Essence
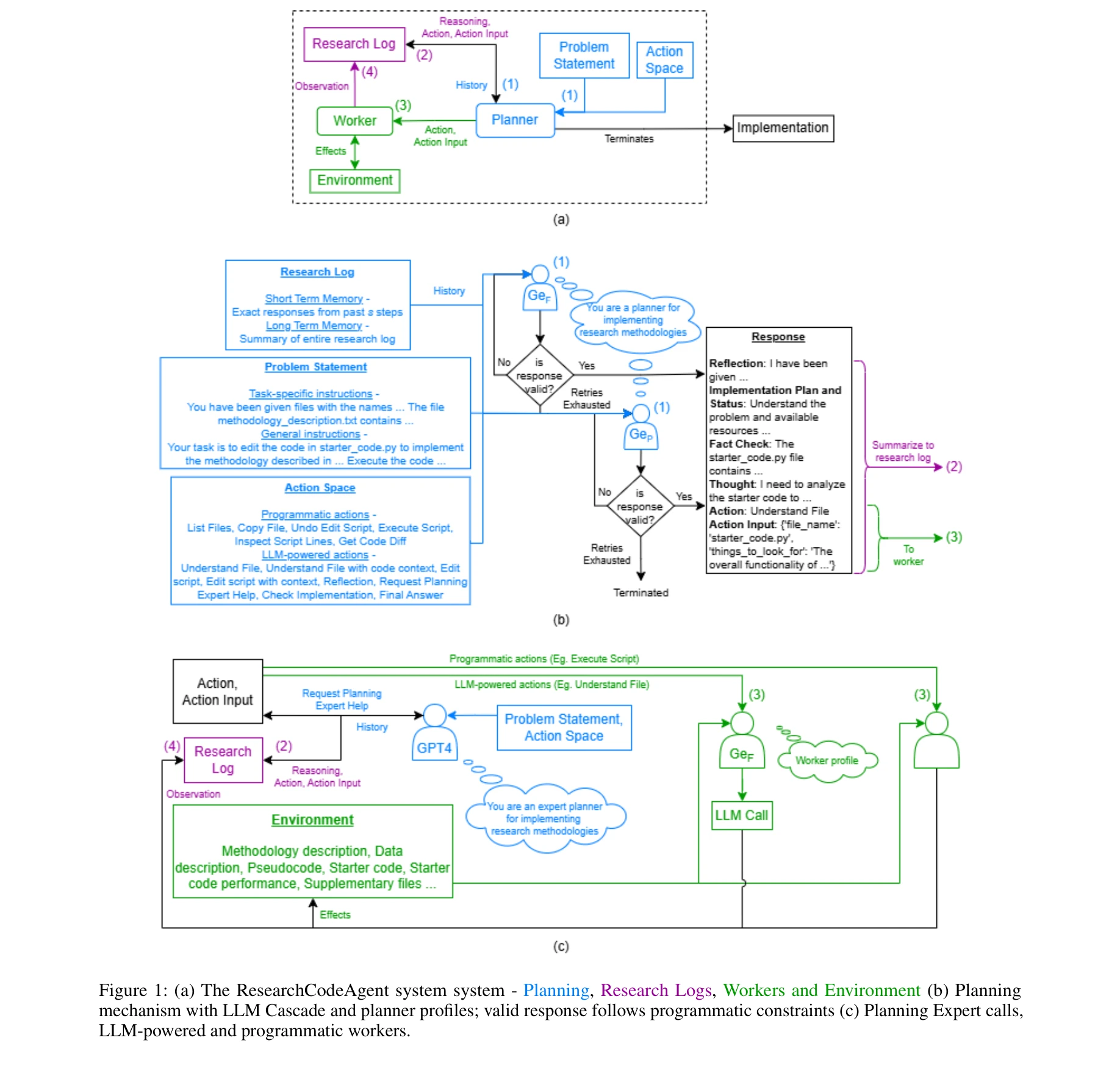
ResearchCodeAgent 시스템 아키텍처: (a) 계획(Planning), 연구 로그(Research Logs), 워커(Workers), 환경(Environment), (b) LLM 캐스케이드를 포함한 계획 메커니즘, (c) 전문가 호출 및 워커 구조
연구 논문에 기술된 머신러닝 방법론을 자동으로 코드로 변환하는 다중 에이전트 LLM 시스템을 제시한다. 상위 레벨의 추상적인 연구 설명과 실제 실행 가능한 구현 간의 격차를 해소하여 연구자의 구현 시간을 단축한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3.5/5 Significance: 3.5/5 Clarity: 3/5 Overall: 3.5/5
총평: ResearchCodeAgent는 머신러닝 연구의 구현 자동화라는 실용적 문제에 처음 정면으로 도전한 점과 45%대의 성공률에서 가능성을 보여줍니다. 다만 평가 범위의 협소함, 통계적 검증 부재, 그리고 여전히 높은 수정 필요율(34%)은 실제 배포 전 강화가 필요함을 시사합니다. 워크숍 논문으로서의 가치는 충분하지만, AI4Research 커뮤니티의 구체적 피드백과 추가 실험을 통한 정교화가 권장됩니다.