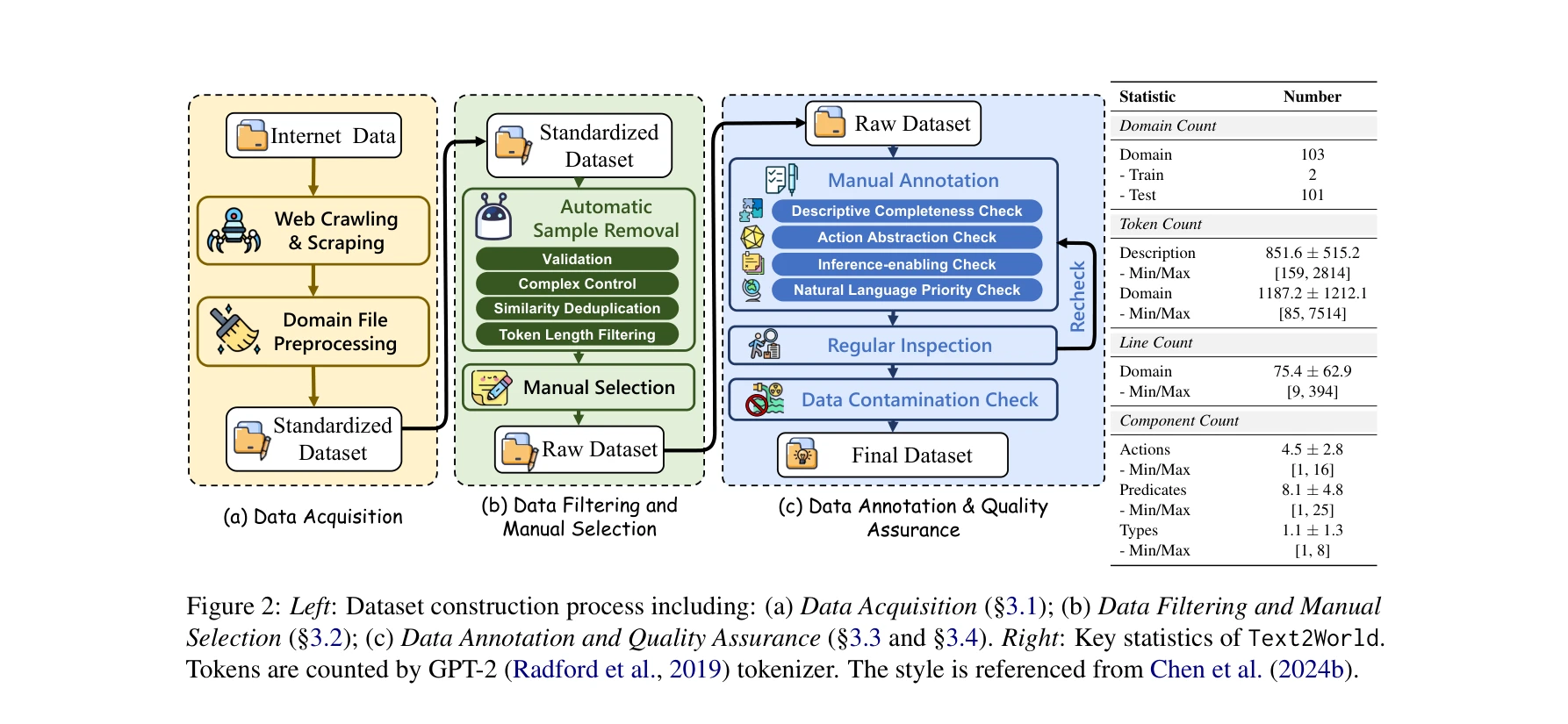
Essence
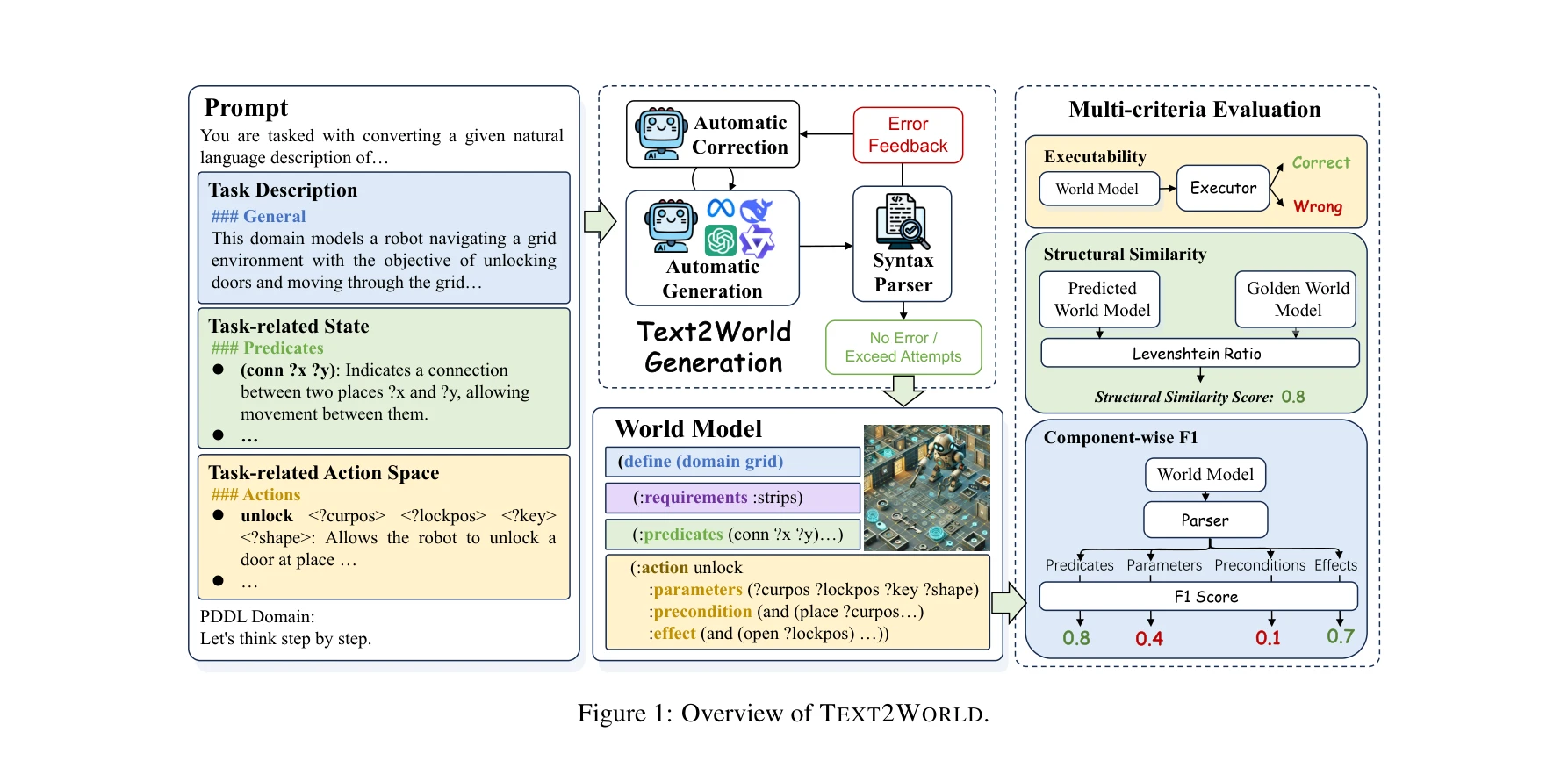
TEXT2WORLD 벤치마크의 전체 파이프라인: 자연언어 설명으로부터 PDDL 도메인 모델 생성, 자동 수정, 다중 기준 평가
대규모 언어모델(LLM)이 자연언어 설명으로부터 기호적 세계 모델(symbolic world model)을 생성할 수 있는지 평가하기 위해 PDDL 기반의 포괄적인 벤치마크 TEXT2WORLD를 제안하고, 수백 개의 다양한 도메인과 실행 기반 평가 지표를 통해 현재 LLM의 세계 모델링 능력이 여전히 제한적임을 밝혔다.