Achievement
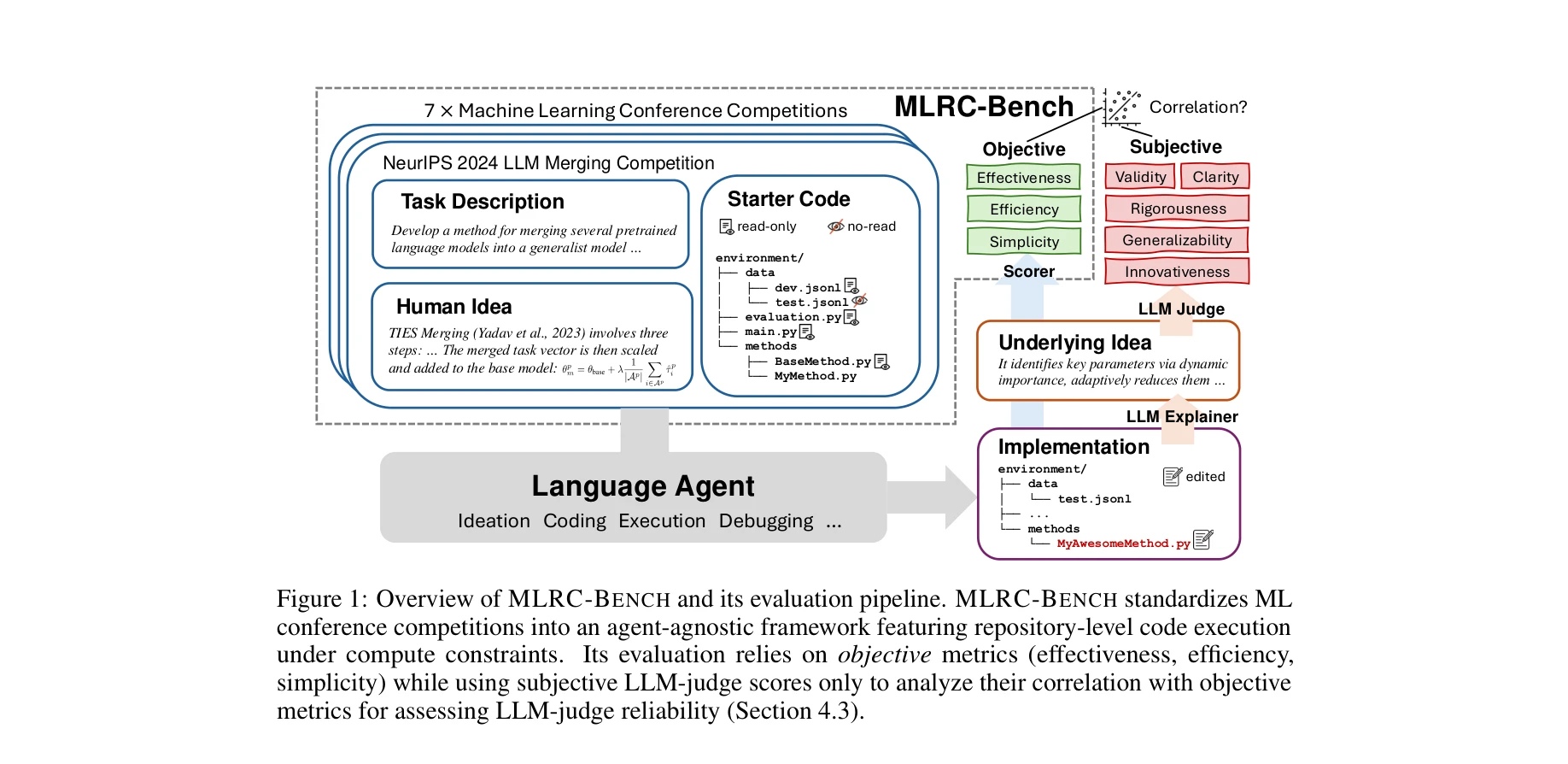
MLRC-BENCH는 ML 학회 경쟁을 에이전트-무관(agent-agnostic) 프레임워크로 표준화하며, 계산 제약 하에서 저장소 수준 코드 실행과 객관적 메트릭 기반 평가를 제공한다.
- 성과 1: 최고 성능 에이전트(gemini-exp-1206/MLAB)도 기준선과 최상 인간 참가자 점수 간 격차의 9.3%만 축소
- 7개 작업 평균적으로 현저한 성능 개선 실패를 입증
- 성과 2: LLM 판사의 참신성 평가와 실제 성능 간 미정렬 규명
- 주관적 평가의 신뢰성 결여 명시적 증명
- 객관적 메트릭(정확성, 효율성)과 LLM 평가(혁신성, 간결성) 간 낮은 상관관계
- 성과 3: 동적 벤치마크 설계로 미래 ML 경쟁 지속 통합 가능하게 구축