저자: Patrick Tser Jern Kon, Jiachen Liu, Xinyi Zhu, Qiuyi Ding, Jingjia Peng, Jiarong Xing, Yibo Huang, Yiming Qiu, Jayanth Srinivasa, Myungjin Lee, Mosharaf Chowdhury, Matei Zaharia, Ang Chen | 날짜: 2025 | DOI: arXiv:2505.24785
Essence

EXP-Bench는 AI 에이전트가 동료 심사 논문에서 추출한 완전한 연구 실험을 수행할 수 있는지를 평가하는 벤치마크로, 연구 질문으로부터 가설 수립, 실험 설계, 구현, 실행, 결론 도출까지의 전체 과정을 평가한다.
AI가 완전한 종료-대-종료(end-to-end) 연구 실험을 수행할 수 있는 능력을 체계적으로 평가하기 위해 EXP-Bench 벤치마크를 제시하며, NeurIPS/ICLR 논문 461개 작업에서 현재 AI 에이전트들이 0.5%의 완전 실험 성공률에 그치고 있음을 보였다.
Achievement

ICLR 2024 MogaNet 논문에서 추출한 단일 연구 작업의 예시로, 연구 질문, 고수준 방법 설명, 스타터 코드를 제공받는 형태를 보여준다.
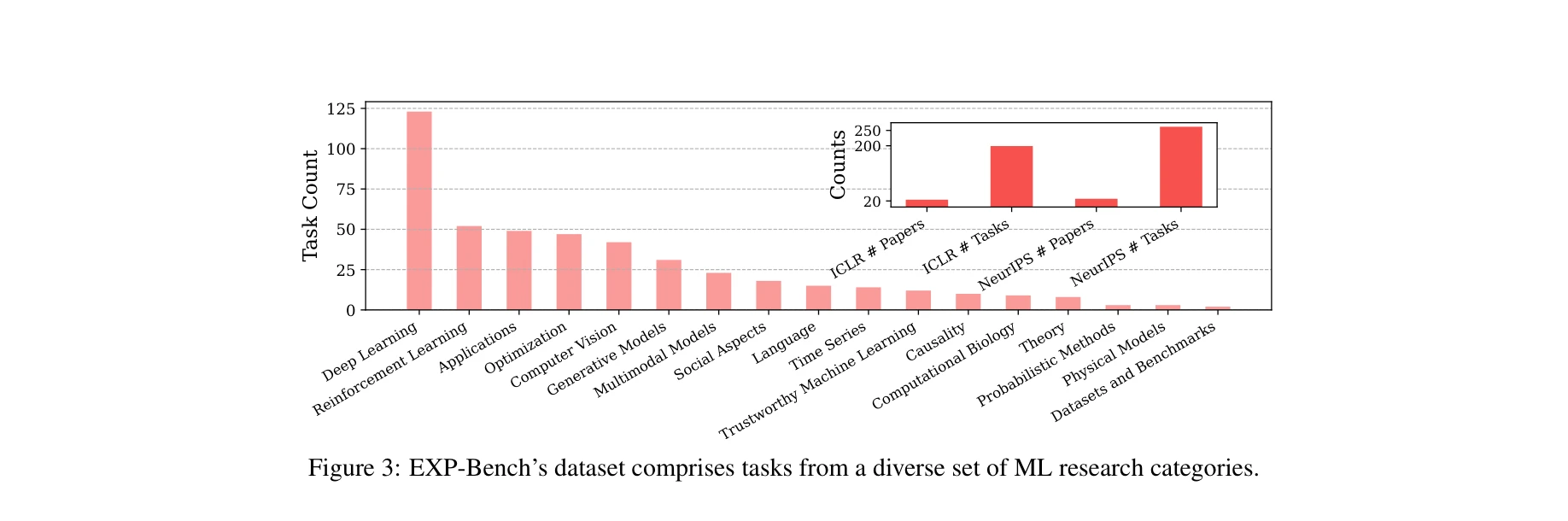
EXP-Bench 데이터셋은 Deep Learning, Reinforcement Learning, Computer Vision, Generative Models 등 다양한 ML 연구 분야에서 균형잡힌 작업들로 구성되어 있으며, NeurIPS(53%)와 ICLR(47%)에서 추출되었다.
- 포괄적 벤치마크 구성: NeurIPS/ICLR 2024의 51개 논문에서 461개의 연구 작업(12,737개 세분화된 부분 작업)을 추출하여, 컴퓨터 비전, NLP, 강화학습 등 다양한 AI 하위분야를 포함한 벤치마크 구축
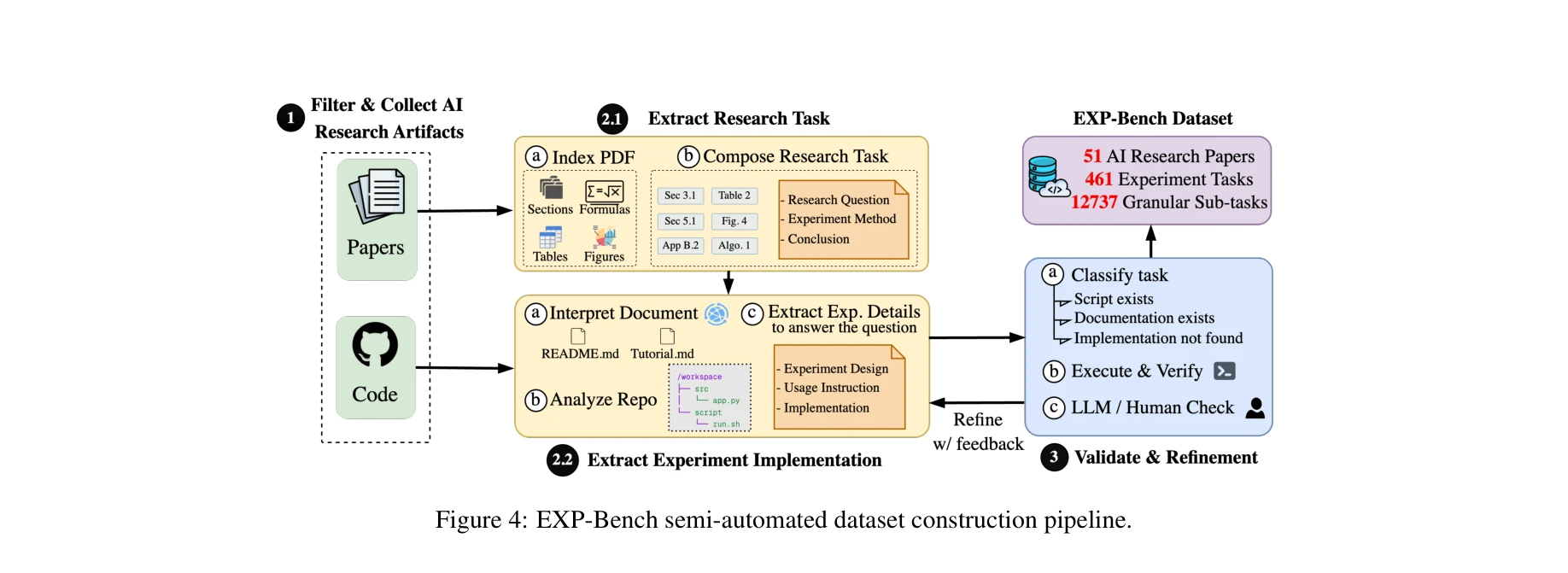
- 확장 가능한 반자동화 파이프라인: 소스 선택/필터링 → 실험 절차 추출 → 구현 추출의 3단계로 논문과 코드베이스에서 산재된 세부정보를 체계적으로 추출하며, 실행 기반 검증으로 기능성을 보장
- 심층 평가 분석: 설계(design), 구현(implementation), 실행(execution), 결론(conclusion)의 4개 핵심 단계 평가를 통해 OpenHands와 IterativeAgent 등 최신 에이전트의 한계를 정량화:
- 설계 정확도: 20-35%
- 실행 가능한 완전 실험: 0.5%
- 설계 변수 오분류: 16.1%
- 필수 구현 요소 누락: 39.7%
- 환경/의존성 오설정: 29.4%