- Google trend 분석 결과는 그 자체로 깔끔합니다.
- 그러나 여러 항목을 개별적으로 분석하려면 데이터를 다운받아 분석하는 것이 좋습니다.
1. Google Trends
-
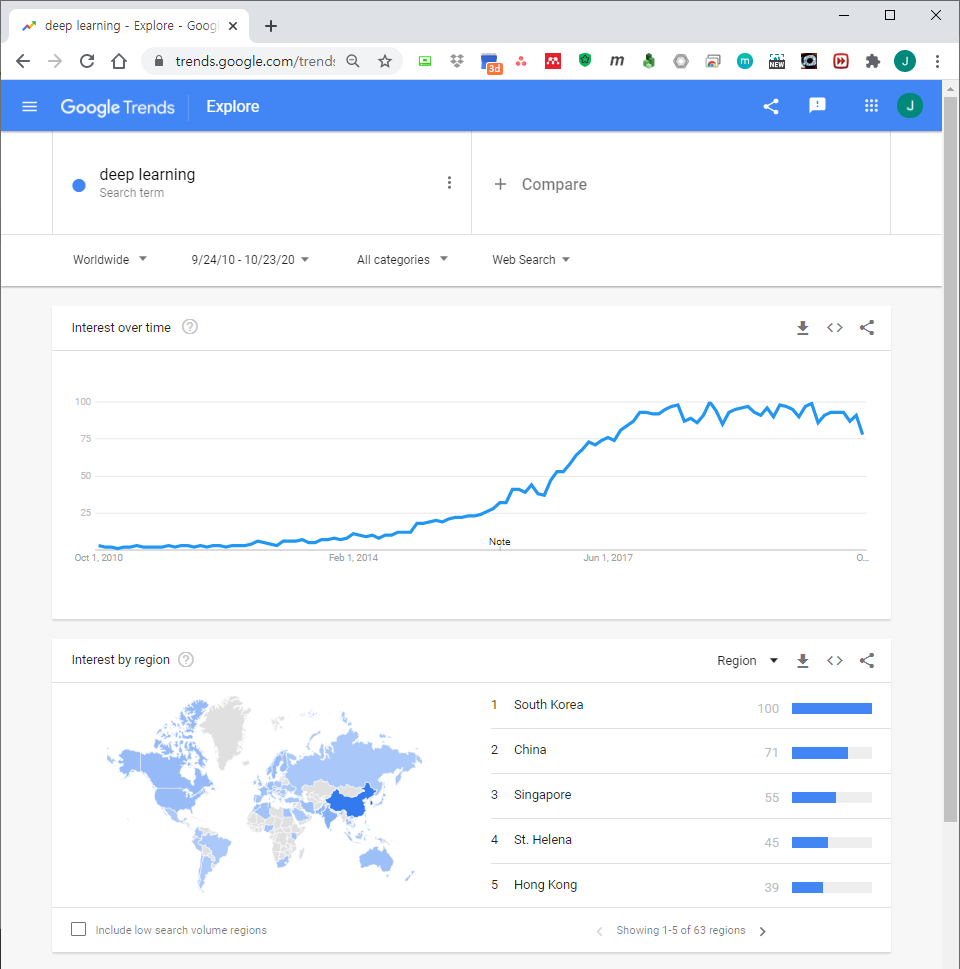
Google trends는 검색어를 입력하는 것 만으로 웹, 이미지, 또는 유튜브에서 해당 검색어가 얼마나 빈번하게 등장하는지 경향을 쉽게 알 수 있습니다.
-
절대값이 아니라 검색된 기간 내의 최대값을 100으로 표준화해서 보여준다는 점이 조금 아쉽기는 하지만 정성적인 경향 변화를 보기에 적절합니다.
-
지난 10년간 인공지능 관련 키워드의 경향을 알아봤습니다.
- 날짜에 Custom Range를 지정해서 넣고,
- 검색어에 artificial intelligence, big data 등 단어를 넣습니다.
- 오른쪽 위 다운로드 버튼을 누르면 .csv 파일 형식으로 다운로드 됩니다.
-
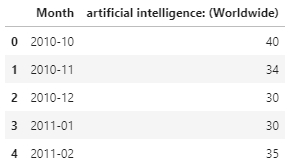
파일을 열어보면 구조가 간단합니다.
-
시간에 따른 검색 빈도가 표준화되어 나타납니다.
-
csv 다운로드시 파일명을 지정할 수 없습니다.
-
여러 검색어를 다운받으며 적절히 파일명을 바꿔줍니다.
2. Python에서 여러 데이터 비교하기
- 각자 다른 값이 최대값 100으로 표준화되어 있습니다.
- 따라서 이들을 겹쳐 그리는 것은 무의미한 교차점들을 만들기 때문에 적절치 않습니다.
- 여러 개의 공간을 만들고 별도로 그려줍니다.
1 | # Google Trends 파일명 |
-
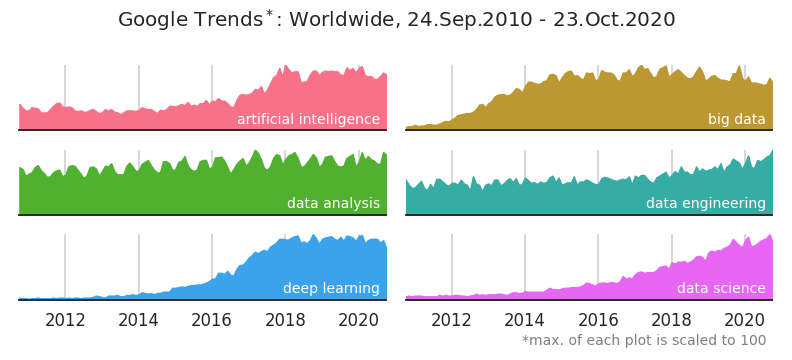
data analysis에 반년 주기성이 보입니다.
-
big data는 2012년 이후 상승했네요.
-
deep learning은 2016년 이후 급격히 상승했습니다.
-
data science와 data engineering이 꾸준하게 상승중입니다.
-
이번에는 주요 라이브러리 경향성을 보겠습니다.
1 | libs_time = ['numpy.csv', 'keras.csv', 'pandas.csv', 'tensorflow.csv', 'sklearn.csv', 'pytorch.csv'] |
-
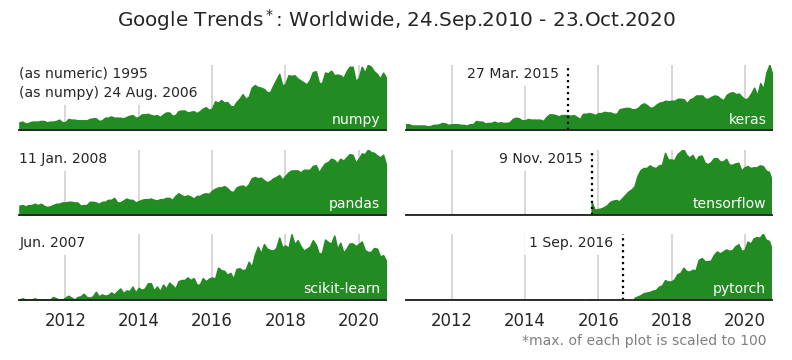
라이브러리별 initial release date를 함께 표기했습니다.
-
tensorflow와 pytorch는 고유명사라서 initial release이후 등장합니다.
-
그러나 뿔이라는 뜻을 가진 보통명사인 keras는 initial release 한참 전부터 등장합니다.
-
맏형격인 scikit-learn은 2007년에 처음 나왔지만 유의미한 신호가 보이지 않다가 2012년 이후 쭉쭉 올라갔네요.
-
라이브러리별로 어느 나라에서 많이 찾았는지 보겠습니다.
1 | fig, axs = plt.subplots(ncols=6, figsize=(11, 5)) |

- 대부분 중국이 1위, 한국이 2위입니다.
- 사실 의외입니다. 수위에 있을 것 같은 미국은 검색이 안 된 것이 아니라 한참 아래 순위에 있습니다.
- 미국 사람들은 검색어에 뭘 넣는 걸까요? 검색을 안하는 건 아닐텐데요.
