Essence
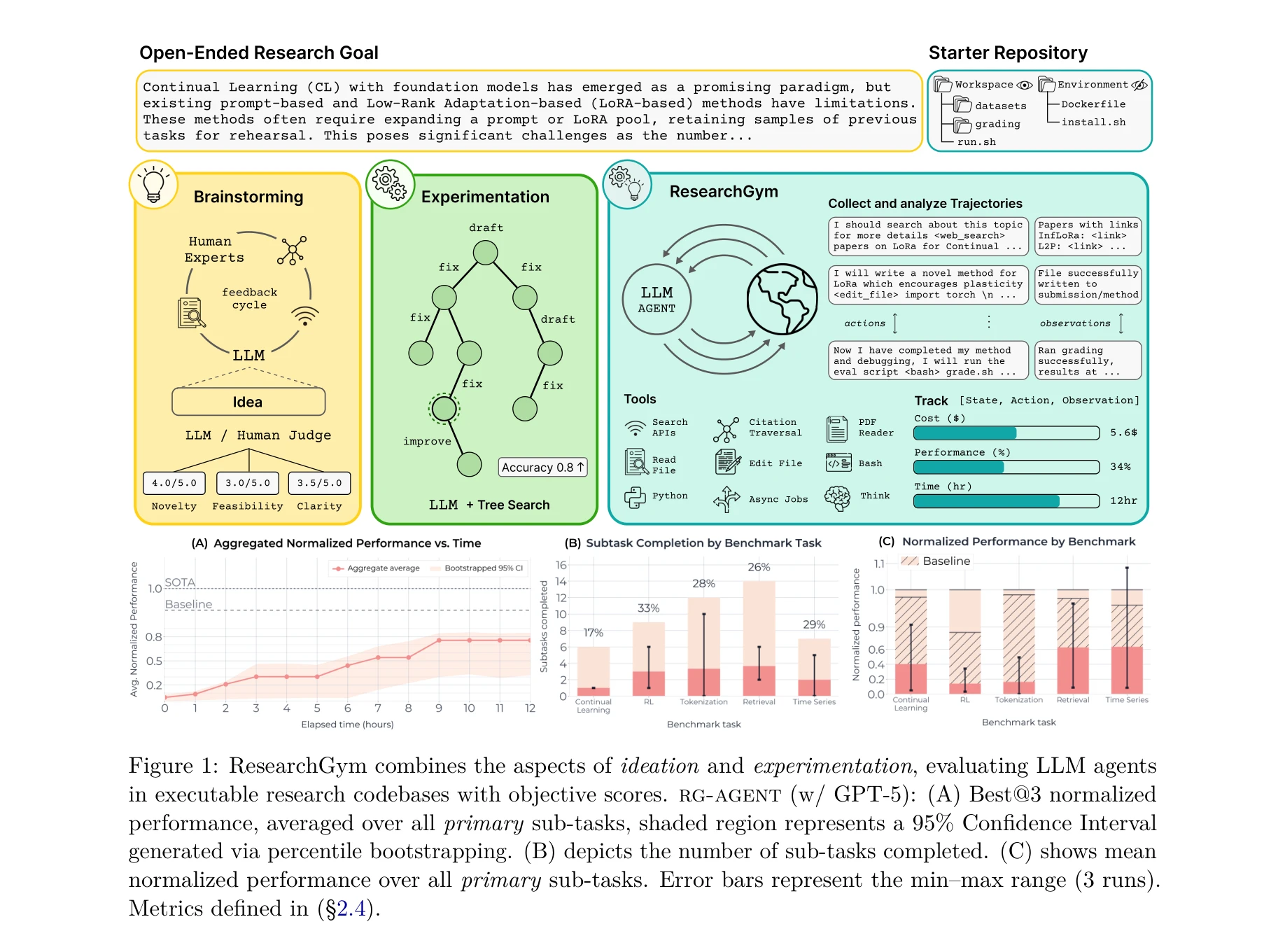
그림 1: ResearchGym은 아이디어 제시와 실험 수행을 결합하여 LLM 에이전트를 객관적 점수로 평가
본 논문은 실제 AI 연구 논문의 저장소를 기반으로 엔드-투-엔드 연구 루프를 평가하는 벤치마크 ResearchGym을 제시한다. GPT-5 기반 에이전트가 인상적인 성능을 보이기도 하지만 신뢰성이 매우 낮다는 "능력-신뢰성 격차(capability-reliability gap)"를 실증적으로 입증한다.
저자: Aniketh Garikaparthi, Manasi Patwardhan, Arman Cohan | 날짜: 2026-02-16 | DOI: N/A
그림 1: ResearchGym은 아이디어 제시와 실험 수행을 결합하여 LLM 에이전트를 객관적 점수로 평가
본 논문은 실제 AI 연구 논문의 저장소를 기반으로 엔드-투-엔드 연구 루프를 평가하는 벤치마크 ResearchGym을 제시한다. GPT-5 기반 에이전트가 인상적인 성능을 보이기도 하지만 신뢰성이 매우 낮다는 "능력-신뢰성 격차(capability-reliability gap)"를 실증적으로 입증한다.
그림 2: 1,387개 논문에서 자동 필터링과 인간 평가를 통해 5개 작업 선정
그림 3: 벤치마크 구성 과정: LLM 기반 정보 추출 → 휴리스틱 필터링 → 인간 QA
태스크 설계:
벤치마크 구성 파이프라인:
오염 인식 설계:
평가 메커니즘:
에이전트 아키텍처:
한계:
후속 연구 방향:
총평: 본 논문은 AI 에이전트의 실제 연구 수행 능력 평가를 위한 첫 번째 체계적 벤치마크를 제시함으로써 학계에 중요한 기여를 한다. 특히 객관적 실행 기반 평가, 오염 인식 설계, 접근성 있는 인프라 제공은 우수하나, 제한된 작업 규모와 현상적 실패 분석 수준은 향후 보완이 필요하다. 최신 LLM이 가끔 SOTA 성능에 도달하지만 대체로 신뢰할 수 없다는 발견은 에이전트 개발 커뮤니티에 중대한 경종을 울린다.