저자: Xuanle Zhao, Xianzhen Luo, Qi Shi, Chi Chen, Shuo Wang, Zhiyuan Liu, Maosong Sun | 날짜: 2025 | DOI: arXiv:2501.06598v3
Essence
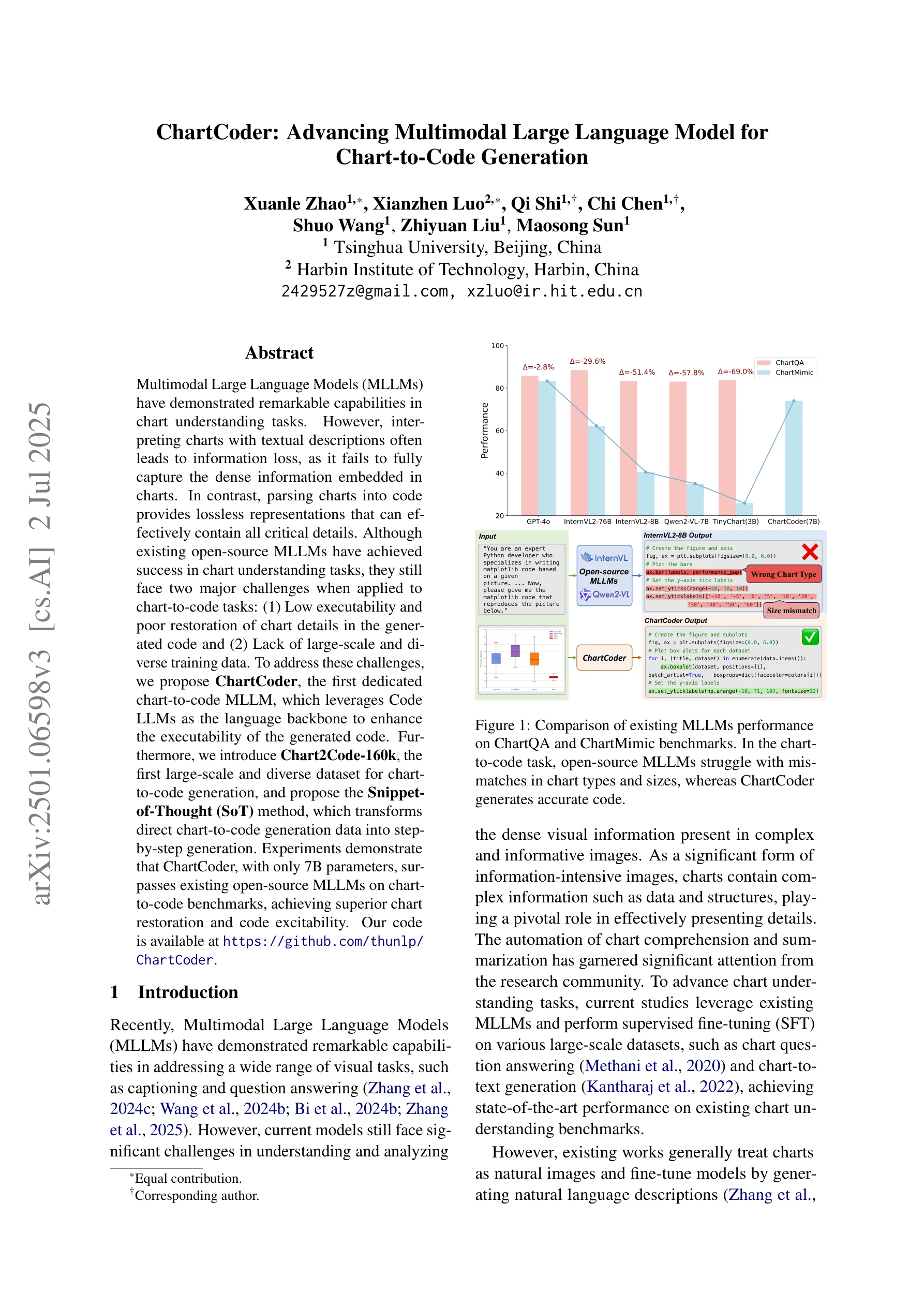
Figure 1: 기존 MLLM과 ChartCoder의 성능 비교. 차트-코드 생성 작업에서 기존 오픈소스 MLLM은 차트 타입 불일치와 크기 오류를 범하지만, ChartCoder는 정확한 코드를 생성한다.
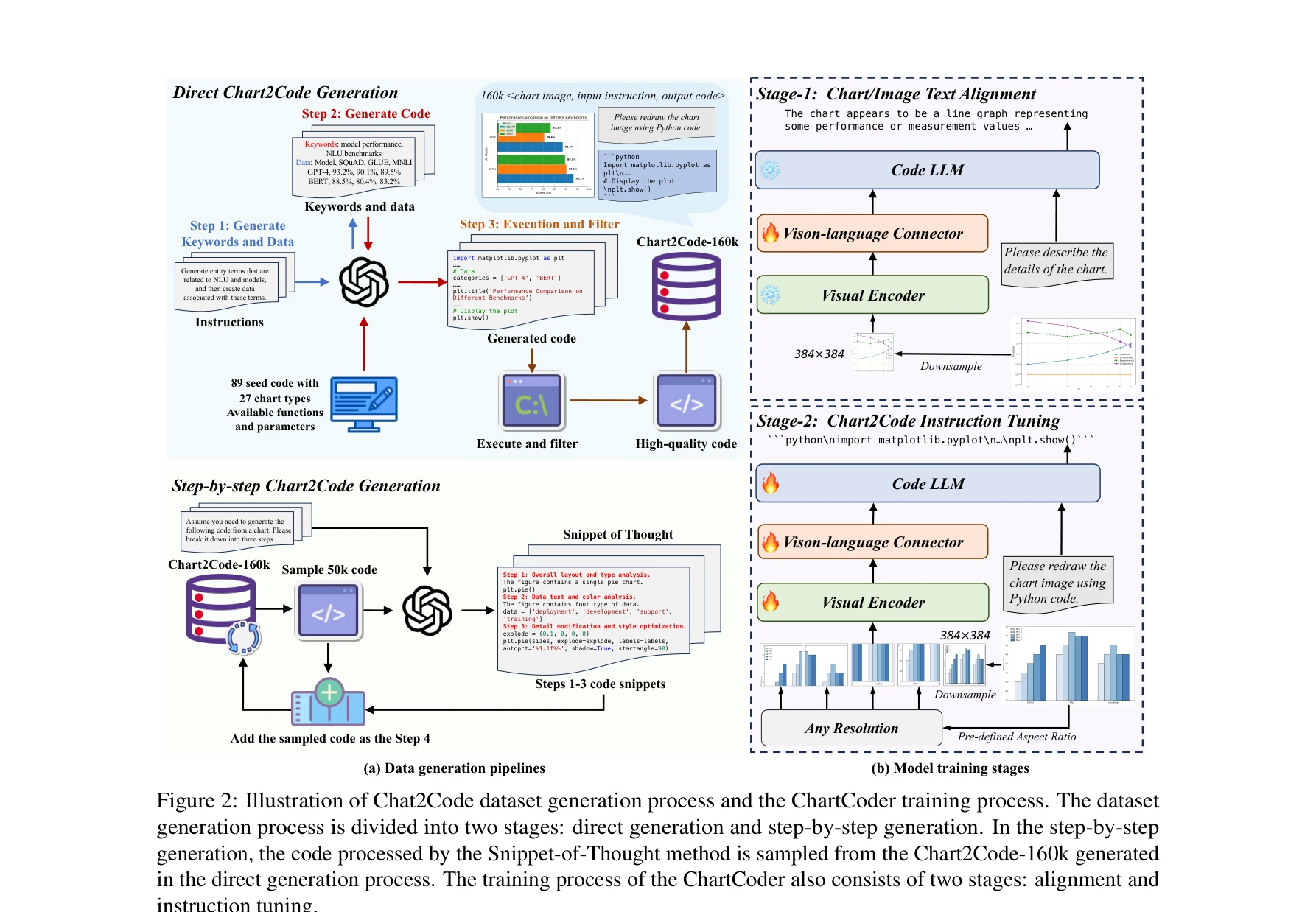
본 논문은 차트 이미지를 코드로 변환하는 전문화된 멀티모달 대형언어모델(MLLM)인 ChartCoder를 제안하며, 이를 위해 대규모 차트-코드 데이터셋(Chart2Code-160k)과 단계적 생각(Snippet-of-Thought, SoT) 방법론을 소개한다.
Evaluation
Novelty: 4.5/5 Technical Soundness: 4/5 Significance: 4.5/5 Clarity: 4/5 Overall: 4.2/5
총평: ChartCoder는 차트-코드 생성이라는 미개척 영역을 개척하면서 Code LLM 백본과 대규모 데이터셋, SoT 방법론을 통해 실제 성능 개선을 달성한 의미 있는 연구이다. 다만 방법론의 이론적 깊이와 응용 범위 확대에서 추가 개선의 여지가 있다.