저자: Xueyu Hu, Ziyu Zhao, Shuang Wei, Ziwei Chai, Qianli Ma, Guoyin Wang, Xuwu Wang, Jing Su, Jingjing Xu, Ming Zhu, Yao Cheng, Jianbo Yuan, Jiwei Li, Kun Kuang, Yang Yang, Hongxia Yang, Fei Wu | 날짜: 2024 | DOI: arXiv:2401.05507
Essence
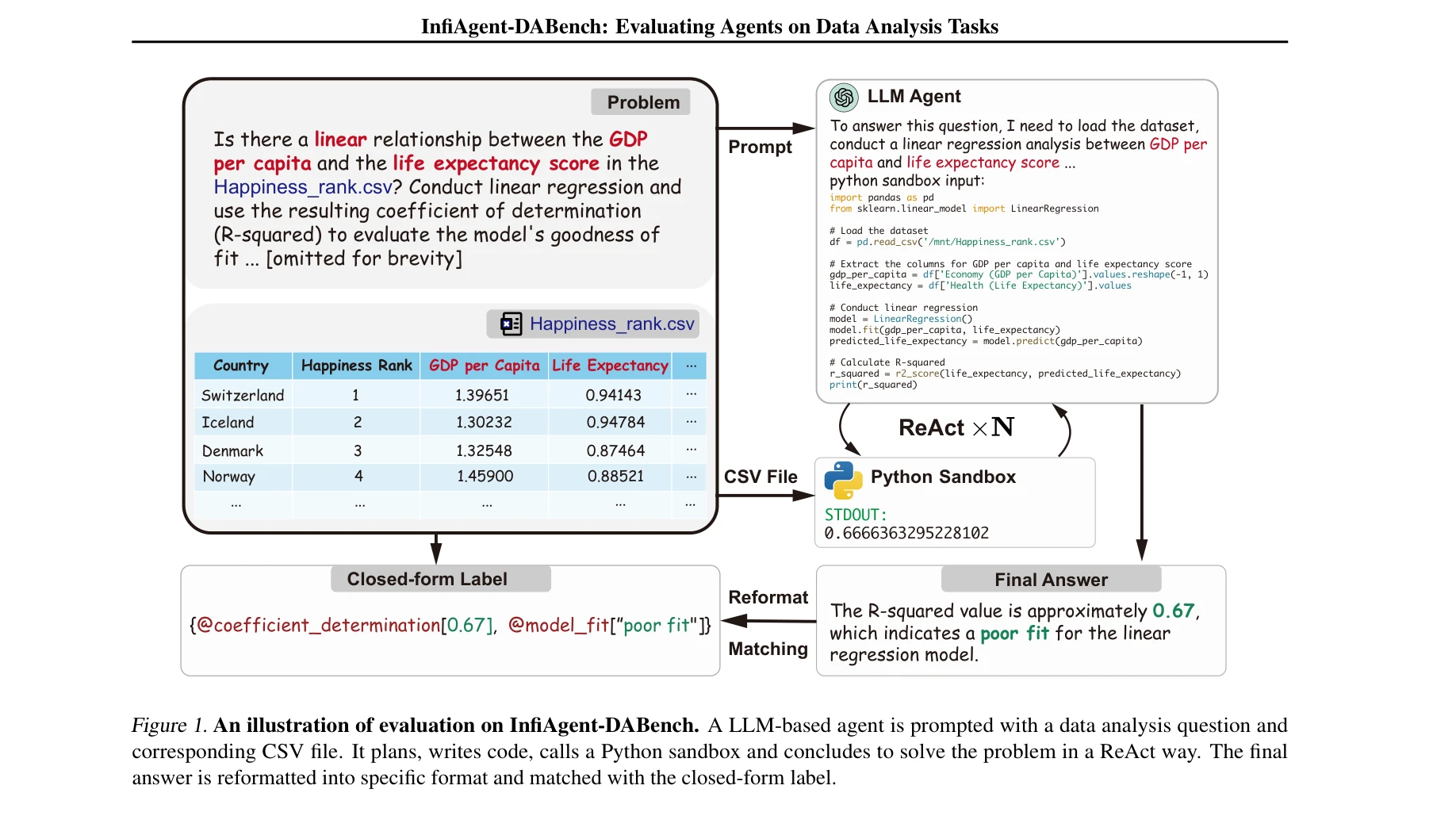
LLM 기반 에이전트가 CSV 파일을 입력받아 ReAct 방식으로 코드를 작성, 실행하고 결과를 도출하는 데이터 분석 태스크의 평가 프로세스
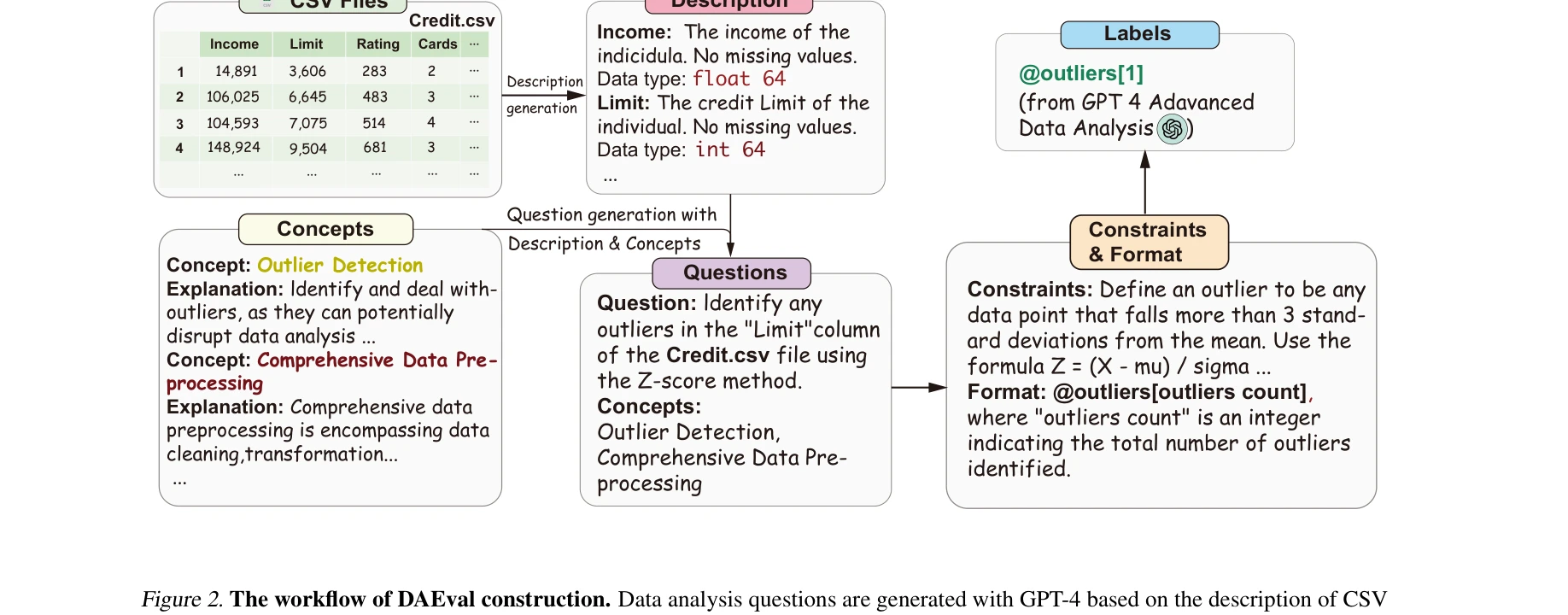
본 논문은 LLM 기반 에이전트의 데이터 분석 능력을 평가하기 위한 최초의 종합 벤치마크 InfiAgent-DABench를 제안한다. 257개의 폐쇄형(closed-form) 데이터 분석 질문과 52개의 CSV 파일로 구성된 DAEval 데이터셋과, 이를 평가하기 위한 에이전트 프레임워크를 제공한다.
Evaluation
총평: 본 논문은 LLM 기반 에이전트의 데이터 분석 능력을 평가하기 위한 최초의 종합 벤치마크를 제시하며, 포맷 프롬팅을 통한 폐쇄형 평가 방법론이 실용적이고 창의적이다. 광범위한 LLM 벤치마킹과 오픈소스 DAAgent 개발로 실제 임팩트를 제공하지만, 평가 방식의 표현 한계와 데이터셋 규모 제약이 개선될 필요가 있다.