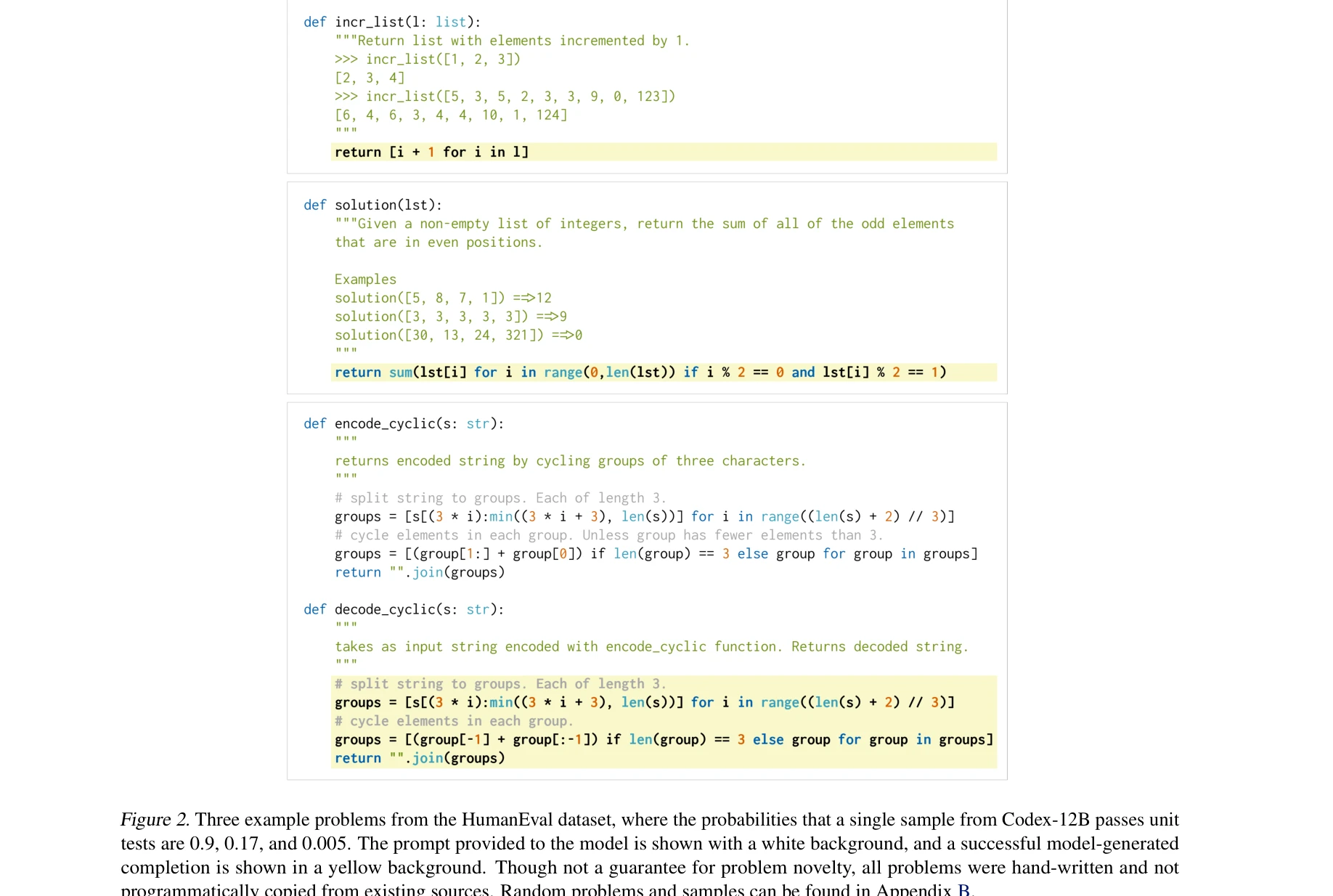
저자: Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Pondé de Oliveira Pinto, Jared Kaplan, Harrison Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder | 날짜: 2021 | DOI: N/A
Essence
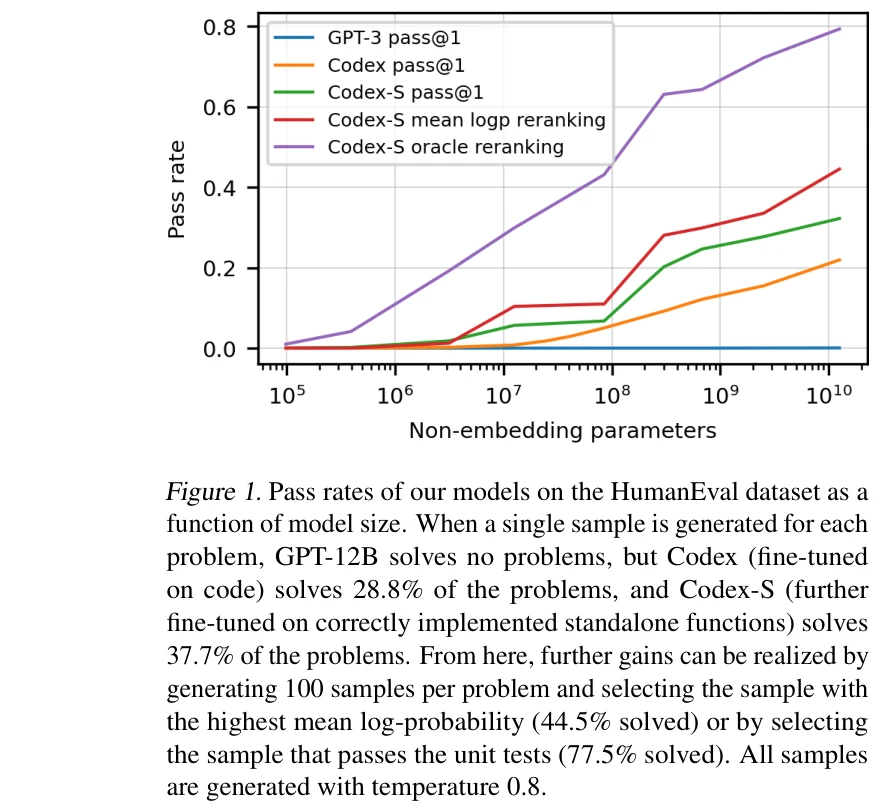
HumanEval 데이터셋에서 모델 크기에 따른 통과율. 단일 샘플 생성 시 Codex-12B는 28.8%, 100개 샘플 생성 후 단위 테스트 통과 샘플 선택 시 77.5% 달성
GitHub 코드로 미세조정된 GPT 기반의 Codex 모델을 제시하고, 새로운 벤치마크인 HumanEval을 통해 함수형 정확성(functional correctness) 기반의 평가 체계를 제안한 논문이다. Codex는 도큐스트링(docstring)으로부터 Python 함수를 생성하는 능력에서 기존 모델들을 크게 능가한다.
How
- 데이터 수집: 2020년 5월 GitHub의 5,400만 공개 저장소에서 수집한 Python 파일(179GB → 필터링 후 159GB). 자동 생성 파일, 장행 코드 제거.
- 미세조정 전략: GPT-3 모델 계열에서 출발(더 빠른 수렴). 사전학습된 자연어 표현 활용이지만, 미세조정 데이터셋 규모가 충분히 크면 성능 향상 제약.
- Codex-S: 올바르게 구현된 독립형 함수(standalone functions)로 추가 미세조정하여 37.7% 해결률 달성 - 도메인 특화의 효과 입증.
- Pass@k 계산:
```
pass@k = 1 - ∏(1 - k/(n-c+i)) for i=1 to k
```
여기서 n=생성 샘플 수, c=정답 샘플 수. 단순 추정 1-(1-p̂)^k는 편향됨을 증명.
- 보안 샌드박스: gVisor 컨테이너 런타임으로 호스트 리소스 에뮬레이션, eBPF 방화벽으로 악의적 네트워크 접근 차단.