Essence
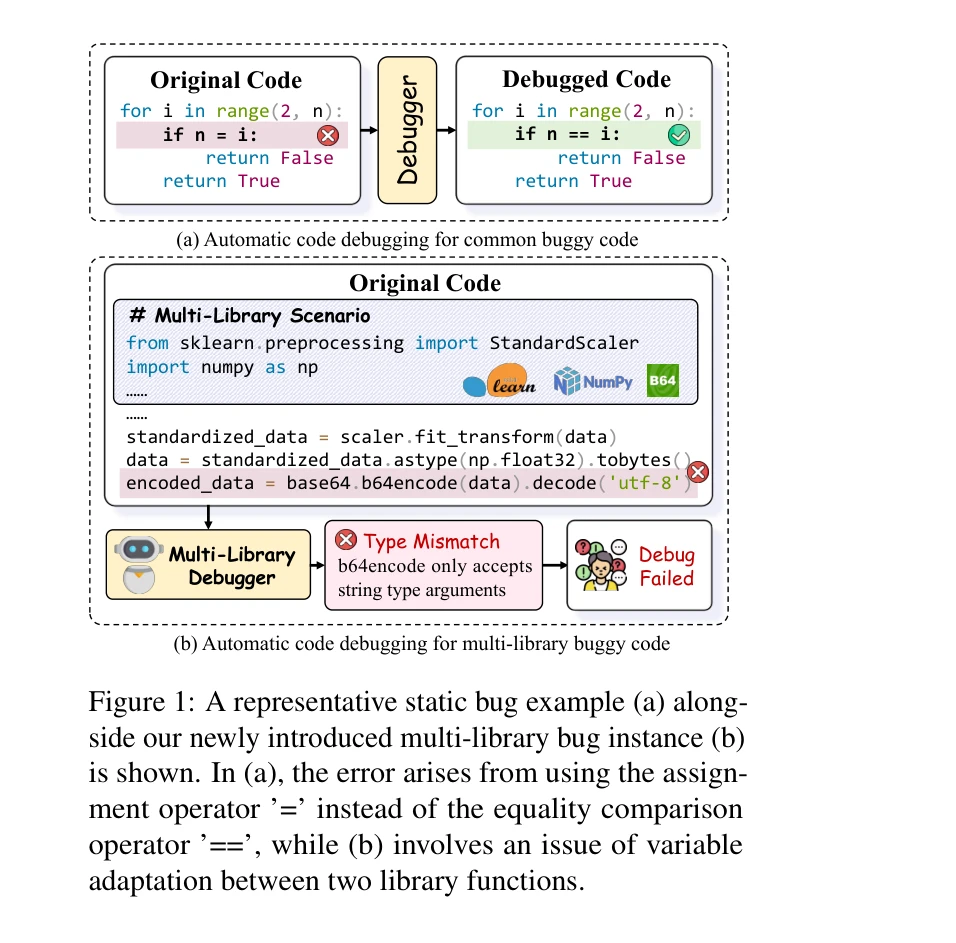
다중 라이브러리 코드 디버깅의 예시: (a) 단순 정적 버그 vs (b) 라이브러리 간 변수 적응 문제
본 논문은 실제 소프트웨어 개발 환경에서 흔히 나타나는 다중 라이브러리 시나리오에서의 코드 디버깅을 체계적으로 평가하기 위한 MLDebugging 벤치마크를 제시한다. 126개의 Python 라이브러리를 포함하고 7가지 버그 유형으로 분류된 1,175개의 샘플로 구성되어 있다.
저자: Jinyang Huang, Xiachong Feng, Qiguang Chen, Hanzhang Zhao, Zheng Cheng, Jie Bai, Jingxuan Zhou, Min Li, L. Q. Qin | 날짜: 2025 | DOI: N/A
다중 라이브러리 코드 디버깅의 예시: (a) 단순 정적 버그 vs (b) 라이브러리 간 변수 적응 문제
본 논문은 실제 소프트웨어 개발 환경에서 흔히 나타나는 다중 라이브러리 시나리오에서의 코드 디버깅을 체계적으로 평가하기 위한 MLDebugging 벤치마크를 제시한다. 126개의 Python 라이브러리를 포함하고 7가지 버그 유형으로 분류된 1,175개의 샘플로 구성되어 있다.
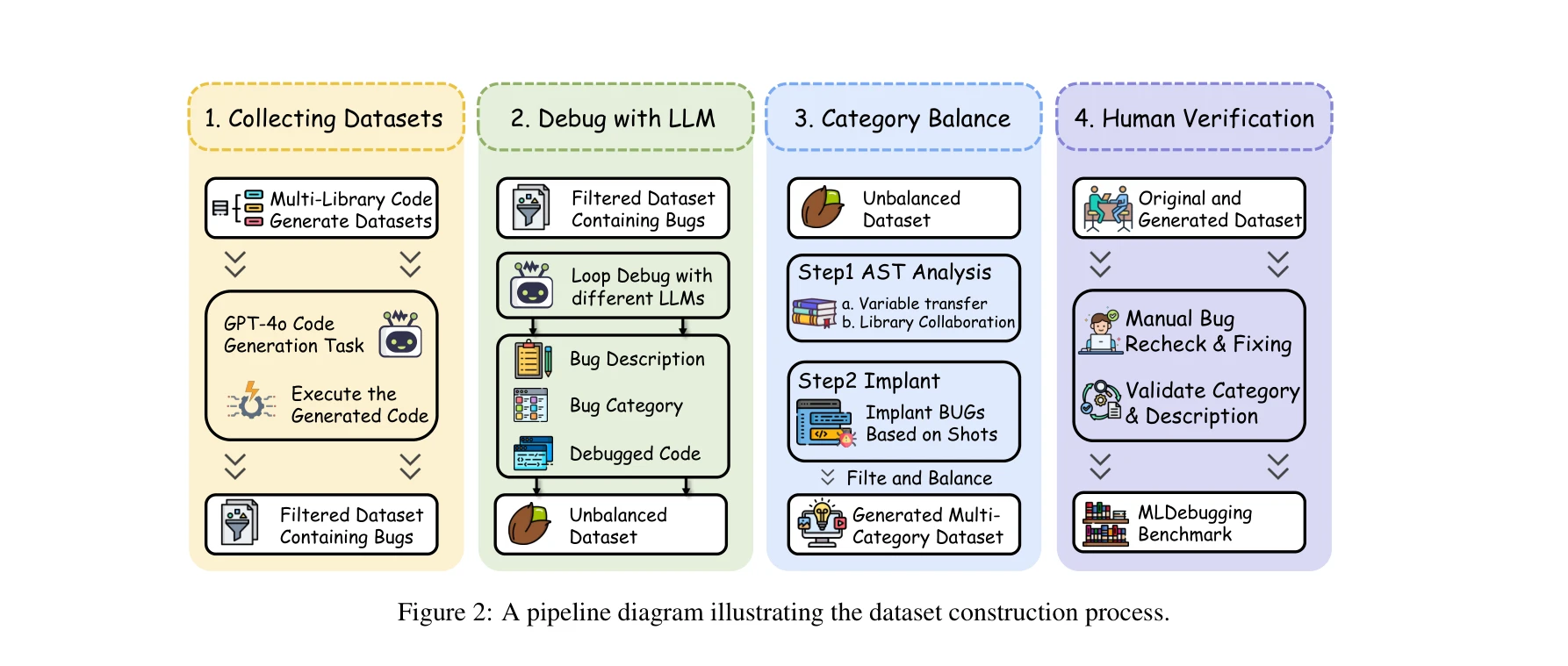
데이터셋 구축 파이프라인: (1) 데이터셋 수집, (2) LLM을 통한 디버깅, (3) 카테고리 균형 조정, (4) 수동 검증
데이터셋 구축의 4단계 프로세스
1. 소스 코드 수집
2. LLM을 통한 어노테이션 및 디버깅
3. 버그 카테고리 균형 조정
4. 품질 제어
총평: MLDebugging은 코드 디버깅 연구의 중요한 공백인 다중 라이브러리 시나리오를 처음으로 체계적으로 다루는 실질적인 기여를 한다. 엄격한 데이터 수집 및 품질 관리 프로세스와 포괄적인 LLM 평가를 통해 이 분야의 토대를 마련했으나, 언어 제한, 샘플 규모, 버그 현실성 검증 측면에서 개선 여지가 있다.