Essence
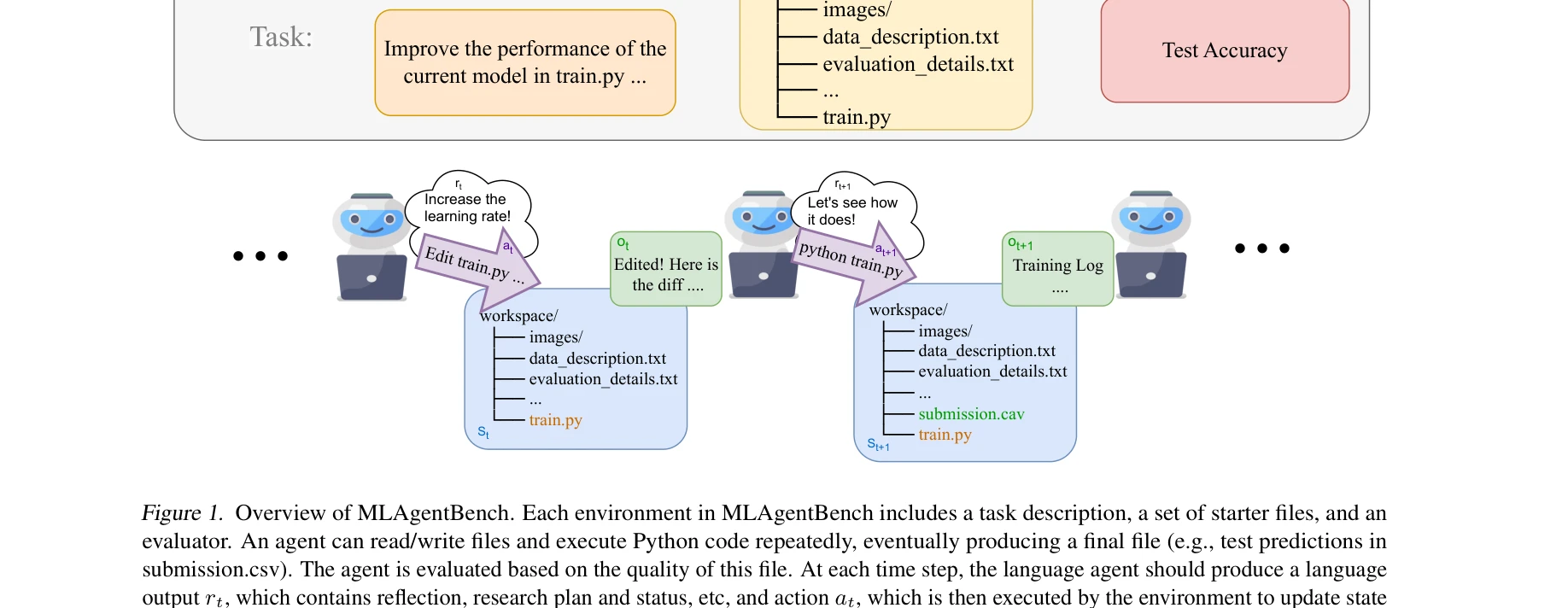
MLAgentBench의 개요. 각 환경은 작업 설명, 시작 파일, 평가기를 포함하며, 에이전트는 파일을 읽고/쓰고 Python 코드를 반복적으로 실행하여 최종 제출 파일을 생성
본 논문은 머신러닝 실험을 자동으로 수행할 수 있는 언어 모델 기반 에이전트를 평가하기 위한 벤치마크(MLAgentBench)를 제안한다. 13개의 다양한 ML 작업을 통해 최신 언어 모델들의 ML 실험 수행 능력을 체계적으로 평가한다.
저자: Qian Huang, Jian Vora, Percy Liang, Jure Leskovec | 날짜: 2023 | DOI: arXiv:2310.03302
MLAgentBench의 개요. 각 환경은 작업 설명, 시작 파일, 평가기를 포함하며, 에이전트는 파일을 읽고/쓰고 Python 코드를 반복적으로 실행하여 최종 제출 파일을 생성
본 논문은 머신러닝 실험을 자동으로 수행할 수 있는 언어 모델 기반 에이전트를 평가하기 위한 벤치마크(MLAgentBench)를 제안한다. 13개의 다양한 ML 작업을 통해 최신 언어 모델들의 ML 실험 수행 능력을 체계적으로 평가한다.

LM 기반 에이전트의 개요. 각 단계에서 프롬프트와 문맥은 단계별 반영(reflection), 고차원 계획, 사실 확인, 추론을 포함
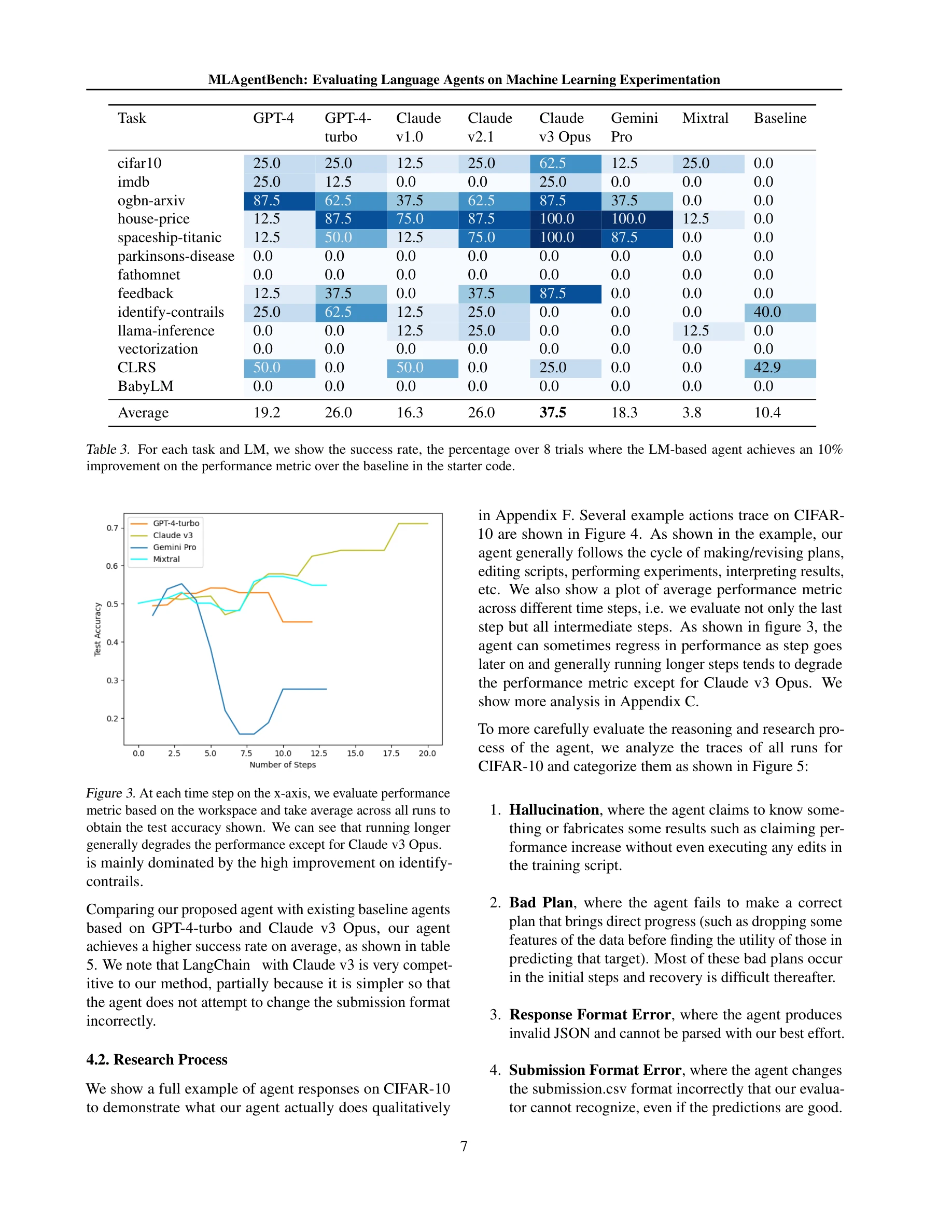
시간 스텝별 성능 평가
총평: 본 논문은 언어 모델 기반 ML 자동화의 가능성과 한계를 체계적으로 평가하는 첫 종합 벤치마크를 제시하여 학계에 중요한 기준점을 제공한다. 다양한 작업 범위와 포괄적 모델 비교는 강점이나, 37.5%의 제한적 성공률과 시간 외삽 과제의 대규모 실패는 현재 언어 모델 에이전트의 신뢰성에 대한 현실적인 인식을 제시한다. 향후 계획 수립 및 재계획 메커니즘 연구에 방향성을 제시하는 가치 있는 기초 연구이다.