How
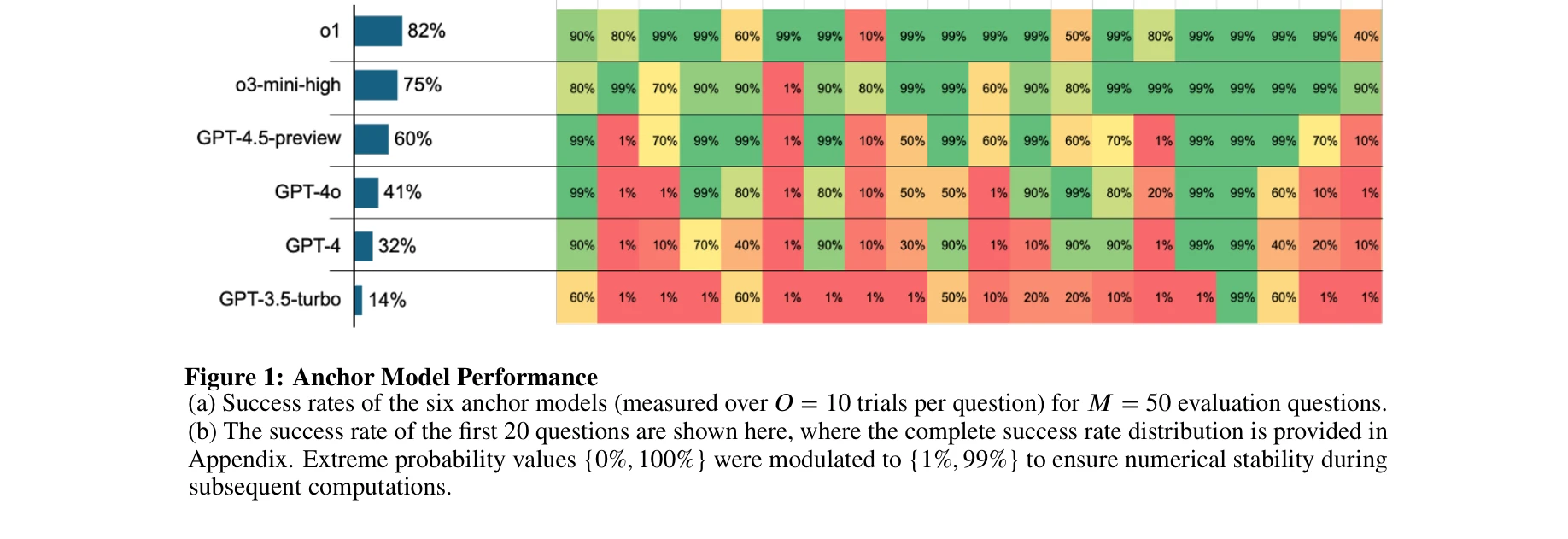
6개 앵커 모델의 50개 평가 질문에 대한 성공률 (각 질문당 O=10회 시행)
베이지안 공식화:
- 각 앵커 모델의 질문별 정답 확률 Pr(Q_j|L_i)를 10회 반복 시행으로 계산하여 능력 행렬 Π 구성
- 테스트 모델의 이진 응답 시퀀스 q = {q₁, q₂, ..., q_M}를 관찰
- 사후확률 계산:
- 사전(Prior): 최대엔트로피 원리로 uniform 분포 가정 → Pr(θ_i < θ_x ≤ θ_{i+1}) ∝ (θ_{i+1} - θ_i)
- 우도(Likelihood): 조건부 독립성 가정 하에 각 질문별 우도의 곱 (Eq. 3-4)
- 평균화(Averaging): 구간 (θ_i, θ_{i+1}]에서 균등분포 가정 시 양 경계값의 평균으로 조건부 확률 추정
- 다중 시행 확장 (Eq. 6-7): 각 질문을 O번 반복할 때 이항분포(Binomial) 우도함수 적용
질문 세트 구성:
- 기초 170개: 6개 벤치마크(superGPQA, MMLU-Pro, GPQA-Diamond, MATH, ZebraLogic, KOR-Bench, Procbench)에서 균형있게 선택
- 판별성 기준: 각 질문에 대해 최소 1개 모델 이상, 최대 절반 이하의 모델이 정답 (과도하게 쉽거나 어려운 질문 제거)
- 최종 50개로 축소하면서 다양성 유지, 구문 패러프레이징으로 배경지식 암기 방지