Achievement

Figure 1: SciCode 주요 문제가 여러 개의 더 작고 쉬운 부분 문제로 분해되는 구조
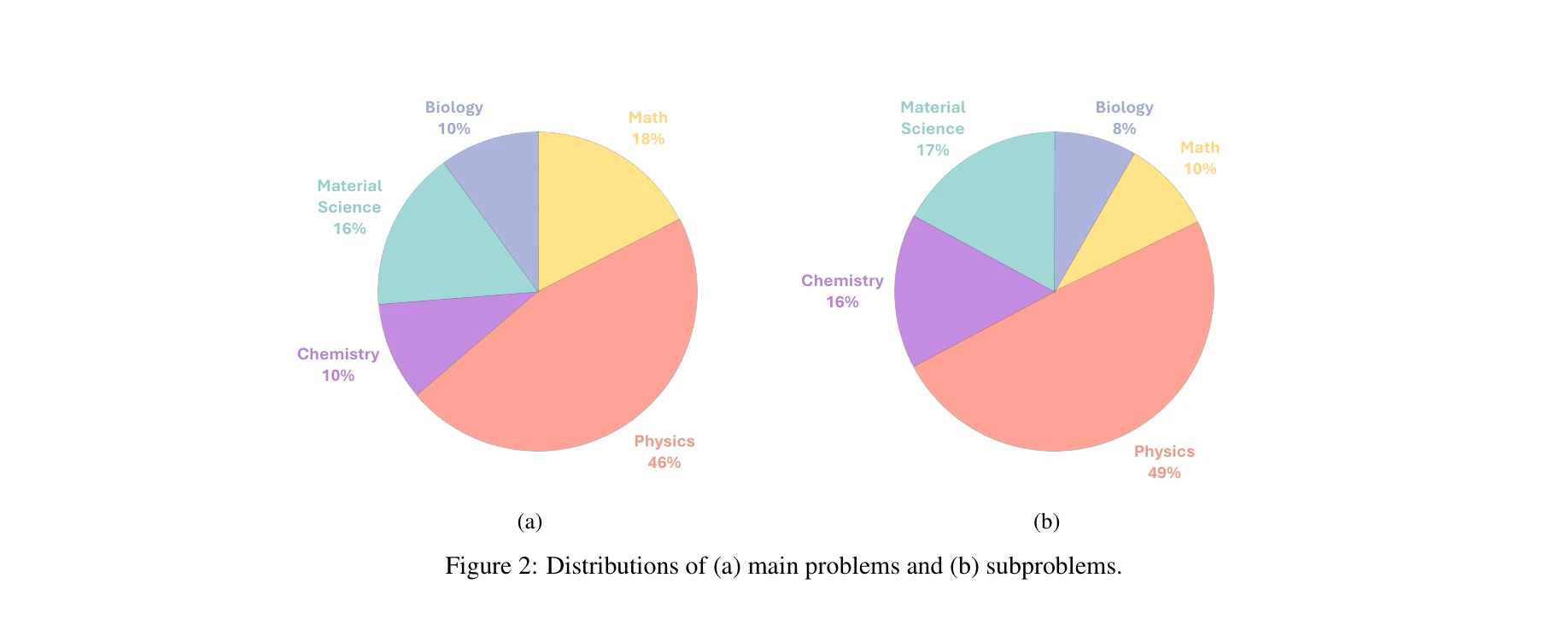
- 포괄적 벤치마크 구성: 80개 주요 문제로부터 338개 부분 문제로 구성된 대규모 벤치마크 개발 (16개 과학 분야, 50개 개발 세트, 288개 테스트 세트)
- 높은 난이도 수준: 최고 성능 모델인 Claude3.5-Sonnet이 가장 현실적인 설정에서 4.6% 문제 해결, 배경 정보 제공 시에도 12.3%에 불과 (GPT-4o는 1.5%, Deepseek-Coder-v2는 3.1%)
- 고품질 주석: 각 문제마다 2명 이상의 박사급 이상 연구자가 검증·개정한 과학 배경 정보, 표준 솔루션, 테스트 케이스 제공