저자: Yue Yang, Mingkang Chen, Qihua Liu, Mengkang Hu, Qiguang Chen, Gengrui Zhang, Shuyue Hu, Guangtao Zhai, Yu Qiao, Yu Wang, Wenqi Shao, Ping Luo | 날짜: 2025 | DOI: N/A
Essence
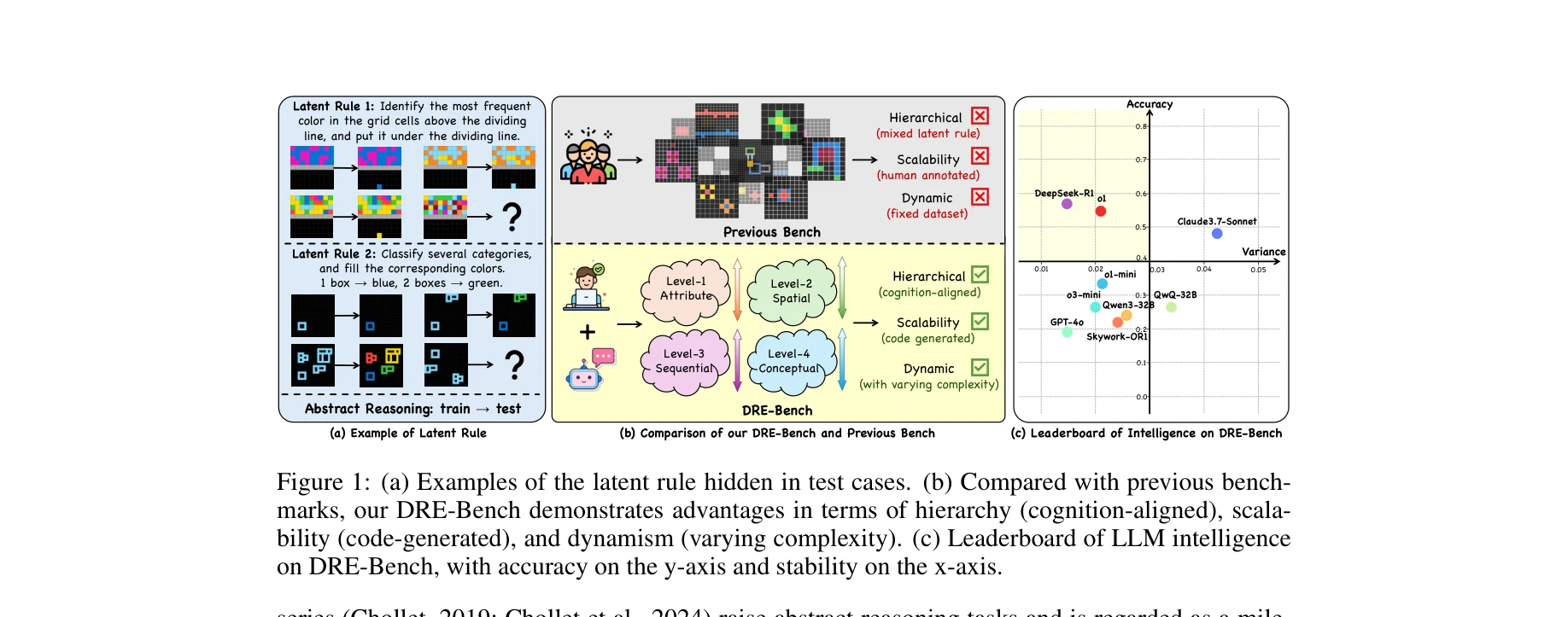
그림 1: (a) 숨겨진 잠재 규칙의 예시, (b) 기존 벤치마크와의 비교, (c) DRE-Bench의 LLM 지능 리더보드
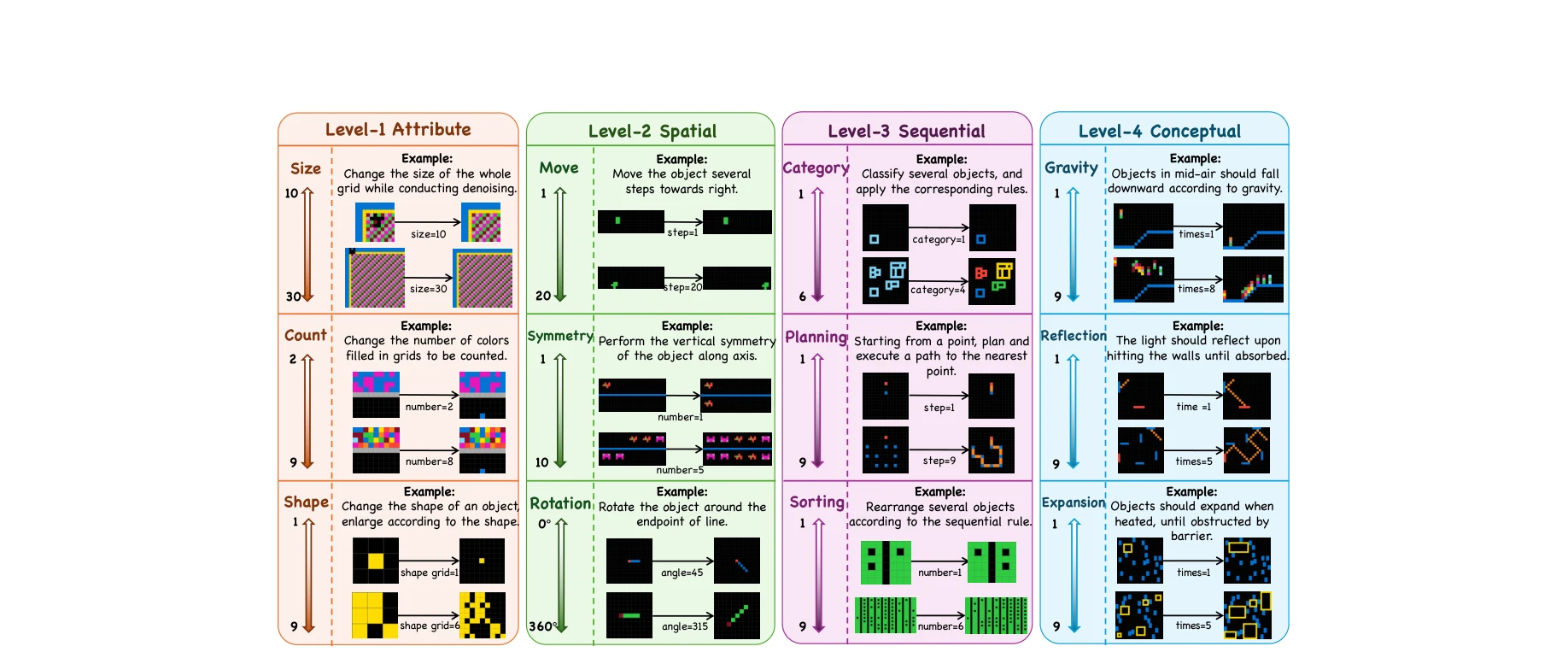
본 논문은 대규모 언어모델(LLM)의 진정한 유동 지능(fluid intelligence)을 평가하기 위해 계층적 인지 프레임워크를 바탕으로 한 동적 추론 평가 벤치마크 DRE-Bench를 제안한다. 4가지 인지 수준(속성, 공간, 순차, 개념)의 36개 추상 추론 과제와 복잡도 변화를 포함한 약 4,000개의 사례를 통해 LLM의 규칙 일반화 능력을 체계적으로 측정한다.
Evaluation
총평: 본 논문은 LLM의 진정한 유동 지능 평가를 위해 인지 심리학 기반의 계층적 구조와 동적 데이터 생성 엔진을 결합한 혁신적인 벤치마크를 제시한다. 광범위한 모델 평가를 통해 현재 LLM의 근본적인 한계를 명확히 규명했으며, 이는 향후 추론 능력 강화 연구의 객관적 기준점이 될 것으로 기대된다. 다만 평가 범위의 확장성과 실패 원인 분석의 깊이 측면에서 추가 개선의 여지가 있다.