Achievement
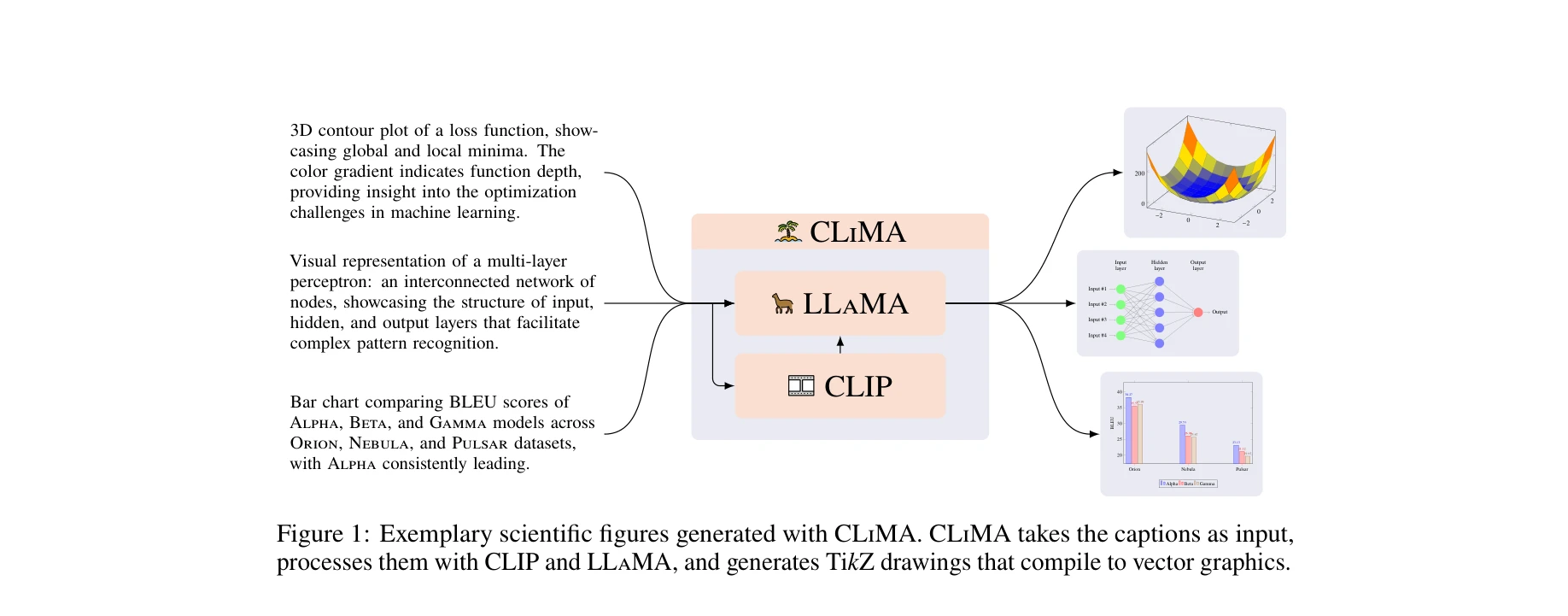
그림 1: CLiMA로 생성된 과학 벡터 그래픽 예시
- DaTikZ 데이터셋 구축: 웹사이트, TeX Stack Exchange, arXiv, GPT-4 생성 데이터 등 다양한 출처에서 수집한 120,789개의 TikZ-캡션 쌍으로 구성된 최초의 대규모 TikZ 데이터셋 창출. 62.71%는 데이터 증강(augmentation) 처리됨.
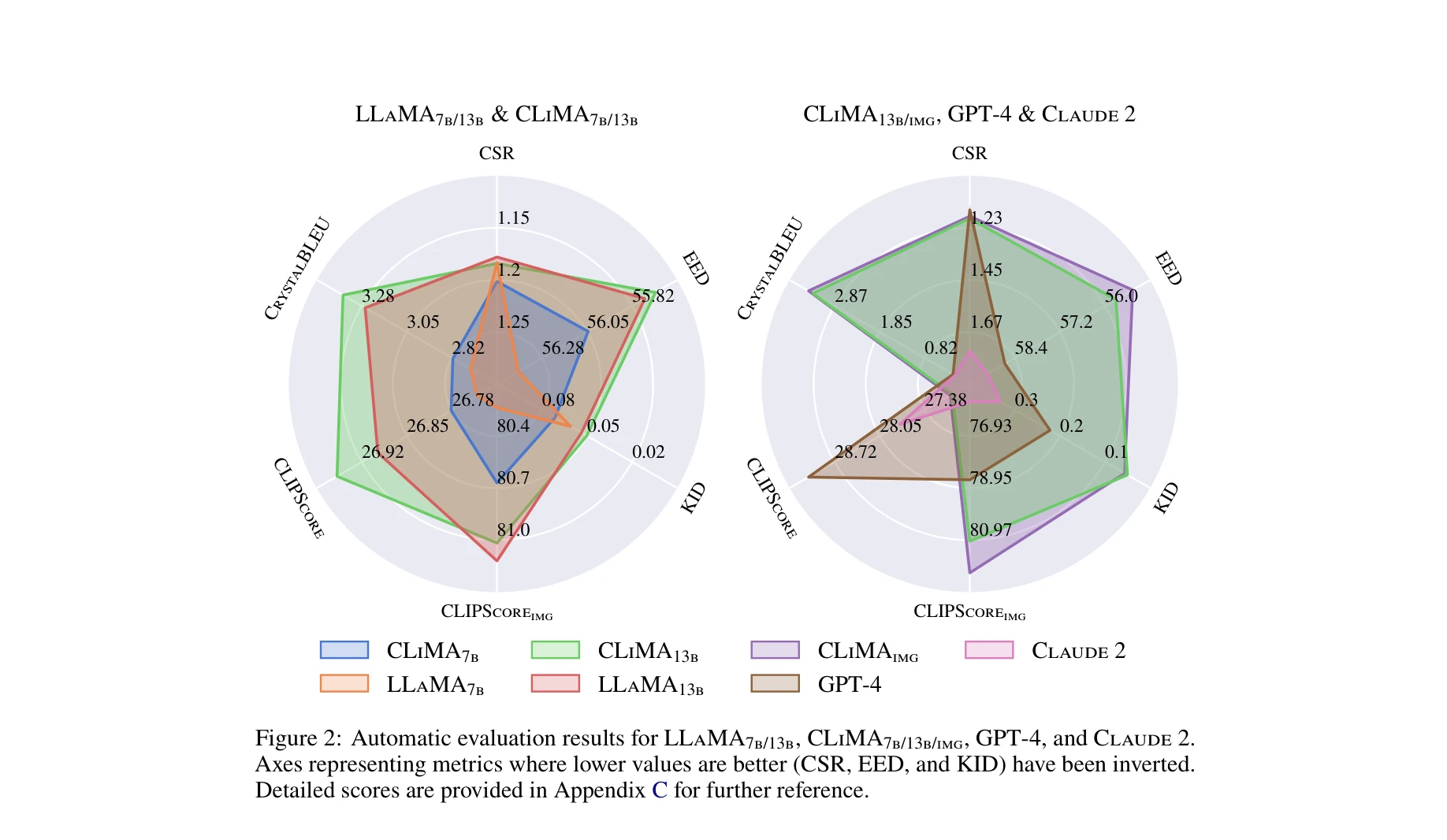
- 미세조정 LLaMA 모델 성능 우위: 자동 평가와 인간 평가 모두에서 DaTikZ로 미세조정된 LLaMA(7B/13B)가 GPT-4와 Claude 2보다 인간이 작성한 그래픽에 더 유사한 결과를 생성함을 입증.
- CLiMA 모델의 멀티모달 개선: CLIP 임베딩으로 증강된 CLiMA는 텍스트-이미지 정렬 성능을 추가로 개선하며, 이미지를 입력으로 사용 가능하게 함으로써 성능 향상을 달성.
- 일반화 능력 검증: 모든 모델이 양호한 일반화 성능을 보이며 과도한 암기(memorization) 문제가 없음을 입증. 반면 GPT-4와 Claude 2는 더 단순한 결과를 생성하며 입력 캡션을 그대로 이미지에 복사하는 퇴화된 솔루션(degenerate solution)을 생성하는 경향을 보임.