Essence

주요 특성별 주효과(Main Effects) 재현율 비교
대규모 심리학 실험 156개를 GPT-4, Claude 3.5 Sonnet, DeepSeek v3 등 3개의 최신 LLM으로 재현한 결과, LLM은 주효과 73-81%의 높은 재현율을 보이지만 인종, 성별 등 사회적으로 민감한 주제에서는 현저히 낮은 성과를 보였으며, 효과크기가 인간 연구보다 2-3배 크다는 체계적 편차를 드러냈다.
저자: Ziyan Cui, Ning Li, Huaikang Zhou (Tsinghua University) | 날짜: 2024 | DOI: [미제공]
주요 특성별 주효과(Main Effects) 재현율 비교
대규모 심리학 실험 156개를 GPT-4, Claude 3.5 Sonnet, DeepSeek v3 등 3개의 최신 LLM으로 재현한 결과, LLM은 주효과 73-81%의 높은 재현율을 보이지만 인종, 성별 등 사회적으로 민감한 주제에서는 현저히 낮은 성과를 보였으며, 효과크기가 인간 연구보다 2-3배 크다는 체계적 편차를 드러냈다.
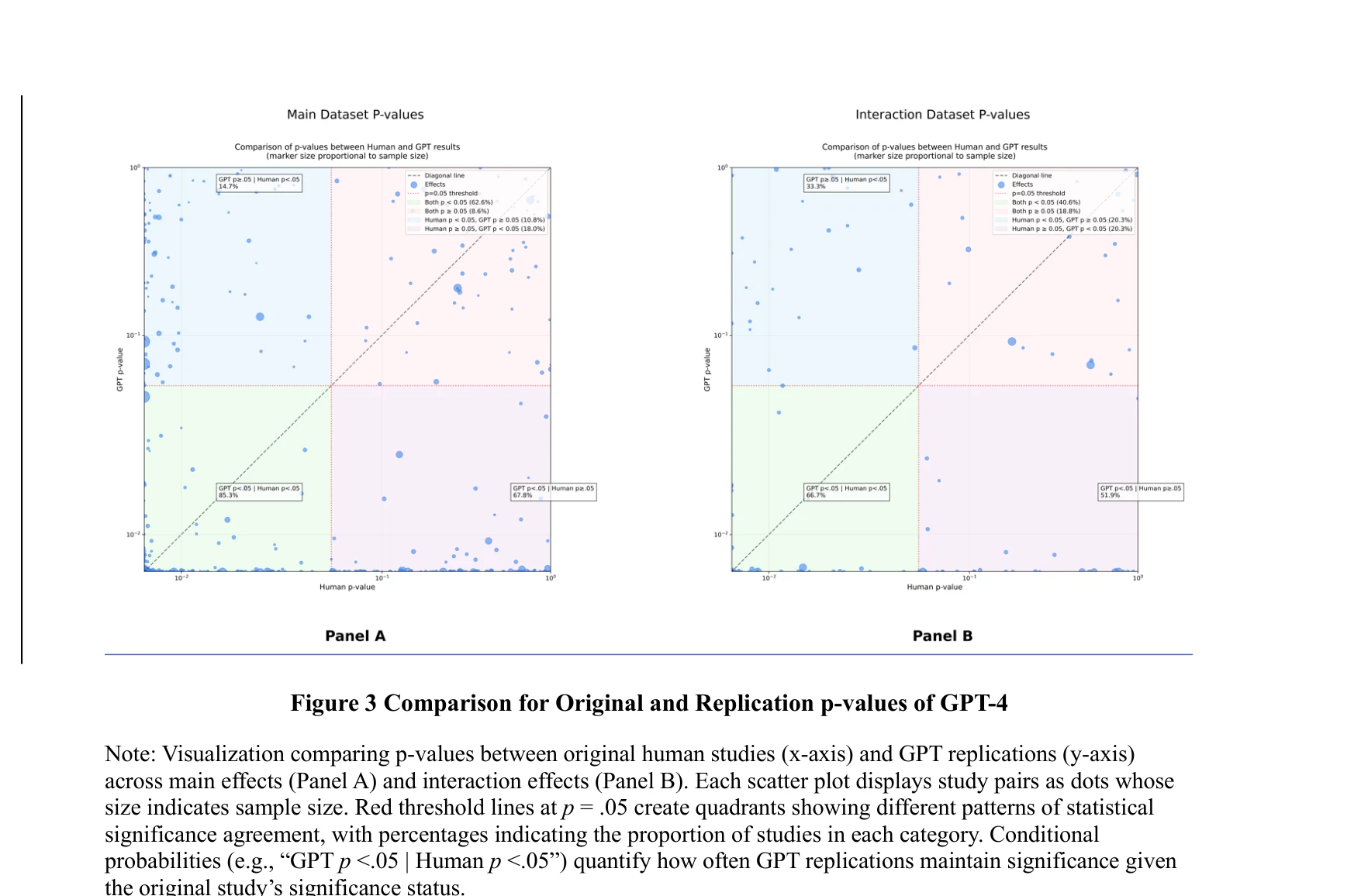
GPT-4의 원본 및 재현 p값 비교
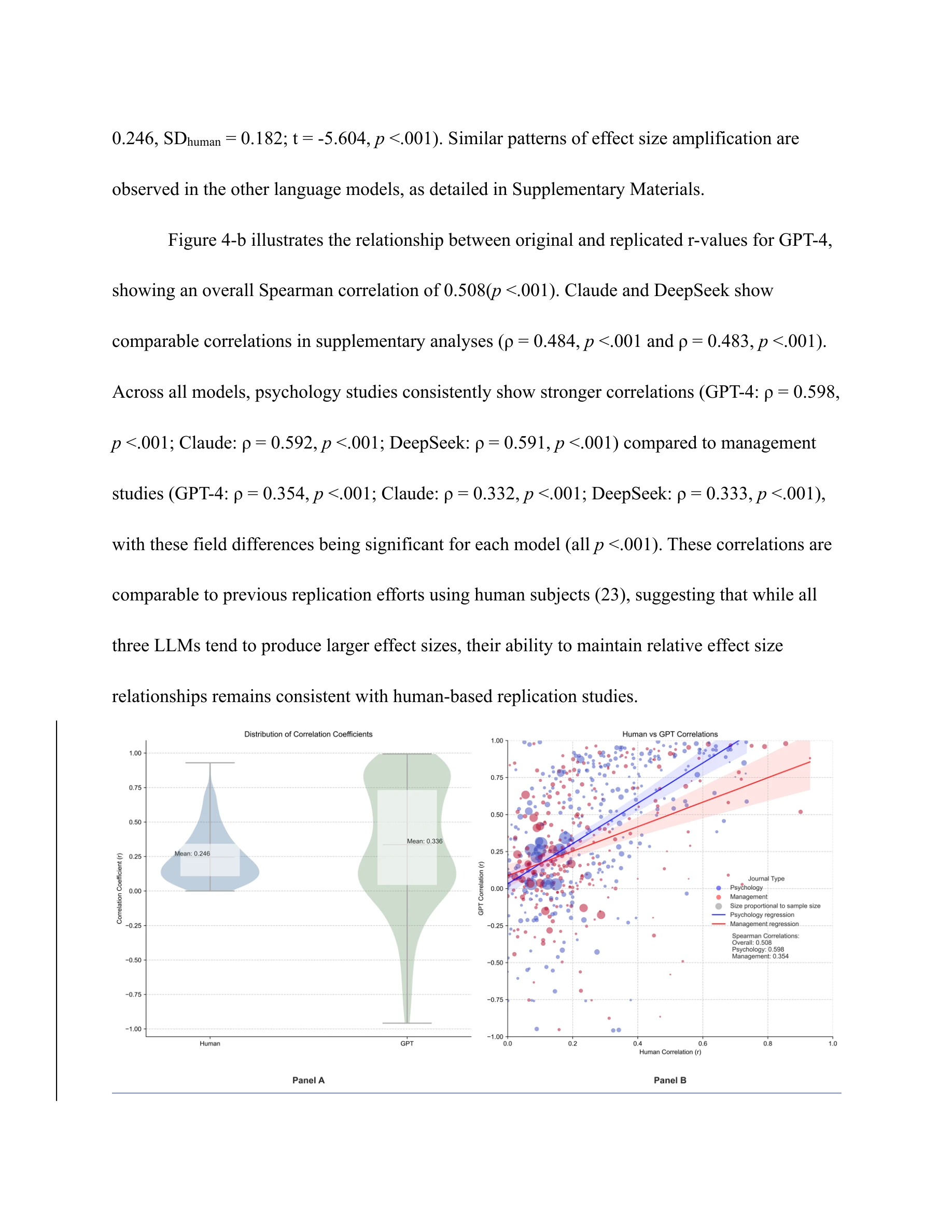
GPT-4의 주효과 r값 비교 (원본 vs 재현)

연구 설계 및 과정
총평: 이 논문은 AI 시대 사회과학 연구 방법론의 중대한 전환점을 다룬 가치 있는 대규모 실증 연구이다. LLM의 가능성과 한계를 명확하게 규명하고, 특히 사회적으로 민감한 주제에서의 체계적 편차를 입증함으로써 "LLM이 인간을 완전히 대체할 수 없다"는 중요한 결론을 제시한다. 다만 빠르게 진화하는 LLM 기술에 대응하기 위해 지속적 모니터링과 미세 조정(fine-tuning) 전략에 대한 후속 연구가 필요하다.