저자: Tianyu Hua, Harper Hua, Violet Xiang, Benjamin Klieger, Sang T. Truong, Weixin Liang, Fan-Yun Sun, Nick Haber (Stanford University) | 날짜: 2025 | DOI: arXiv:2506.02314v1
Essence
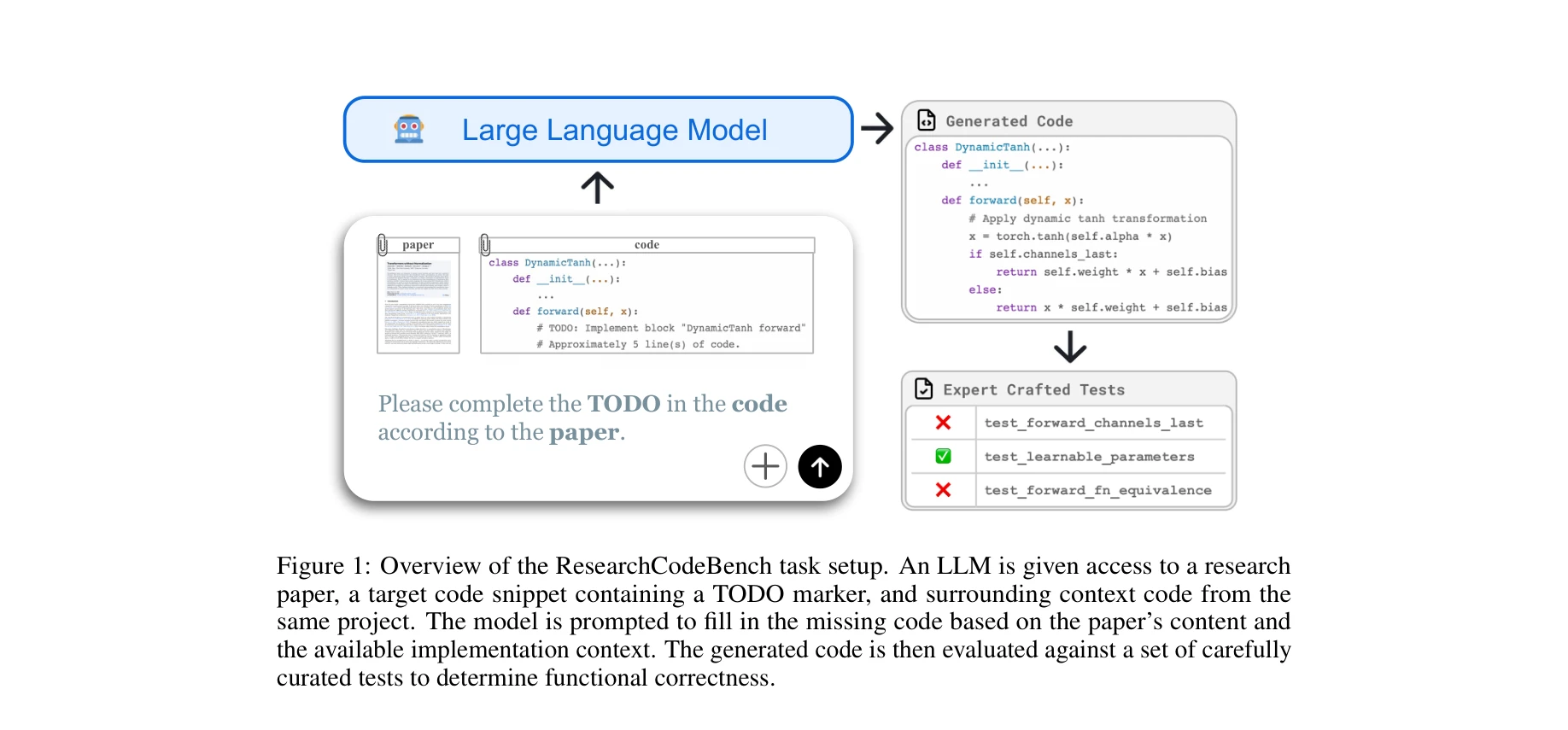
ResearchCodeBench 작업 설정 개요. LLM은 연구 논문, TODO 마커가 포함된 목표 코드 스니펫, 동일 프로젝트의 주변 컨텍스트 코드에 접근하여 누락된 코드를 작성한다.
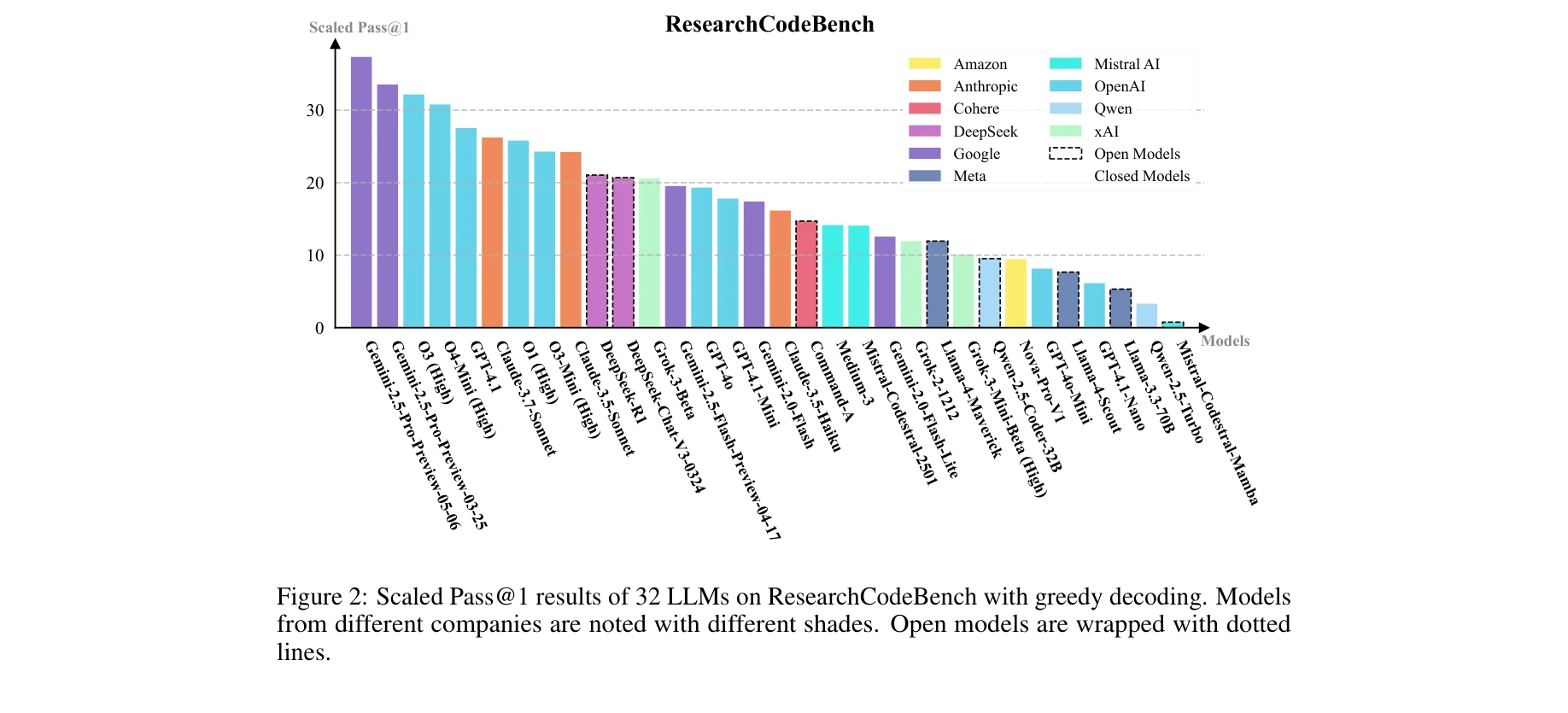
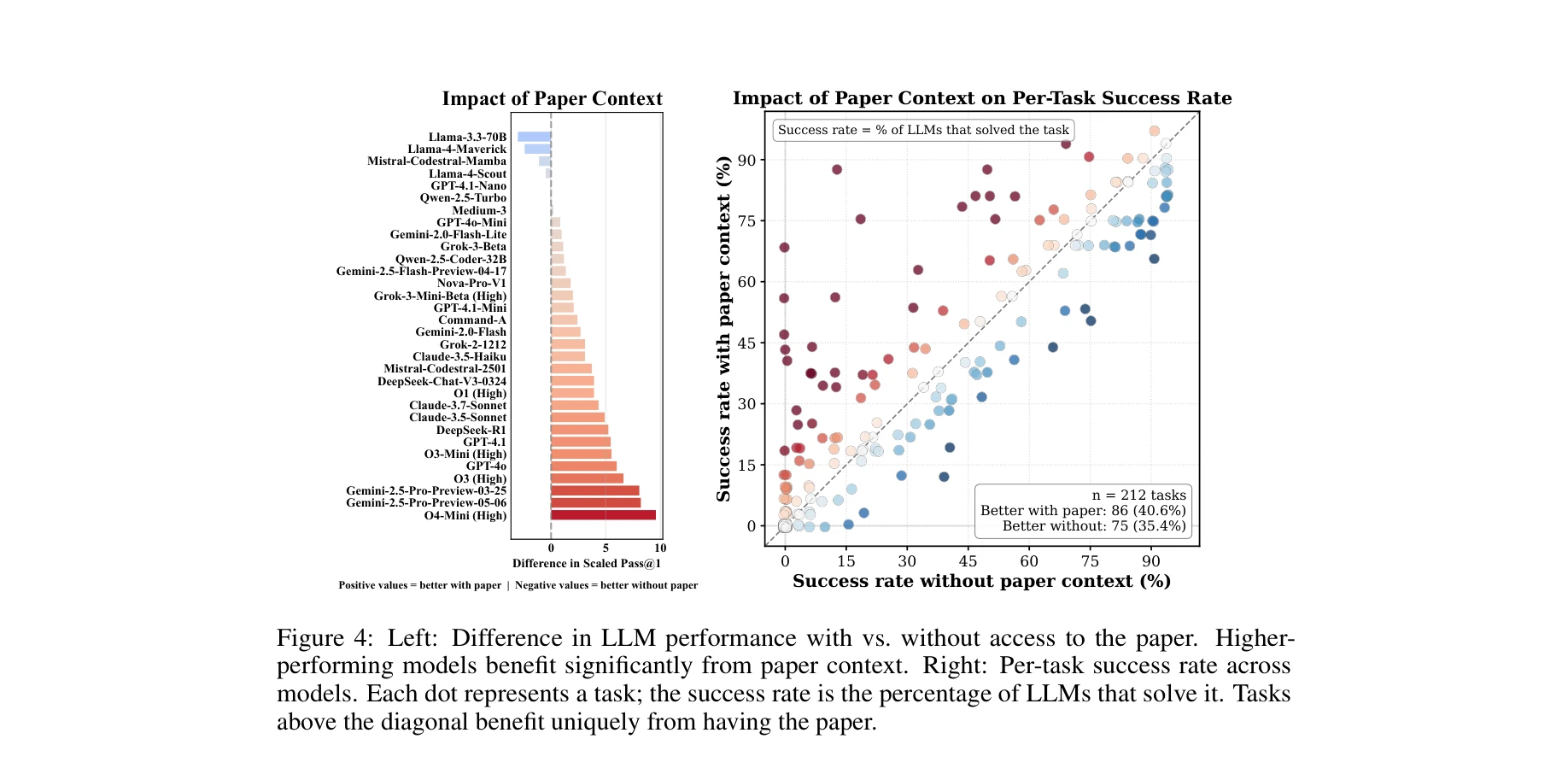
최신 기계학습 연구 논문에서 제시된 새로운 아이디어를 실행 가능한 코드로 변환하는 LLM의 능력을 평가하는 벤치마크로, 2024-2025년 상위 학회(NeurIPS, ICLR, CVPR) 논문 20개로부터 구성된 212개의 코딩 챌린지를 통해 현재 최고 성능 LLM도 40% 미만의 성공률을 보임을 입증한다.
Evaluation
Novelty: 4.5/5 Technical Soundness: 4.5/5 Significance: 4.5/5 Clarity: 4/5 Overall: 4.4/5
총평: ResearchCodeBench는 LLM의 진정한 혁신 코드 구현 능력을 평가하는 시간-민감하고 객관적인 벤치마크를 제시함으로써, AI 보조 과학 연구의 현실적 한계를 규명하고 향후 LLM 개선 방향의 기준점을 제공하는 가치 있는 기여이다.