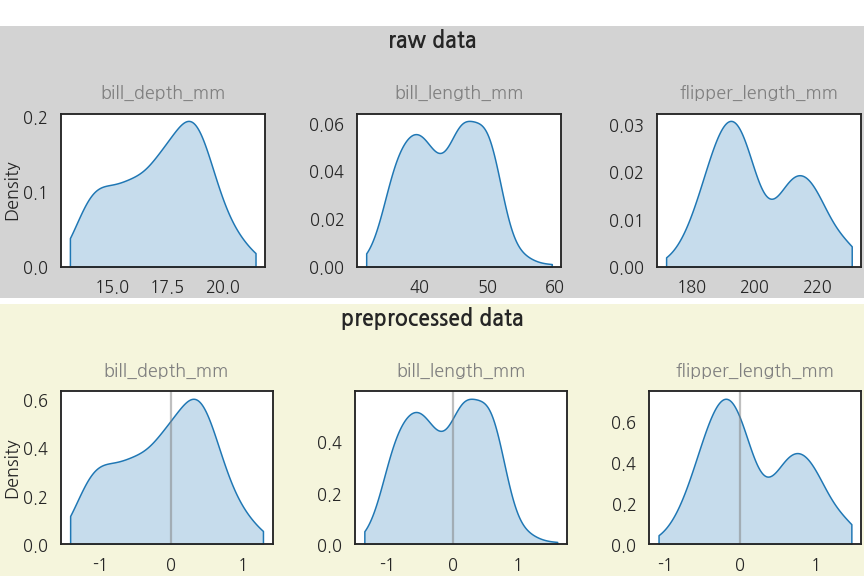
- RobustScaler의 효과가 잘 보입니다.
2.3. pipeline 학습
- pipeline 전체를 사용해서 학습시킵니다.
- 명령은 scikit-learn 스타일 그대로
.fit()입니다.
1 | model_0.fit(X_train, y_train) |
- 학습이 잘 되었는지 결과를 확인합니다.
- parity plot 시각화 코드는 접어두었습니다.
코드 보기/접기
1 | # parity plot |
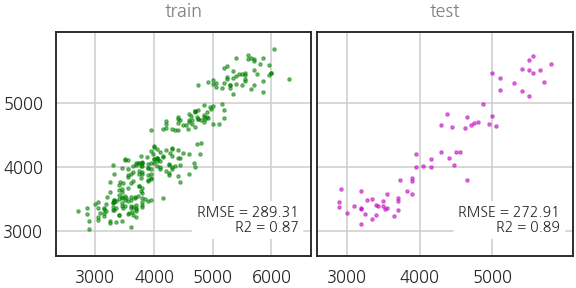
- 단순 선형 회귀 모델인데 제법 쓸만합니다.
- 이제 pipeline에 랜덤포레스트 모델을 탑재해서 돌려봅니다.
1 | model_1 = get_model_0(list(X_train.columns), degree=1, method="rf") |
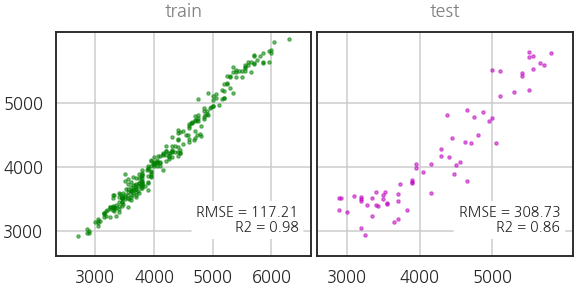
-
과적합이 의심되긴 하지만 랜덤포레스트도 잘 나오네요.
-
이번에는 feature selection도 되는지 확인합니다.
-
부리 길이
bill_length_mm와 종species만 가지고 결과를 예측해봅니다.
1 | model_2 = get_model_0(["bill_length_mm", "species"], degree=1, method="rf") |
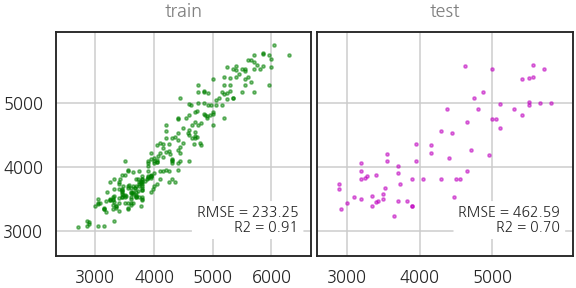
- 멀쩡한 인자들을 제외했으니 성능이 떨어지는 건 정상입니다.
- pipeline을 작성하기에 따라 feature 중 일부만 넣어도 동작한다는 것이 중요합니다.
3. pytorch deep learning
- 딥러닝은 다른 방법에 비해 복잡하고 연산자원이 많이 들지만 장점이 많습니다.
- 이미지나 시계열을 다룰 때 큰 힘을 발휘하는데, 간혹 tabular data에도 필요합니다.
- pytorch만을 사용해서 모델을 만들어보고 pipeline에 탑재해서도 결과를 얻어봅니다.
3.1. pytorch only
- 파이토치로 신경망 모델을 만들고 같은 데이터로 같은 문제를 풀어봅니다.
- 간단한 신경망 모델을 만듭니다. 나중에 pipeline 안에 넣을 겁니다.
- feature selection을 대비해서 input dimension을 가변적으로 만듭니다.
1 | from torch import optim |
- pytorch에 데이터를 넣으려면 tensor로 만들어야 합니다.
1 | X_train_tensor = torch.Tensor(pd.get_dummies(X_train).astype(np.float32).values) |
- 지금 만든 모델에 학습을 시킬 수 있는 코드를 구현합니다.
- 1만 epoch동안 충분히 데이터를 넣어봅니다.
- loss function으로는 RMSELoss를 구현해서 사용했습니다.
1 | net = RegressorModule() |
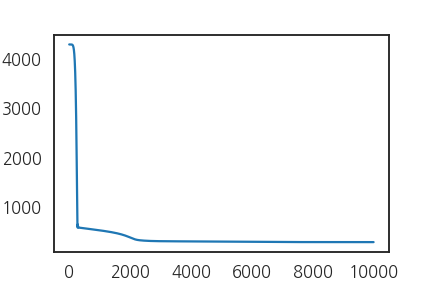
- 제법 학습이 잘 된 것 같습니다.
- 예측 성능을 확인합니다.
1 | # numpy array를 pytorch tensor로 변환 |
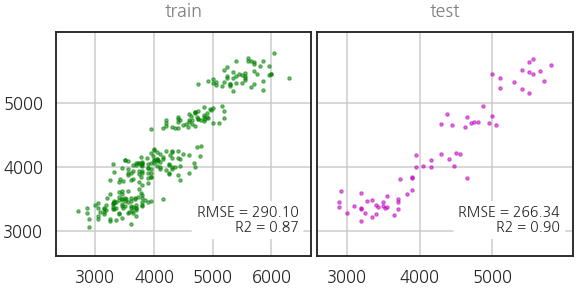
- 딥러닝으로도 제법 괜찮은 성능이 나오는 것을 확인했습니다.
3.2. pytorch @pipeline
-
skorch를 이용해서 pytorch를 pipeline 안에 탑재합니다.
-
skorch은 pytorch를 scikit-learn 객체처럼 만들어주는 일을 합니다.
-
그래서 skorch로 감싼 pytorch 객체의 학습은
fit()이고, -
예측은
.forward()</b>가 아니라 <b>.predict()입니다. -
skorch의
NeuralNetRegressor()로 딥러닝 모듈 전체를 감싸고, -
학습에 필요한 인자를 매개변수로 전달합니다.
-
그리고 중요한 사항이 하나 있습니다.
-
scikit-learn이 뱉는
np.float64를np.float32로 변환해야 합니다. -
이를 위해 custom transformer를 만들어 적용합니다.
1 | from skorch import NeuralNetRegressor |
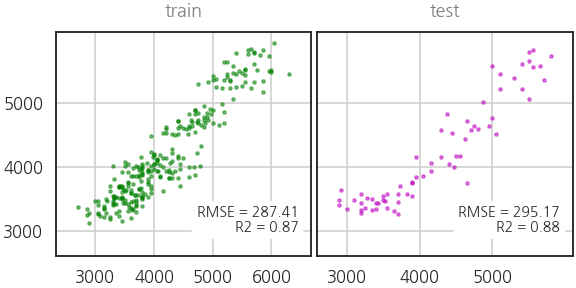
- 모델을 만들고 확인합니다.
- 앞서 pytorch로 구현한 뉴럴넷 구조가 그대로 들어가 있습니다.
1 | model_T = get_model_T(list(X_train.columns), degree=1, method="torch") |

- 성능을 확인합니다. 준수하네요.
4. permutation feature importance
- 같은 파이프라인에서 선형, 트리, 딥러닝이 모두 구현되었습니다.
- 각각의 인자 중요도를 한번 확인해보겠습니다.
- permutation importance를 사용합니다.
1 | from sklearn.inspection import permutation_importance |
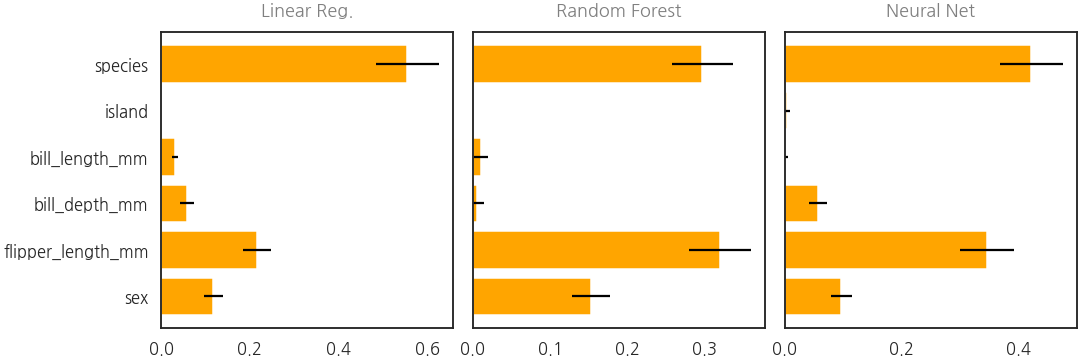
- 입력 feature별 인자 중요도가 깔끔하게 정리되었습니다.
- 양상도 전반적으로 비슷하게 나오네요.
- 사소한 기능같지만 tabular data를 딥러닝으로 돌렸을 때 이 그림을 그리기가 어려웠습니다.
- 이 글과 코드가 비슷한 어려움을 겪는 여러분께 도움이 되면 좋겠습니다.
