Essence
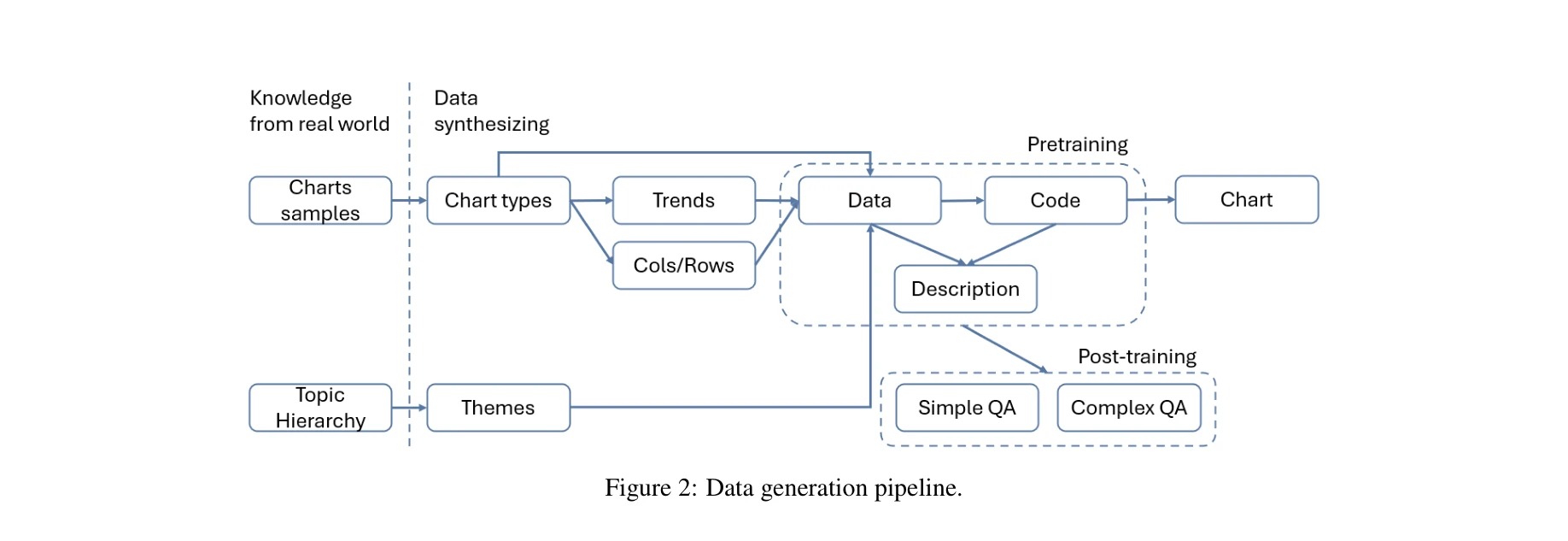
Data generation pipeline: Stage 1 데이터 생성, Stage 2 차트 생성, Stage 3 QA 쌍 생성
LLM(Large Language Model)만을 활용하여 약 400만 개의 다양한 차트 이미지와 7,500만 개 이상의 밀집 주석(데이터 테이블, 코드, 설명, QA)으로 구성된 대규모 합성 차트 데이터셋 SynChart를 구축하고, 이를 통해 4.2B 매개변수의 차트 전문가 모델을 학습하여 ChartQA 벤치마크에서 GPT-4O에 근접하면서도 GPT-4V를 능가하는 성능을 달성했다.
