Essence

CodeAct와 Text/JSON 액션의 비교: (상) 다양한 액션 형식 간 예시 비교, (하) M3ToolEval 벤치마크에서의 정량적 결과
LLM 에이전트의 액션 공간을 통합하기 위해 실행 가능한 Python 코드를 직접 사용하는 CodeAct 프레임워크를 제안하며, 기존의 JSON/텍스트 기반 액션 방식 대비 최대 20% 높은 성공률을 달성한다.
저자: Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li | 날짜: 2024 | DOI: 10.48550/arXiv.2402.01030
CodeAct와 Text/JSON 액션의 비교: (상) 다양한 액션 형식 간 예시 비교, (하) M3ToolEval 벤치마크에서의 정량적 결과
LLM 에이전트의 액션 공간을 통합하기 위해 실행 가능한 Python 코드를 직접 사용하는 CodeAct 프레임워크를 제안하며, 기존의 JSON/텍스트 기반 액션 방식 대비 최대 20% 높은 성공률을 달성한다.
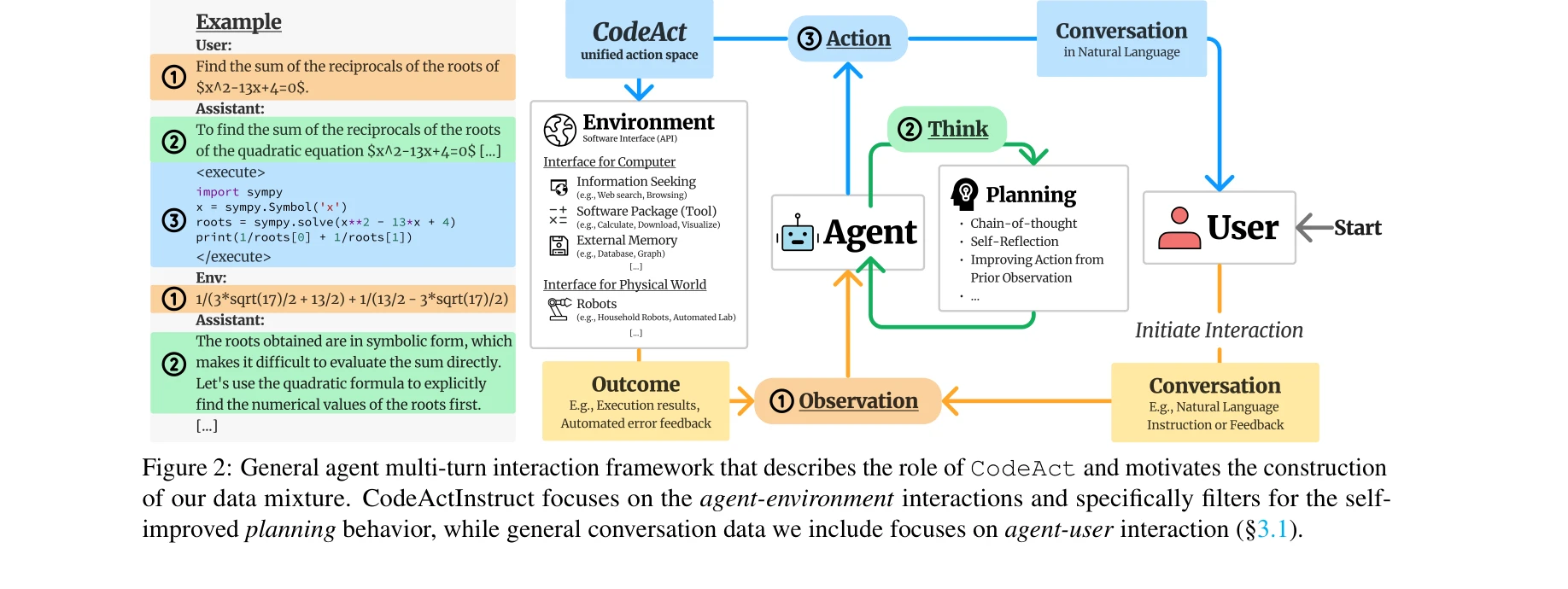
LLM 에이전트의 일반적 다중턴 상호작용 프레임워크: 에이전트, 사용자, 환경의 역할을 나타내며 CodeAct의 역할과 데이터 수집의 동기를 설명한다.

CodeActAgent (Mistral-7b)와의 Python 패키지 다중턴 상호작용 예시: 컨텍스트 내 시연 없이 고도화된 작업 수행
총평: CodeAct는 LLM 에이전트의 액션 공간 표현에 대한 패러다임 전환을 제시하며, 광범위한 실증적 검증과 실용적 에이전트 개발을 통해 높은 실용 가치를 입증했다. 다만 보안, 신뢰성, 프로그래밍 언어 다양성 측면의 개선과 물리적 환경에서의 추가 검증이 필요하다.