- 한국지능정보사회진흥원(NIA) 요청으로 데이터 스토리를 작성했습니다.
- 1971-2020, 50년간 국내 개봉작을 데이터의 형태로 경험했습니다.
- 시각화 코드를 조금 자세히 풀어서 전달드리고자 합니다.
1. "빅"데이터 검수 문제
-
최근 전에 없이 국가적인 단위에서 데이터 수집 사업이 수행되었습니다.
-
앞으로 다가올 데이터 기반 사회를 위한 기초공사입니다.
-
그러나 수집된 데이터의 유효성을 검증하기는 참으로 어렵습니다.
-
데이터가 한 두 개도 아니고 일일이 열어보기 어려울 뿐더러,
-
데이터가 있다와 쓸만한 데이터가 있다는 것은 완전히 다른 차원의 문제입니다.

-
NIA의 데이터 검증 의지를 가지신 분들 덕택에 모니터링단으로 활동할 수 있었습니다.
-
적지 않은 문제를 발견해 공식 보고와 함께 여러 제언을 드렸습니다.
-
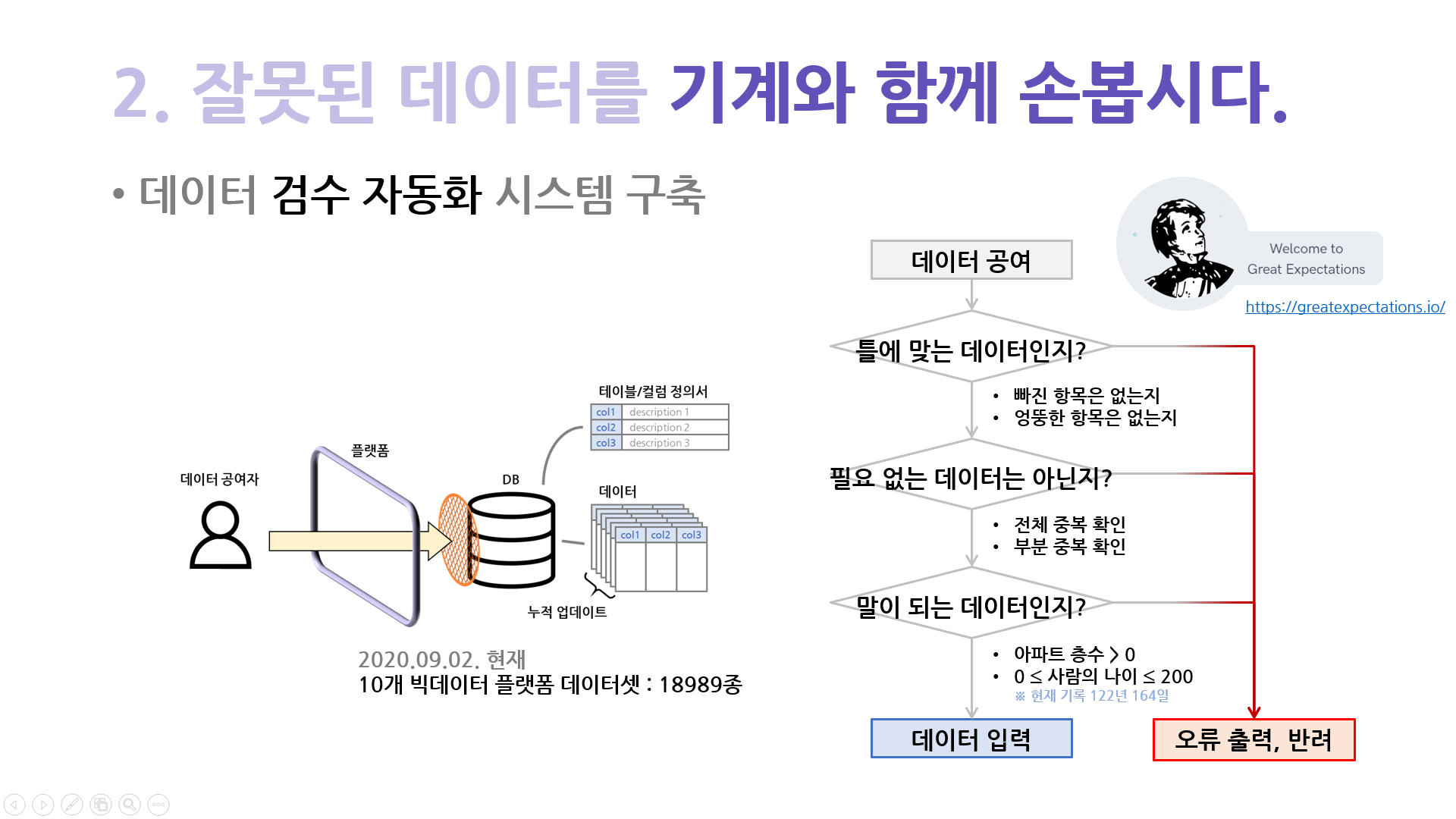
그 중 가장 강하게 말씀드린 것은 데이터는 활용될 때 검증된다는 것,
-
그리고 사람의 힘으로는 불가능하니 자동 검수 시스템이 필요하다는 것이었습니다.
-
작년 AI Festival에서 이 말씀을 발표드리는 한편 신문에 기고문도 실었습니다.
- 해당 발표와 기고문은 여기서 보실 수 있습니다.
2. NIA 데이터 스토리
-
다행히 NIA에 비슷한 생각을 하는 분들이 있으셨습니다.
-
적재된 데이터를 소비자가 구매하기 전에 스토리로 가공하여 게시하셨습니다.
-
많은 분들이 글을 써 주셨고, 제게도 기회가 주어졌습니다.
-
데이터 스토리 작성을 위해 여러 데이터를 살펴보았고, 문제점을 찾을 때마다 보고를 했습니다.
-
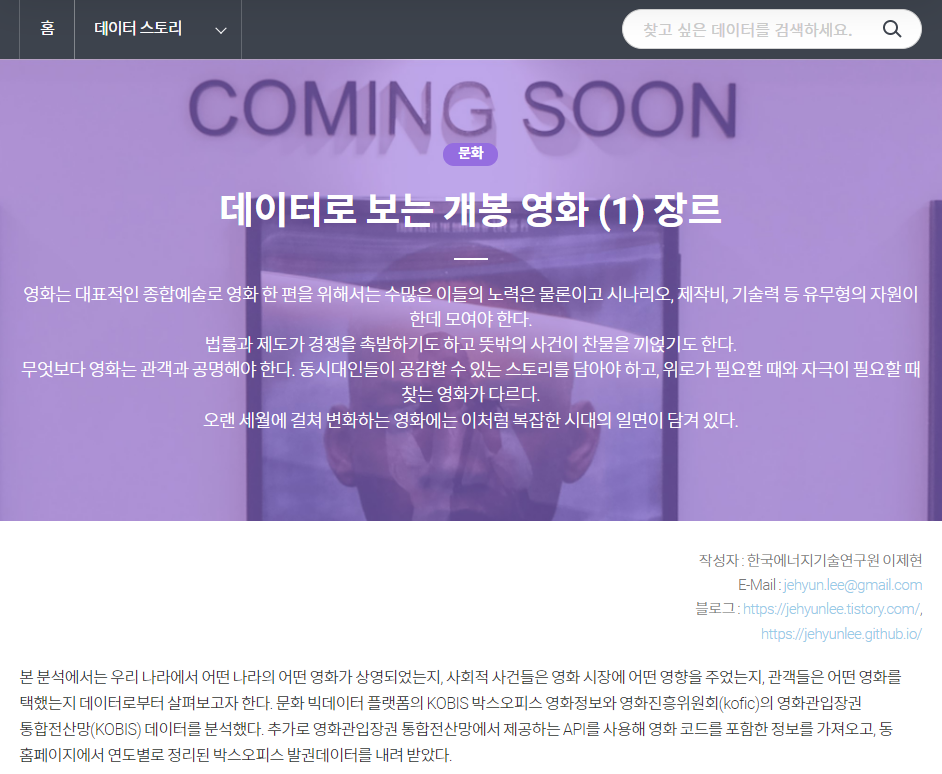
그리고 영화 데이터에 정착하여 영화 데이터를 분석한 스토리를 기고했습니다.
-
1971년 이후 50년간의 개봉 영화 23,409편을 대상으로 삼았습니다.
-
제 글에 점수를 주라면 100점 만점에 60~70점 정도 되는 것 같습니다.
-
너무 힘이 들어간 부분도 있고, 지쳐 힘이 빠진 부분도 있습니다.
-
이렇게 긴 분석 글을 처음 쓰다 보니 결과물을 볼 때 많이 아쉬운 것이 사실입니다.
-
한편 부족하나마 제 성장에도 보탬이 된 것이 사실입니다.
3. 과정
-
데이터 스토리는 소스 코드까지 제출하여 공개했습니다.
-
그러나 저 그림을 그리기 위해 생각한 과정들,
-
그리고 저 그림의 코드는 왜 저렇게 작성되었는지는 충분히 설명되지 않았습니다.
-
앞으로 여러 개의 글을 통해 이 점을 메꾸려고 합니다.
-
여러분께서 보시고 좋은 점은 교사로, 부족한 점은 반면교사로 활용하시면 좋겠습니다.
-
이 글을 쓰는 과정이 제 성장의 거름이 되었듯 여러분의 성장에도 보탬이 되기를 바랍니다.
