- 본 글은 번역글입니다.
- 원 글은 2020년 5월 18일 medium에 발행되었습니다.
원본 주소 : https://towardsdatascience.com/10-tensorflow-tricks-every-ml-practitioner-must-know-96b860e53c1
번역 철학 : 매끄럽게 읽으실 수 있는 적절한 의역을 지향합니다.
전문 용어 : 가급적 김태완님과 박해선님의 우리말 용어를 사용하고자 하며, 원어를 병기합니다.
한 줄 요약
- 텐서플로2에는 데이터 처리와 모델 커스터마이제이션을 위한 편의기능이 많이 있습니다.

머신러닝 실무자라면 알아야 하는 텐서플로 트릭 10가지
- 왜 텐서플로는 머신러닝 완결 패키지인가
텐서플로 2.x은 모델 구축과 텐서플로 사용 전반을 훨씬 간결하게 해 줍니다. TF2에서 새로워진 점은 어떤 것들이 있을까요?
- Keras와 즉시 실행(eager execution)이 있어 모델 구축이 쉽습니다.
- 어떤 플랫폼에서도 동작하도록 모델을 탄탄하게 배포할 수 있습니다.
- 연구에 강력한 실험을 적용할 수 있습니다.
- 사라진 API를 정리하고 중복을 줄여서 API가 단촐해졌습니다.
이번 글에서는 텐서플로 작업을 부드럽게 만들어주고, 코딩을 짧게 해주어 효율성을 높여주는 TF 2.0의 특징 10가지를 텐서플로 API에 속한 함수/클래스들과 함께 살펴보겠습니다.
1(a) Input Pipeline 구축에 좋은 tf.data API
tf. data API는 데이터 파이프라인 구축 및 관련 기능을 제공합니다. 파이프라인을 구축하고, 전처리 함수들을 매핑(mapping)해주고, 데이터셋을 섞거나(shuffle) 배치(batch)로 잘라두는 외에도 많은 기능을 제공합니다.
텐서 입력 파이프라인 구축
1 | >>> dataset = tf.data.Dataset.from_tensor_slices([8, 3, 0, 8, 2, 1]) |
Batch와 Shuffle
1 | # Shuffle |
두 데이터셋 묶기(zipping)
1 | >>> dataset0 = tf.data.Dataset.from_tensor_slices([8, 3, 0, 8, 2, 1]) |
외부 함수 mapping
1 | def into_2(num): |
1 | >>> dataset = tf.data.Dataset.from_tensor_slices([8, 3, 0, 8, 2, 1]).map(into_2) |
1(b). ImageDataGenerator
제 의견입니다만 tensorflow.keras API의 가장 좋은 특징 중 하나라고 생각합니다. ImageDataGenerator는 데이터 증폭(data augmentation)과 동시에 batching과 전처리를 수행하는 데이터셋 슬라이스(dataset slice) 생성을 실시간으로 할 수 있습니다.
ImageDataGenerator의 데이터 증폭은 기존 데이터에 더 많은 데이터를 추가하는 것이라는 오해가 있습니다. 데이터 증폭의 정의는 이 말이 맞긴 하지만, ImageDataGenerator에서는 훈련 과정의 단계에 따라 역동적으로 데이터셋에 있는 이미지들이 변환됩니다. 따라서 머신러닝 모델은 본 적이 없는 노이즈와 함께 학습됩니다.
1 | train_datagen = ImageDataGenerator( |
여기에서는 정규화(normalizing)를 위해 리스케일링(rescaling)도 함께 수행되고 있습니다. 다른 파라미터는 데이터 증폭 관련된 것들입니다.
1 | train_generator = train_datagen.flow_from_directory( |
실시간 데이터 수급을 위해 디렉토리를 지정합니다. 데이터프레임에도 똑같이 적용될 수 있습니다.
1 | train_generator = flow_from_dataframe( |
$$x _ col$$에 이미지의 전체 경로를 정의하고, $$y _ col$$에 분류할 레이블 열을 지정합니다.
머신러닝 모델에는 생성기가 직접 연결될 수 있습니다. 다만 이 때, $$steps _ per _ epoch$$ 파라미터가 $$number _ of _ samples$$//$$batch _ size$$로 지정되어야 합니다.
2. tf.image를 활용한 데이터 증폭
데이터 증폭은 꼭 필요합니다. 데이터가 부족할 때 데이터를 바꾸며 이를 별도의 데이터포인트로 다루면 적은 수의 데이터로도 효과적으로 훈련시킬 수 있습니다.
tf.image API 는 이미지를 변환시키는 도구를 여럿 가지고 있습니다. 이렇게 변환된 이미지는 앞서 언급한 tf.data API를 통한 데이터 증폭에 사용될 수 있습니다.
1 | flipped = tf.image.flip_left_right(image) |
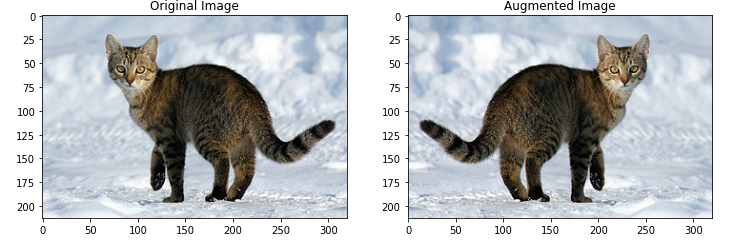
1 | saturated = tf.image.adjust_saturation(image, 5) |

1 | rotated = tf.image.rot90(image) |
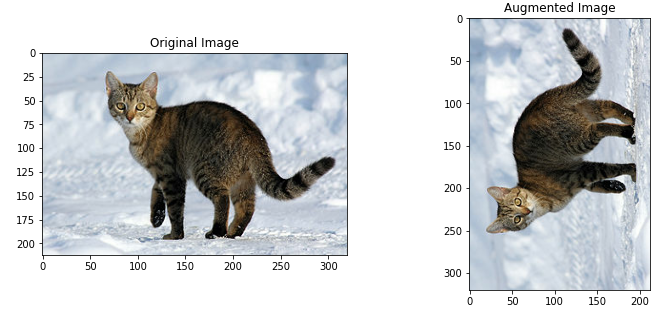
1 | cropped = tf.image.central_crop(image, central_fraction=0.5) |

3. 텐서플로 데이터셋
1 | pip install tensorflow-datasets |
텐서플로가 모아둔, 매우 잘 알려진 여러 분야의 데이터셋을 한 방에 가지고 올 수 있는 매우 유용한 라이브러리입니다.
1 | import tensorflow_datasets as tfds |
tensorflow-dataset에서 제공하는 데이터셋의 상세 목록은 공식 문서의 데이터셋 페이지에서 볼 수 있습니다.
오디오, 이미지, 이미지 분류, 객체 인식, 정형, 요약, 문서, 번역, 동영상 등이 제공됩니다.
4. 사전학습 모델을 활용한 전이학습
전이학습은 머신러닝의 샛별이며, 그만큼 중요합니다. 누군가가 충분한(예. 일반인이 접하기 어려운 다수의 고가 GPU) 자원을 이용해 학습해둔 벤치마크 모델을 다시 학습하는 건 가능 하지도 않고 도움도 되지 않습니다. 전이학습은 이런 상황에 좋습니다. 사전학습 모델을 주어진 사례에 재사용하거나 다른 사례에 확장해서 적용할 수 있습니다.
텐서플로는 당면 과제에 적용하기 좋도록 벤치마크 사전학습 모델을 제공합니다.
1 | base_model = tf.keras.applications.MobileNetV2( |
여기 있는 $$base _ model$$은 추가 레이어나 다른 모델로 쉽게 확장이 가능합니다. 예를 들면,
1 | model = tf.keras.Sequential([ |
다른 사전학습 모델 목록이나 tf.keras.applications의 모듈에 대해서는 문서 페이지를 참고하세요.
5. 에스티메이터(Estimators)
에스티메이터는 전체 모델에 대한 텐서플로의 하이레벨 표현이며, 쉬운 스케일링과 비동기 훈련을 위해 설계되었다 – 텐서플로 문서
사전제작된 에스티메이터는 매우 높은 수준으로 추상화된 모델을 제공하여, 여러분들은 복잡한 하위 레벨에 대해선 마음을 놓고 모델 훈련에만 집중할 수 있습니다. 예를 들면,
1 | linear_est = tf.estimator.LinearClassifier( |
위 예제는 tf.estimator를 이용해 에스티메이터를 구축하고 훈련하기가 얼마나 쉬운지를 보여줍니다.
에스티메이터는 맞춤형으로 만들 수 있습니다.
텐서플로에는 LinearRegressor, BoostedTreesClassifier 등과 같은 사전제작된 에스티메이터가 많이 있습니다. 전체 에스티메이터에 대한 상세한 설명은 텐서플로 문서에서 보실 수 있습니다.
6. 맞춤형 레이어(Custom Layers)
신경망에는 여러 종류의 심층 네트워크 모델이 있다고 알려져 있습니다. 텐서플로에는 Dense, LSTM처럼 미리 정의된 레이어들이 있습니다. 하지만 더 복잡한 아키텍쳐에서는 레이어의 논리적 동작이 기본 레이어보다 훨씬 복잡합니다. 이럴 때를 대비해서, 텐서플로는 맞춤형 레이어 구축을 허용합니다. tf.keras.layers.Layer 클래스를 상속받아 만들 수 있습니다.
1 | class CustomDense(tf.keras.layers.Layer): |
문서에 기술된 바와 같이, 사용자 본인의 레이어를 구현하는 가장 좋은 방법은 tf.keras.Layer를 확장해서 구현하는 것입니다.
- _ _$$init$$_ _: 입력과 무관한 초기화를 여기에 넣으세요
- $$build$$ : 입력 텐서의 모양(shape)을 받아서 할 수 있는 나머지 초기화를 여기에서 합니다.
- $$call$$ : 순방향 연산(forward computation)을 합니다.
커널 초기화를 _ _$$init$$_ _ 자체에서 구현할 수 있지만, build에서 구현하는 것이 더 좋습니다. 그렇지 않으면 매번 레이어 인스턴스를 생성할 때마다 input_shape을 명시해야 하기 때문입니다.
7. 맞춤형 훈련(Custom Training)
tf.keras의 Sequential 과 Model API를 사용하면 모델을 쉽게 훈련할 수 있습니다. 그러나 복잡한 모델을 훈련시키는 시간 대부분은 맞춤형 손실함수(custom loss functions)가 사용됩니다. 게다가, 모델 훈련은 기본값이랑 다른 경우도 있습니다 (예를 들어 다른 모델 요소에 그레이디언트를 다르게 적용하는 경우가 있습니다)
텐서플로의 자동미분을 이용하면 그레이디언트를 효과적으로 계산할 수 있는데, 이는 맞춤형 훈련 과정을 정의할 때 사용할 수 있습니다.
1 | def train(model, inputs, outputs, learning_rate): |
이렇게 하면 사례별로 걸맞게 설정된 훈련을 여러 에포크(epoch) 반복할 수 있습니다.
8. 체크포인트(Checkpoints)
텐서플로 모델은 두 가지 방법으로 저장할 수 있습니다.
1. SavedModel : 모델의 전체 상태를 파라미터와 함께 저장합니다. 소스코드와 무관합니다.
2. Chekpoints
체크포인트는 모델에 사용된 파라미터의 정확한 값들을 저장합니다. Sequential API나 Model API로 작성된 모델은 SavedModel 형식으로만 저장할 수 있습니다.
그러나, 맞춤형 모델이라면 체크포인트가 필요합니다.
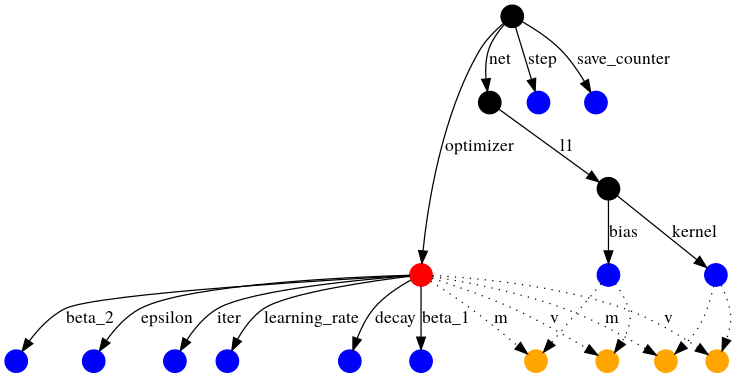
체크포인트는 모델에서 정의된 계산이 어떻게 진행되는지에 대한 정보를 가지고 있지 않기 때문에, 파라미터만 가져오는 코스와 함께 사용될 때만 유용합니다.
- 체크포인트 저장
1 | checkpoint_path = “save_path” |
- 체크포인트 불러오기
텐서플로는 방향 그래프(directed graph)를 객체가 로딩되는 지점부터 가로지르며 변수와 체크포인트 값들을 이름이 붙은 엣지(named edge)와 매칭합니다.
9. 케라스 튜너(Keras Tuner)
텐서플로의 신무기입니다.
1 | pip install keras-tuner |
하이퍼파라미터 튜닝, 또는 하이퍼튜닝은 머신러닝 모델 성능을 최적화하는 단계입니다. 하이퍼파라미터는 특성 공학(feature engineering)과 전처리 이후 모델의 성능을 결정짓는 인자입니다.
1 | # model_builder is a function that builds a model and returns it |
HyperBand와 더불어 BayesianOptimization과 RandomSearch를 튜닝에 사용할 수 있습니다.
1 | tuner.search( |
이어서 최적화된 하이퍼파라미터로 모델을 훈련할 수 있습니다.
1 | model = tuner.hypermodel.build(best_hps) |
11. 분산훈련(Distributed Training)
여러분에게 여러 대의 GPU가 있고 여기에 대한 분산 훈련을 최적화하고 싶으시다면 텐서플로의 다양한 분산 훈련 전략을 통해서 GPU 사용과 GPU 훈련 시간을 최적화 할 수 있습니다.
tf.distribute.MirroredStrategy는 가장 일반적인 전략입니다. 어떻게 작동하는지 알아볼까요? 문서에 이렇게 나와있습니다.
- 모든 변수와 모델의 복사본을 만듭니다.
- 입력이 복사본들에 균등하게 나누어집니다.
- 각각의 복사본들이 받은 입력에 대해 손실(loss)과 그레이디언트를 계산합니다.
- 모든 복사본 간에 그레이디언트가 동기화되고 더해집니다.
- 동기화가 끝나면, 각 복사본들의 변수 복사본에 같은 방식으로 업데이트를 합니다.
1 | strategy = tf.distribute.MirroredStrategy() |
다른 맞춤형 훈련에 대해서는 문서를 참고하세요.
결론
텐서플로는 머신러닝 파이프라인의 거의 모든 구성요소를 구축하기에 충분합니다.아래 튜토리얼에서 얻어갈 것은, 텐서플로에서 제공하는 다양한 API에 대한 소개 및 어떻게 사용하는지에 대한 퀵 가이드입니다.
여기에 GitHub 코드 저장소 링크가 있습니다. 포크해보세요.
참고문헌
본 가이드에 사용된 코드들은 공식 텐서플로 문서를 참조했습니다.
