Contributor
김동윤님
- 지난 글에서 spines, grid, legend를 정리했습니다.
- grid를 넣으려고 minor tick도 설정해 보았구요.
- 기본 데이터는 다 그렸는데, 이걸로는 아쉽습니다.
- 메시지를 추출해서 전달해봅시다.
5. 토달기 : annotate
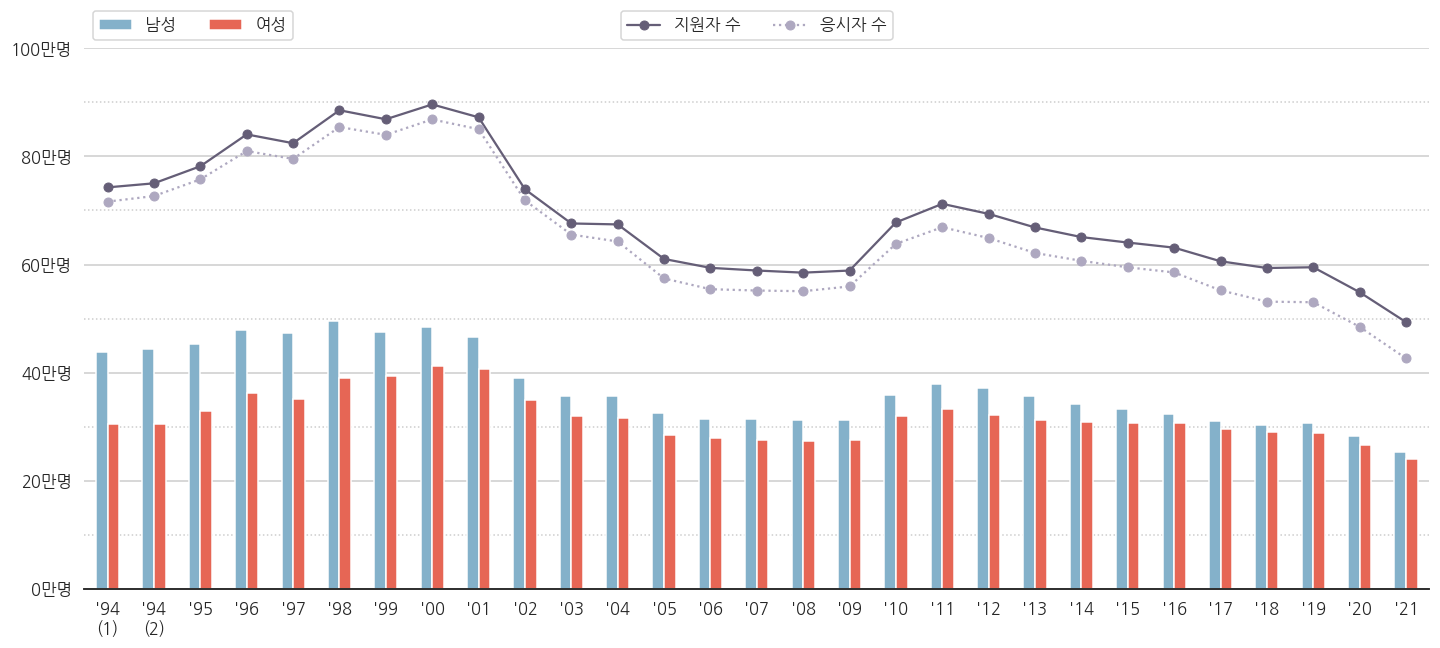
- 지원자 수는 수능을 보겠다고 원서를 제출한 사람 수고
- 응시자 수는 실제로 가서 수능시험을 치른 사람 수입니다.
- 원서를 내놓고 보신 분들이 적지 않습니다. 심지어 늘어납니다.
- 비율로 한번 구해봅시다.
5.1. 파생변수 만들기 : 응시율
- 응시율을 이렇게 정의합니다 :
응시율 = 응시자 수 / 지원자 수 * 100 - 어차피 퍼센트로 표시할 것이라 처음부터 100을 곱했습니다.
- 우리가 가지고 있는 pandas dataframe에 추가해 줍니다.
1 | # 응시율 = 응시자 수 / 지원자 수 |
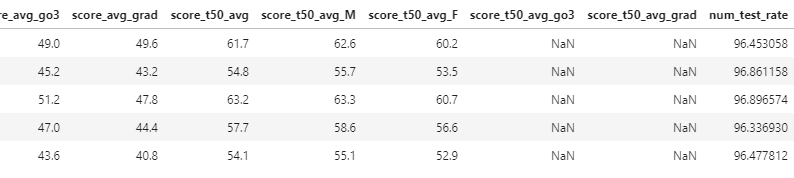
- 맨 오른쪽에 num_test_rate가 생겼습니다.
5.2. 응시율 붙이기
-
데이터에 글자를 붙일 때는
.annotate()를 사용합니다. -
문법은 이렇습니다 :
Axes.annotate(self, text, xy, *args, **kwargs) -
들어가는 인자가 제법 많습니다. 자칫 복잡하게 느껴질 수 있으므로 몇 개만 봅시다.
-
다른 인자는 다음 기회에 보고, 이만큼만 사용해서 그립니다.
- self : 클래스 배울 때 나오죠? 뭐 넣으라는 뜻이 아니라 instance method라는 뜻입니다.
- text : 표시될 글자입니다.
- xy : 글자가 가리킬 지점의 좌표입니다.
A ← B를 넣는다면, A에 해당하는 지점입니다. - xytext : (옵션) 글자가 위치할 지점의 좌표입니다.
A ← B를 넣는다면, B에 해당하는 지점입니다. - arrowprops : (옵션) 화살표를 어떻게 그릴지 정합니다.
A ← B를 넣는다면, ←에 해당하는 인자입니다.
-
.plot()같은 명령은 설정 한번에 plot 전체에 적용됩니다. -
하지만
.annotate()는 하나하나 그려줘야 합니다. -
손이 많이 갑니다. for loop을 사용합시다.
1 | # 응시율 붙이기 1: 데이터 순서 사용하기 |
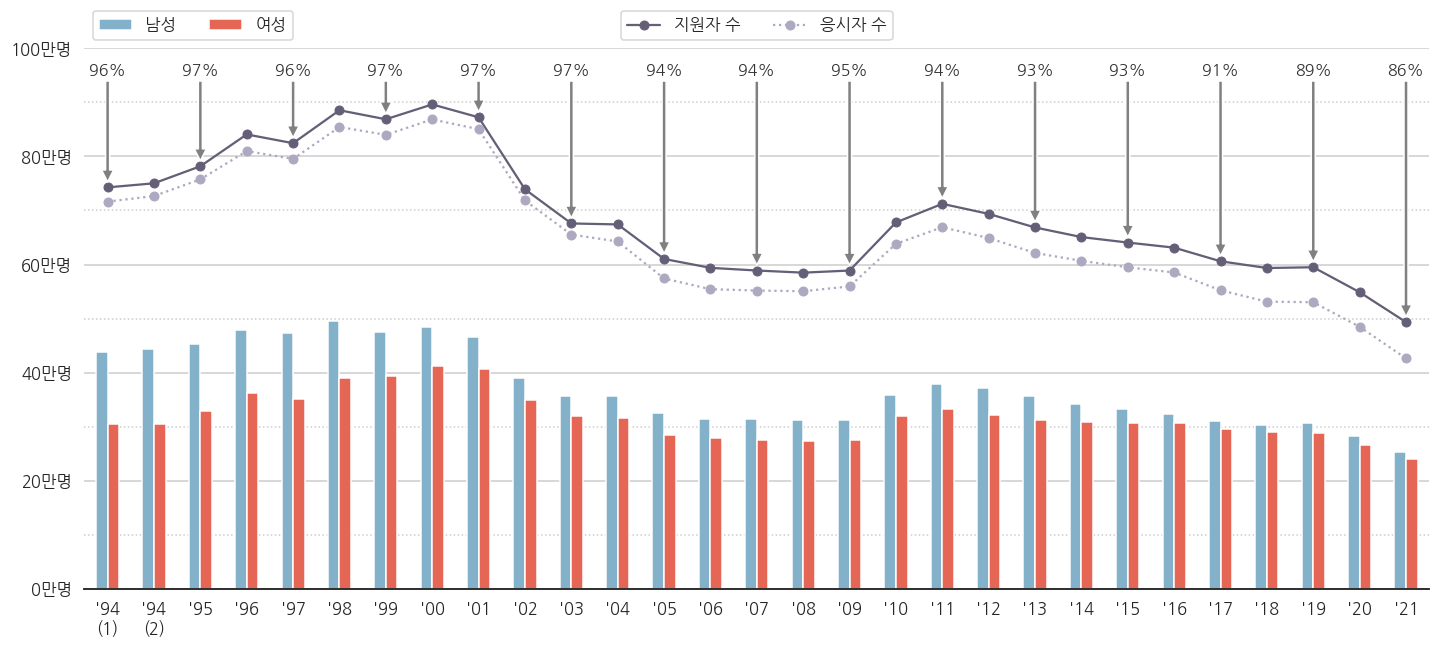
-
응시율이 숫자로 붙었습니다.
-
방금 데이터를 하나 건너 하나 붙일 때,
for i in range(0, df_sn.shape[0], 2):라고 했습니다. -
데이터의 순서를 사용하는 방법입니다. index가 점프하거나 중복될 때 사용하기 좋습니다.
-
index 기준으로 하나씩 건너뛰고 싶다면, 이렇게 고치면 됩니다.
1 | for i in df_sn.index.values[::2]:: # index 기준 하나 건너 하나에 적용 |
- 결과물은 정확히 동일합니다.
5. annotate에 legend 붙이기 : text
-
응시율을 넣었으니 이게 응시율인 줄 알게 해야 합니다.
-
비어있는 오른쪽 위 공간에 legend를 넣읍시다.
-
.text()를 사용하면 간단하게 넣을 수 있습니다. -
text에 다양한 형태의 윤곽선을 두를 수 있다는 사실을 잘 모르는 분들이 많습니다.
-
ax.text(bbox={"boxstyle":스타일})에서 스타일에 해당하는 부분을 바꾸는 것으로 되는데 말입니다. -
총 9가지 스타일을 제공합니다.
1 | from itertools import product |
-
fontdict를 설정해서 전체적인 font를 제어합니다.
-
text가 삽입되는 지점을 일일이 넣어주기보다
product를 이용해서 간단하게 만들어 줍니다. -
round를 선택해서 text로 legend를 만들어줍니다. -
간만에 전체 코드를 한번 적어봅니다.
1 | fig, ax = plt.subplots(figsize=(20, 9), sharey=True) |
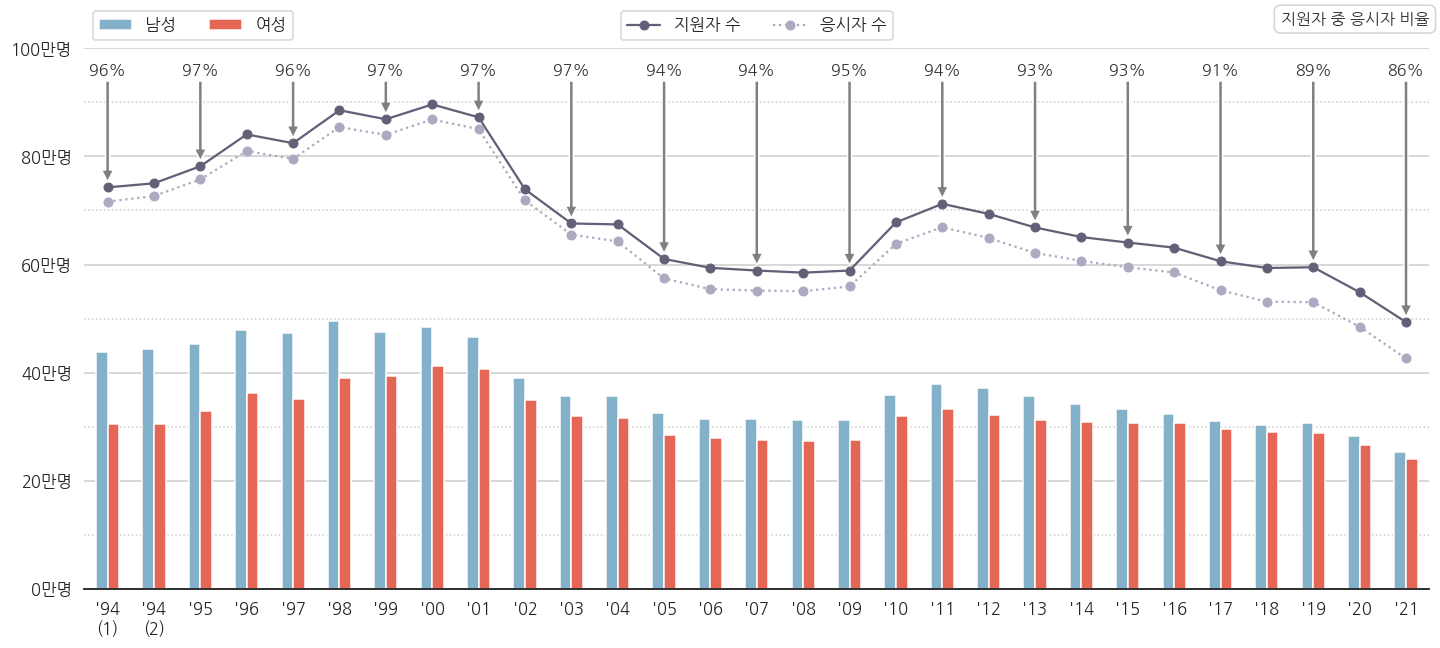
-
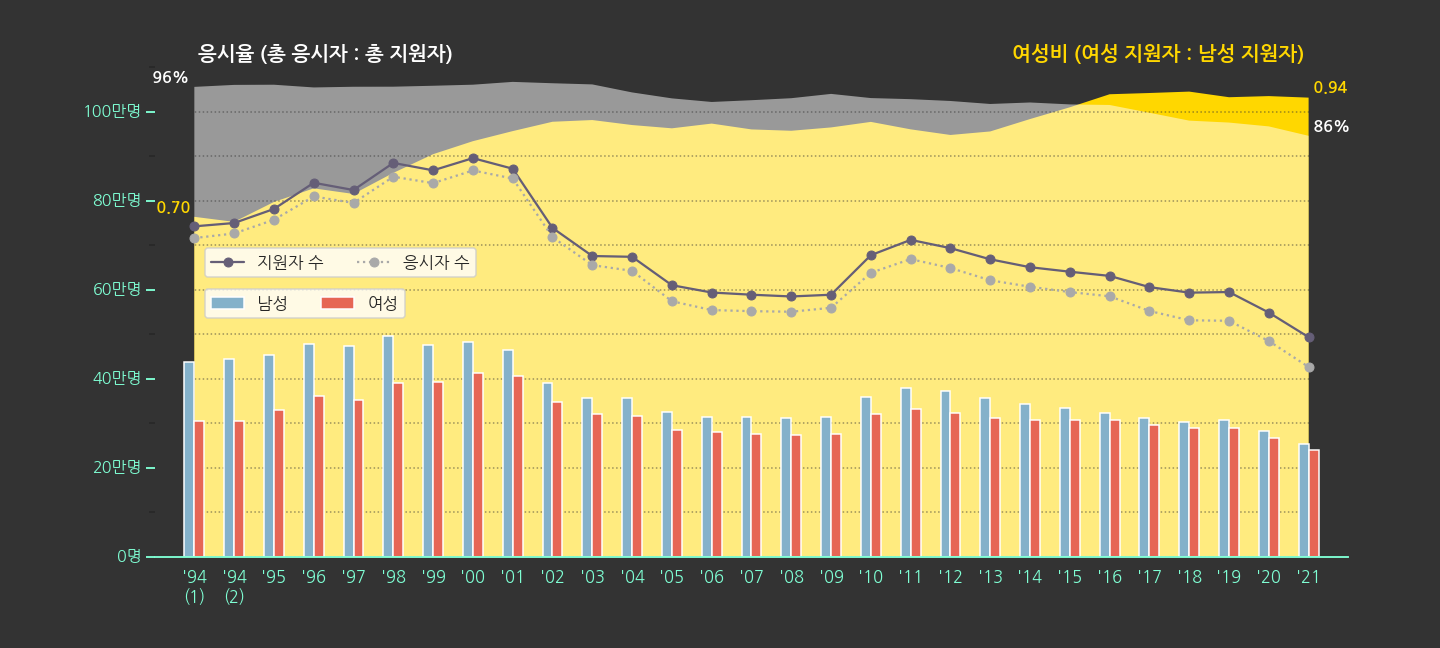
10학번 무렵부터 응시율이 떨어지는 추세가 보입니다.
-
2021학년도 응시율이 수능 역사상 최저를 기록했습니다.
-
코로나 영향으로 인해 결시율 최고라는 기사가 있지만, 최근 몇년간 추세를 보면 꼭 코로나 탓은 아닌 것 같습니다.
-
수시 등의 영향으로 수능을 볼 필요가 없어지는 수험생이 안전장치로 지원은 해 놓는 탓에 응시율이 떨어지는 것이 아닌가 싶네요.
-
결시자 중 수시 전형 비율데이터가 있으면 더 명확할 것 같습니다.
6. 성비 구하기
6.1. 여성 지원자 1인당 남성 지원자 수
- 응시율 저하 외에도 남녀 성비의 변화가 눈에 띕니다.
- 일반적으로 성비를
여성 1인당 남성의 수로 정의합니다.
1 | # 성비 = 남성 수 / 여성 수 |
- 응시율과 같은 요령으로 성비를 넣어봅시다.
- 응시율을 넣던 for loop에 성비를 같이 넣습니다.
1 | for i in range(0, df_sn.shape[0], 2): |
- legend도 추가합니다.
1 | # legend (4) 성비 (남성 : 여성) |
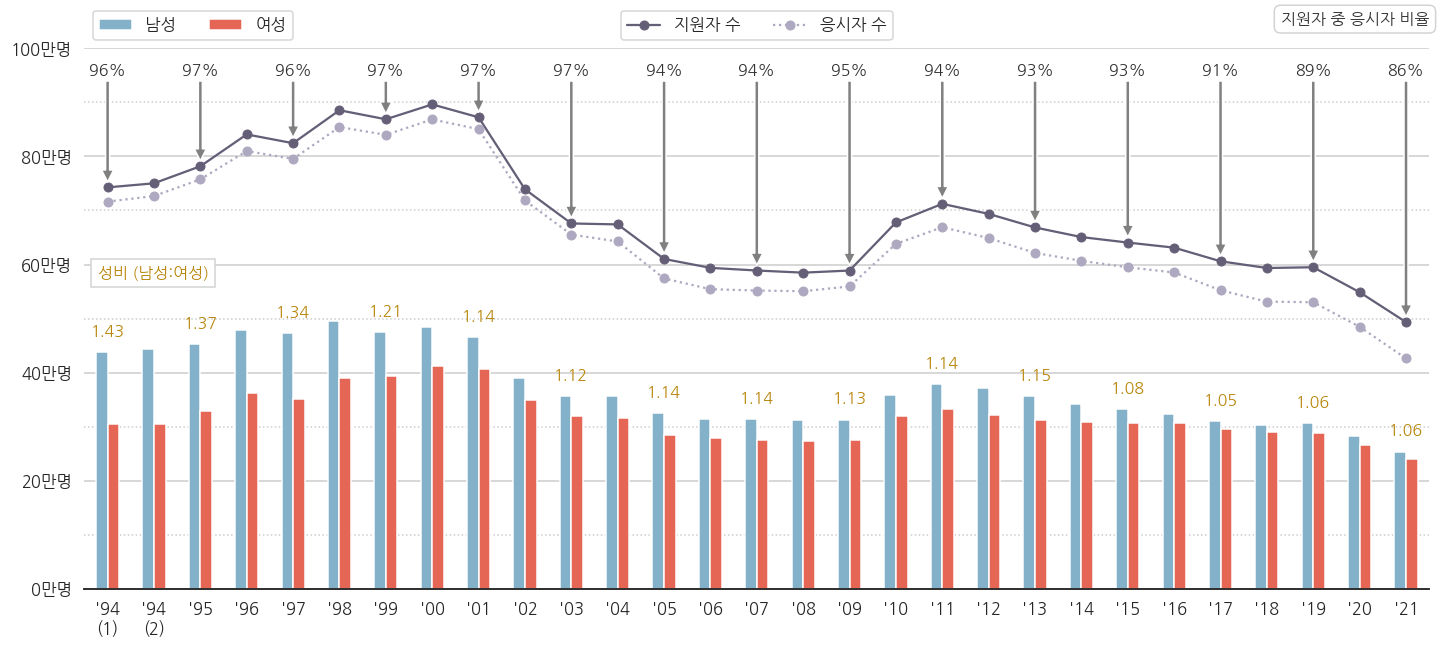
6.2. 남성 지원자 1인당 여성 지원자 수
-
1.4를 넘어가던 성비가 차츰 줄어서 1.06이 됩니다.
-
여성의 대학 진학 시도가 더 많아진다고 볼 수 있을 것 같습니다.
-
여성 재수생 비율이 늘어나는 것인지는 현재로서는 알 수 없지만, 그렇다고 해도 재수를 허용하는 비율이 증가한다고도 볼 수 있을 테니까요.
-
여성 1인당 기준을 남성 1인당으로 바꿔봅니다.
1 | df_sn["num_F_rate"] = df_sn["num_F"]/df_sn["num_M"] |
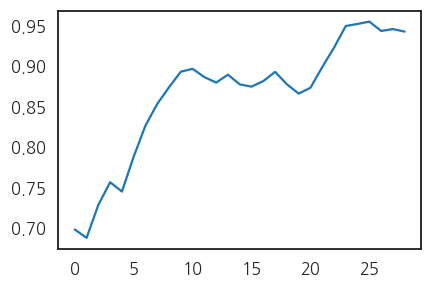
- 10년차와 20년차의 두 단계 점프가 선명합니다.
- 이제까지 그린 그림의 배경으로 깔아보겠습니다.
- 아래 코드를 추가합니다.
1 | # 여성비 |
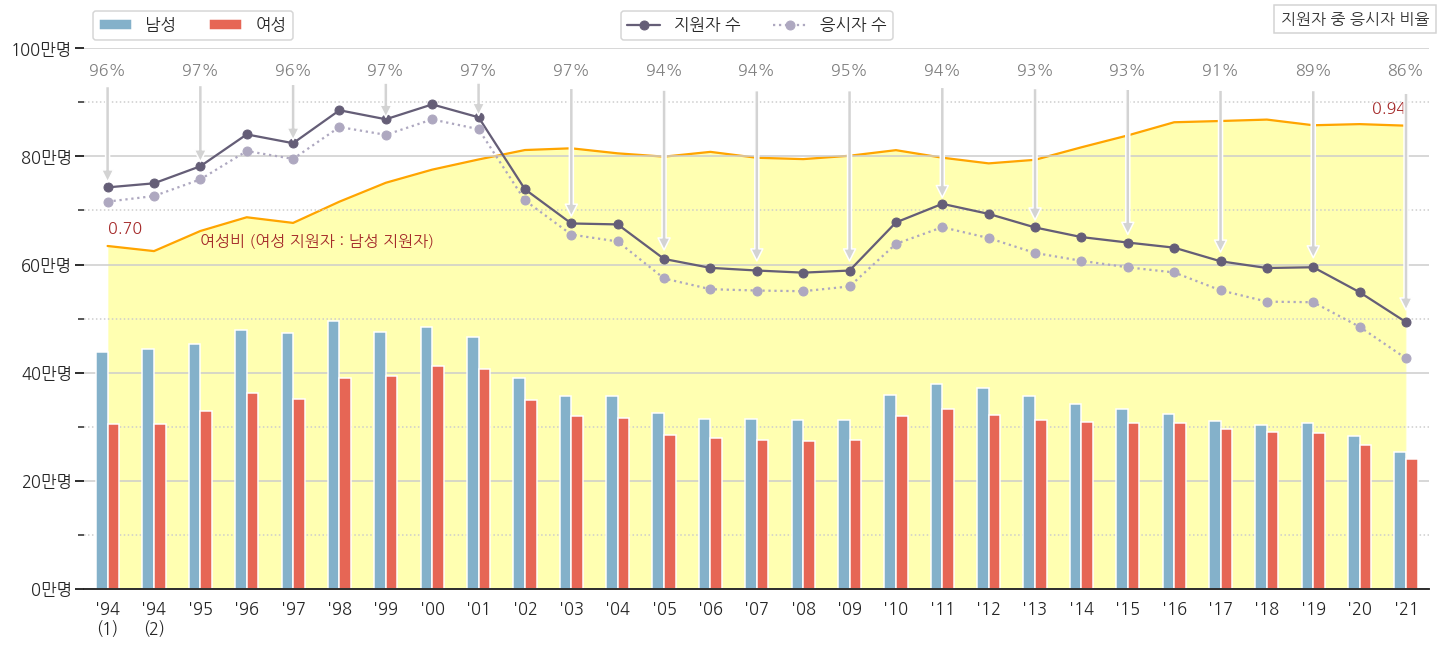
6.3. 강조점 변경
-
처음에는 단순히 수능 년도별 인원을 그려봤는데, 응시율과 여성비를 도출했습니다.
-
이번 plot의 주인공을 이것으로 해 봅시다.
-
전체 plot에서 이 둘을 부각시키고, 나머지를 부가 요소로 돌립니다.
-
다음과 같은 과정을 거쳐 강조점을 변경하려고 합니다.
- 응시율, 여성비만 밝게, 나머지 어둡게
- 응시율과 여성비 legend를 강조, 나머지는 숨기기
- 전체 그림에서 응시율, 여성비 외 면적 비중 축소
-
그 결과, 다음과 같은 그림을 얻었습니다.
-
코드는 다음과 같습니다.
1 | fig, ax = plt.subplots(figsize=(20, 9), sharey=True) |
