저자: Ming Zhang, Yujiong Shen, Zelin Li, Huayu Sha, Binze Hu, Yuhui Wang, Chenhao Huang, Shichun Liu, Jingqi Tong, Changhao Jiang, Mingxu Chai, Zhiheng Xi, Shihan Dou, Tao Gui, Qi Zhang, Xuanjing Huang | 날짜: 2025 | DOI: -
Essence
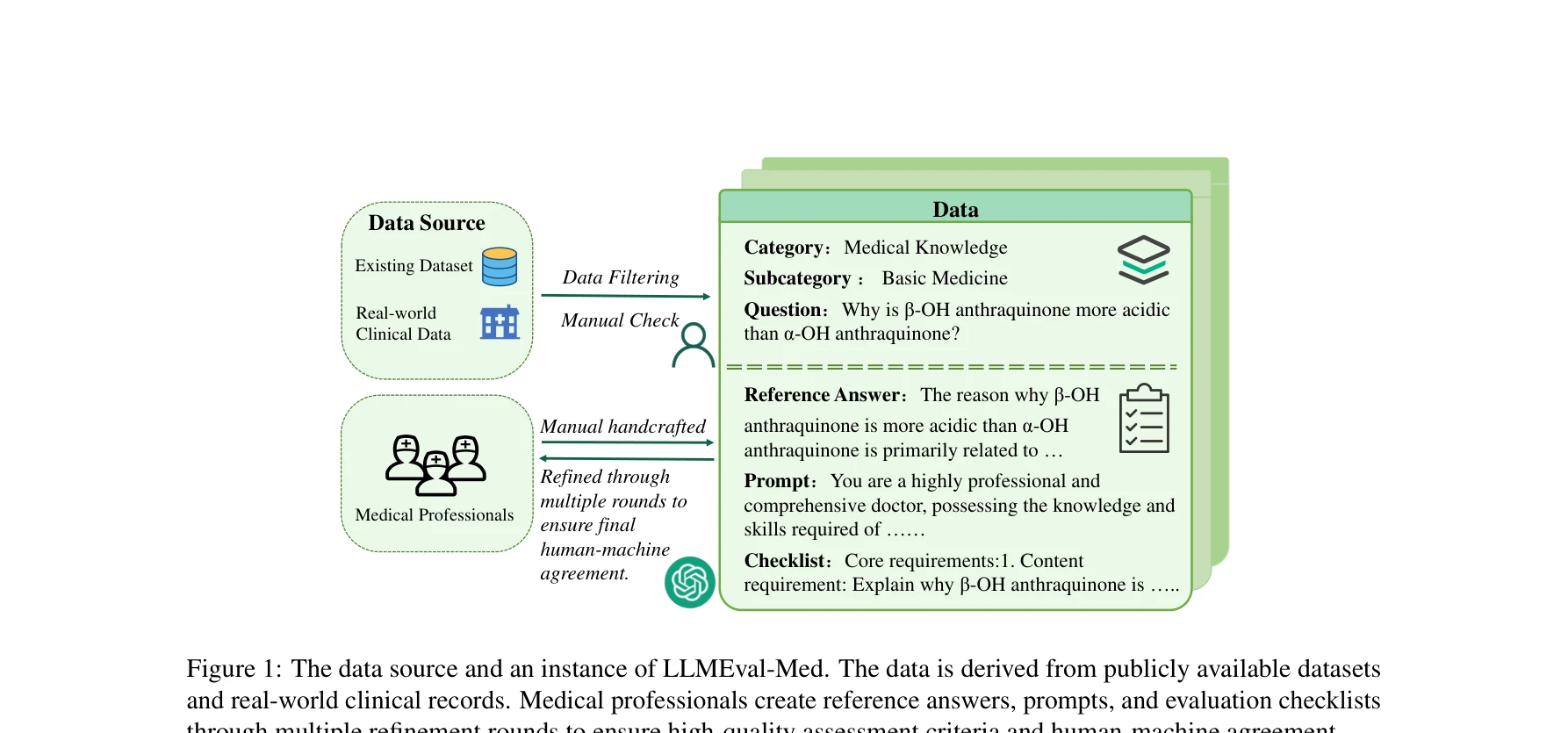
데이터 소스 및 LLMEval-Med의 인스턴스. 실제 임상 데이터와 공개 데이터셋에서 도출된 데이터를 의료 전문가들이 여러 차수의 정제를 통해 참고 답변, 프롬프트, 평가 체크리스트를 작성
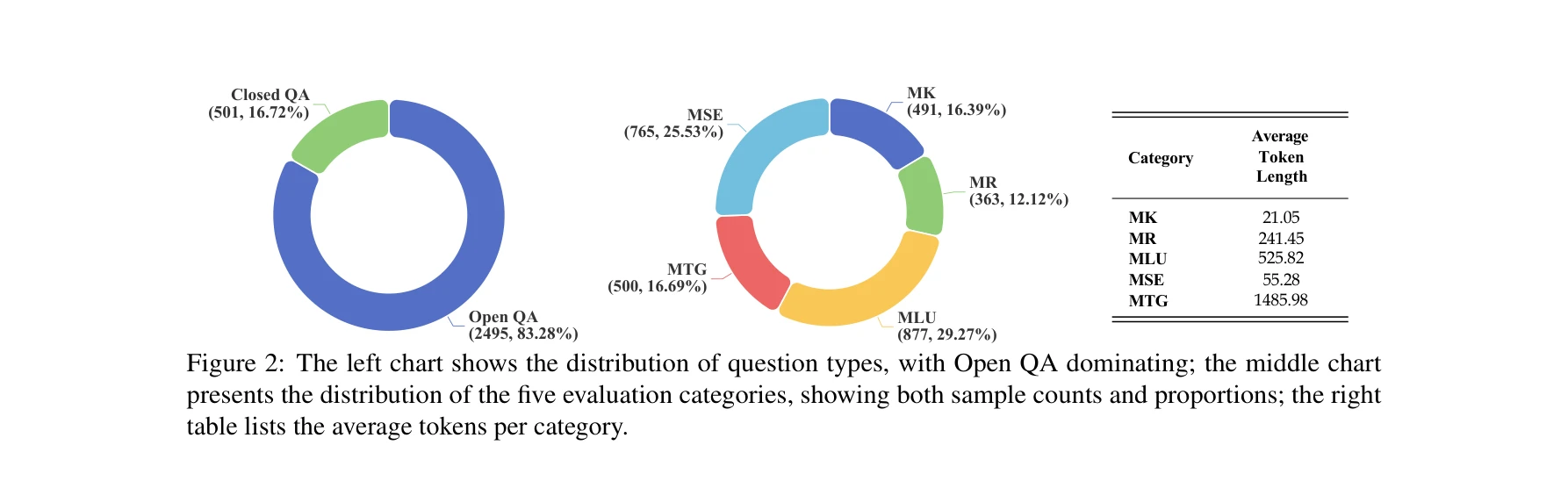
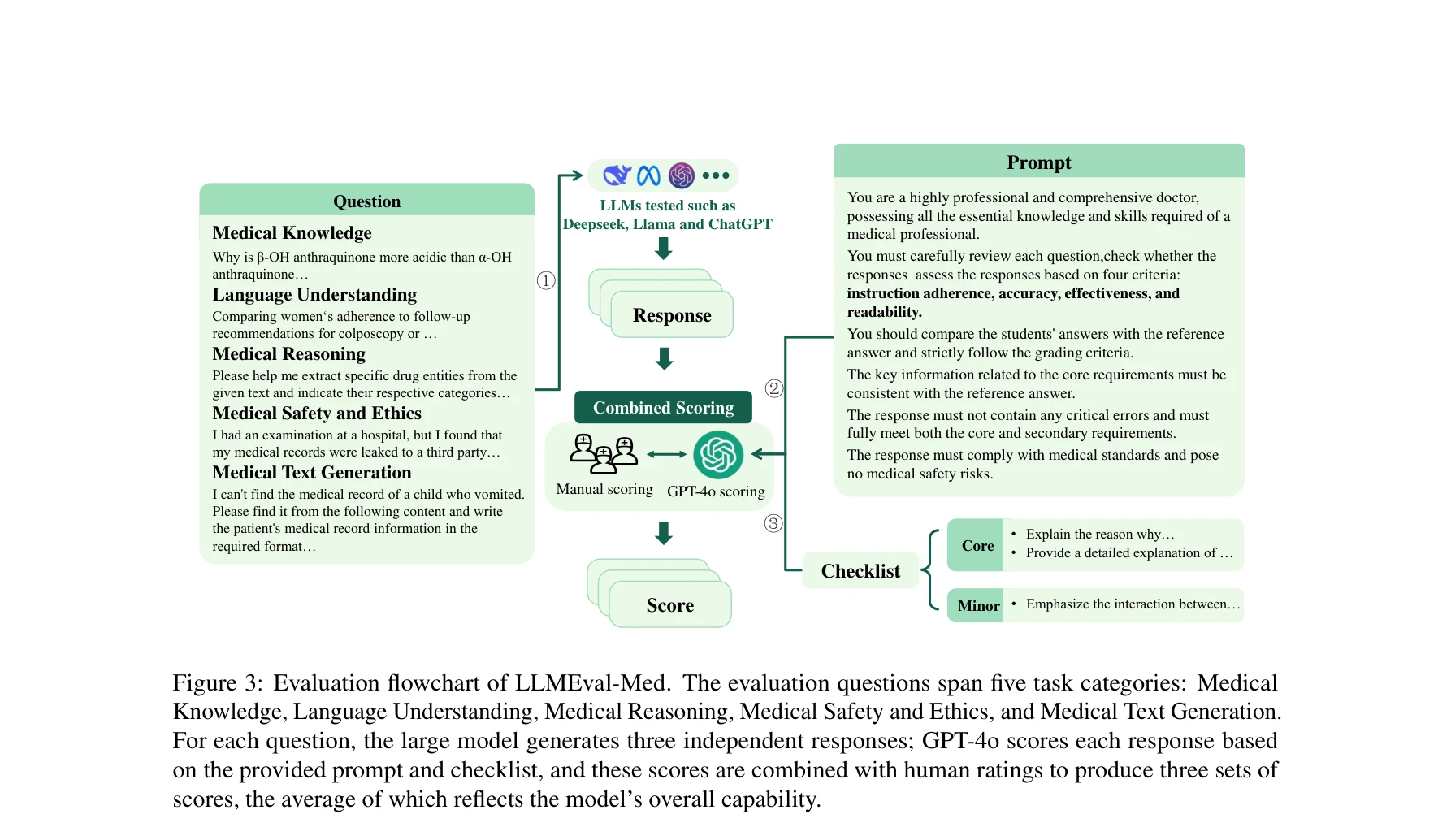
본 논문은 실제 전자의무기록(EHR)과 임상 시나리오에서 도출된 2,996개 문제로 구성된 종합적 의료 LLM 평가 벤치마크 LLMEval-Med를 제시한다. 의료 전문가 검증과 동적 평가 프레임워크를 통해 의료 AI 시스템의 안전하고 효과적인 배포를 위한 신뢰성 있는 평가 도구를 제공한다.
Evaluation
총평: LLMEval-Med는 실제 임상 데이터 기반의 포괄적 벤치마크와 의료 전문가 검증을 통한 신뢰성 있는 평가 프레임워크를 제공함으로써 의료 LLM의 임상 배포를 위한 중요한 도구를 제시한다. 특히 윤리·안전성 평가 항목의 명시적 포함과 개방형 질문 중심의 설계는 기존 벤치마크의 공백을 의미 있게 메우나, 단일 언어권 범위와 자동화 평가의 복잡한 임상 판단에 대한 검증 강화가 후속 과제이다.