저자: Samuel Schmidgall, Yusheng Su, Ze Wang, Ximeng Sun, Jialian Wu, Xiaodong Yu, Jiang Liu, Michael Moor, Zicheng Liu, Emad Barsoum | 날짜: 2025-06-17 | DOI: 10.48550/arXiv.2501.04227
Essence

Agent Laboratory는 인간의 연구 아이디어를 입력받아 특화된 LLM 에이전트 파이프라인을 통해 연구 보고서와 코드 저장소를 생성한다.
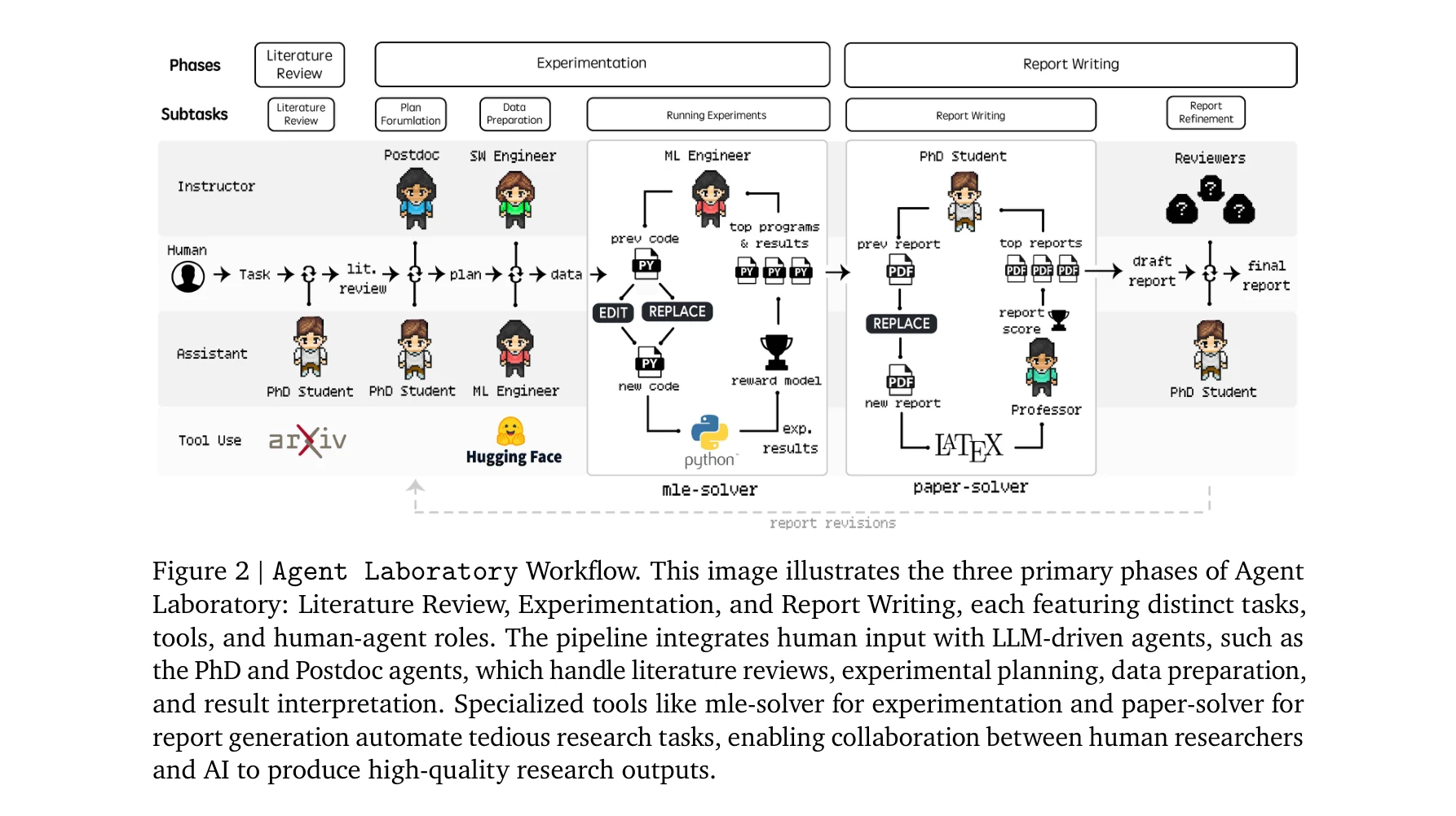
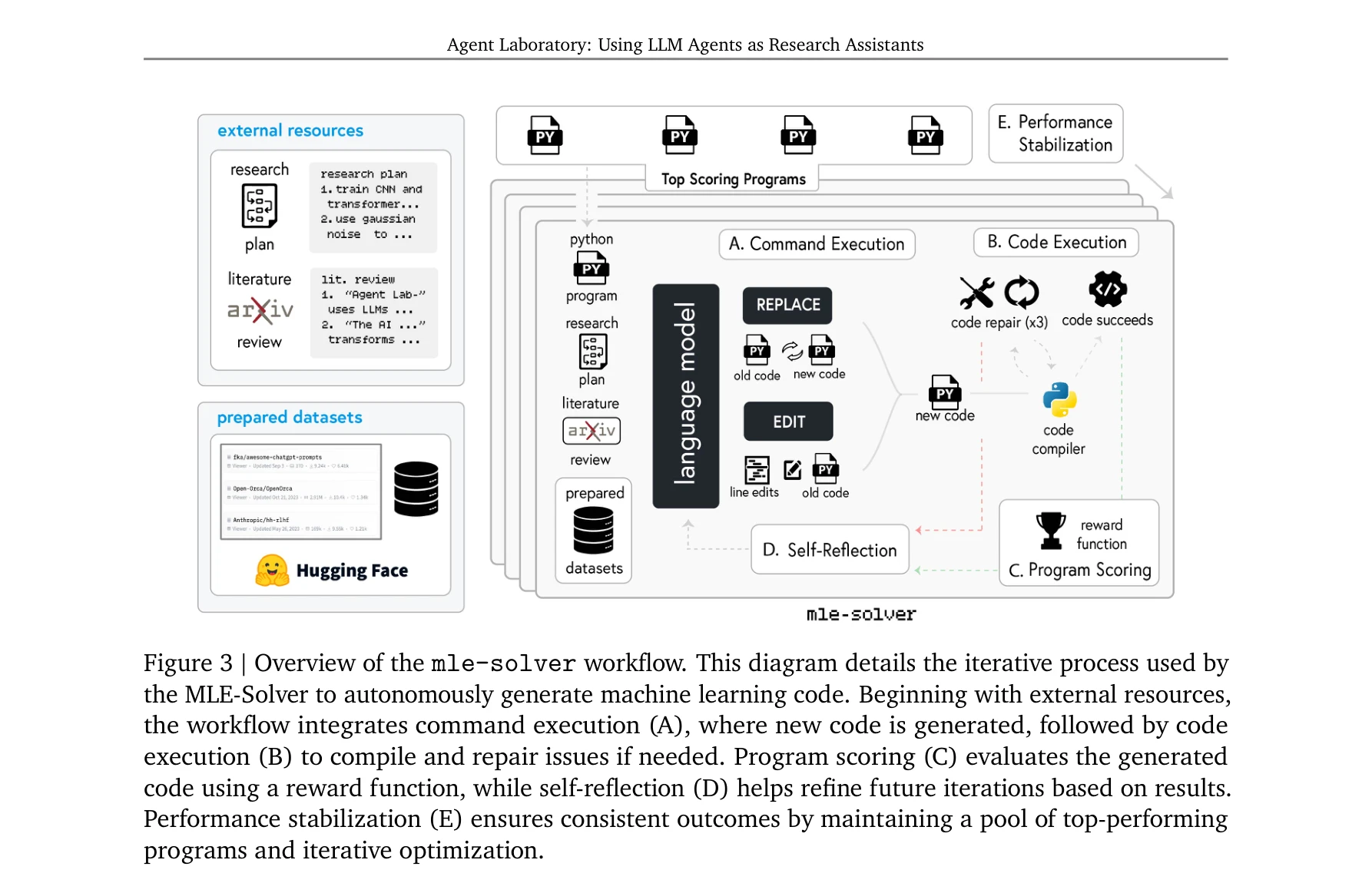
Agent Laboratory는 인간의 연구 아이디어 실행을 지원하는 자율적 LLM 기반 프레임워크로, 문헌 검토, 실험 수행, 보고서 작성의 세 단계를 거쳐 완전한 연구 성과물을 생성한다. 기존 자동화 연구 방법 대비 84% 비용 감축을 달성하면서도 높은 품질의 기계학습 연구를 수행할 수 있음을 보여준다.
Evaluation
총평: Agent Laboratory는 인간의 창의성을 존중하면서 LLM 에이전트의 자동화 능력을 활용하는 실용적이고 경제적인 연구 지원 시스템을 제시한다. 특히 co-pilot 모드와 비용 효율성은 실질적 기여도가 높으나, 생성된 연구의 과학적 영향력, 평가 방법론의 신뢰성, 다양한 과학 분야로의 일반화 가능성 측면에서 추가 검증과 개선이 요구된다.