- 시각화의 대상은 데이터만이 아닙니다.
- 데이터를 비롯해 이름, 단위를 써줘야 하고
- 데이터를의 분석결과를 함께, 또는 따로 강조해서 그려야 합니다.
- 데이터마다 붙는 꼬리표와 파생변수를 클래스를 이용해서 정리해 봅시다.
1. 데이터
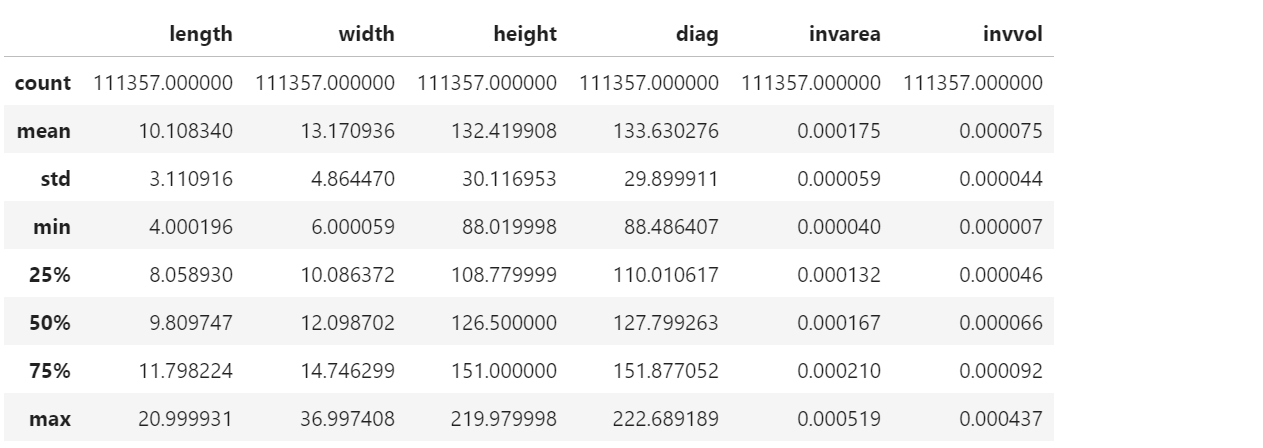
- 10만개 정도의 상자 데이터가 있습니다.
- 길이(length), 너비(width), 높이(height)가 있고,
- 여기로부터 입체 대각선(diagonal), 표면적(area)의 역수, 부피(area)의 역수가 있습니다.
1 | %matplotlib inline |
2. 시각화
- 데이터의 분포를 확인합니다.
- x축 이름을 제대로 써주고, 단위까지 달아줍니다.
2.1. 기존 방식
- 이름과 단위를 list로 받아서 for loop에 axes와 함께
zip으로 넣어주는 것이 가장 효과적입니다.
1 | # general |
-
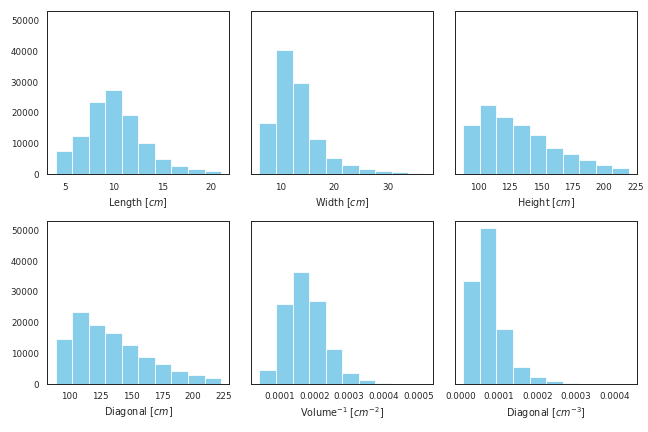
나름 깔끔하다고 볼 수 있지만, 위험이 있습니다.
- 데이터 종류가 많아지면 names와 units에서 적절한걸 찾아가기 힘듭니다.
- 데이터 순서가 바뀌면 names와 units 배열 순서를 바꿔야 합니다. 헷갈립니다.
- for loop 안에 데이터프레임과 names, units가 함께 돌고 있습니다.
나쁘지 않지만 머리 속에 세 가지를 넣어야 합니다.
-
혼동을 줄이고 코드를 깔끔하게 보완해 봅시다.
2.2. class 사용
- python의 class는 장점이 많습니다.
- 인스턴스 하나 안에 여러 속성을 담을 수 있고, 점(.)으로 접근하기 쉽습니다.
- Feature라는 클래스를 만들어 변수들을 담아봅니다.
1 | class Feature: |
- 클래스를 사용해서 인스턴스를 찍어내 봅니다.
1 | # 인스턴스 만들기. name과 unit은 생성시 설정 |
- 의도대로 잘 들어갔는지 확인합니다.
1 | # X4 확인 |
* 실행 결과: 데이터가 잘 들어가 있습니다.
1
2
3
X4.name= Surf.Area$^{-1}$
X4.data= [0.00026171 0.00018886 0.00017365 ... 0.0003015 0.00037055 0.00041062]
X4.unit= $cm^{-2}$
- 클래스를 사용해 같은 그림을 그려봅시다.
- 색깔만 바꾸어 그립니다.
1 | # class |
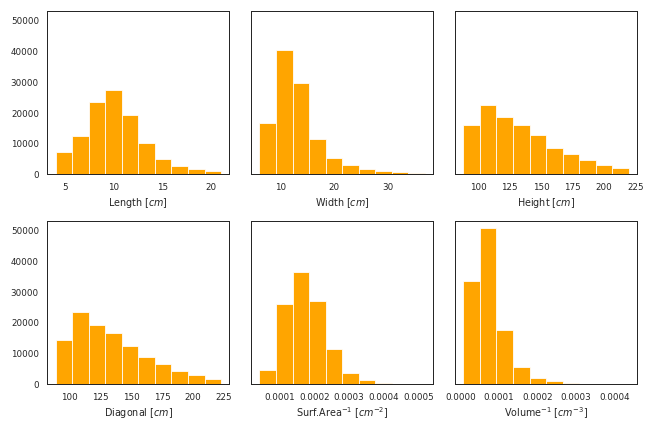
- 섞여있던 데이터프레임과 units, names 리스트가 Feature class X를 중심으로 정리되었습니다.
3. 클래스 활용 데이터 전처리
- 클래스 안에서 함수를 사용할 수 있습니다.
- 바꾸어 말하면, 데이터를 넣는 순간 인자 추출과 같은 간단한 전처리가 가능하다는 뜻입니다.
3.1. 데이터 전처리 함수 추가
- 클래스 함수를 조금 바꿔봅니다.
1 | def get_stats(data): |
set_data부분이 바뀌었습니다.- 데이터를 읽어들이면
get_stats()함수가 적용되어 최소값, 최대값, 범위에 이어 10% 마진 포함한 범위가 계산됩니다. - 아까와 똑같이 데이터를 읽어주고,
1 | # 인스턴스 만들기. name과 unit은 생성시 설정 |
- 간단한 통계처리 결과를 확인합니다.
1 | #simple statistics |
3.1. 자동 전처리 활용 시각화
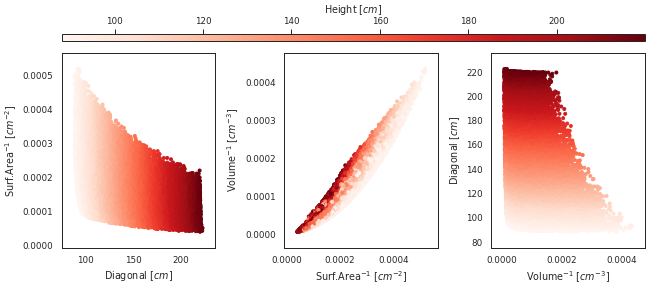
- matplotlib은 그림을 그리면 어느 정도 자동으로 x, y 범위를 설정합니다.
- 하지만 내 목적에 따라 일일이 범위를 지정해줘야 할 때가 있습니다.
- 클래스에서 뽑아놓은 범위(10% 마진)를 적용합시다.
1 | fig, axs = plt.subplots(ncols=3, figsize=(9, 4), constrained_layout=True) #, gridspec_kw={"width_ratios":[8,8,8,1]}) |
4. 결론
- 인자마다 비슷한 처리를 반복해야 한다면 클래스가 좋은 해법일 수 있습니다.
- 히스토그램 범위와 구간 경계 추출, 잡음 제거(smoothing), 미분과 적분 등 활용처는 무궁무진합니다.
- 각자 용도에 맞게 잘 사용하시면 좋겠습니다.
