-
그래프에서 중요한 값들이 특정 범위에 몰려있으면 확대를 해야 합니다.
-
matplotlib의 object oriented API는
.set_xlim()과.set_ylim()을 제공해 줍니다. -
jupyter notebook에서
%matplotlib qt로 선언했다면 GUI로 자유롭게 지정할 수도 있습니다.
-
그러나 잘 보이지도 않는 영역을 찾기 위해 반복적으로 영역을 설정하는 일은 지루합니다.
-
데이터 숫자라도 많으면 다시 그릴때마다 기다려야 하는 과정이 결코 즐겁지 않습니다.
-
데이터의 분포를 이용해 관심영역(Region of Interest)를 자동으로 확대하는 함수를 만들겠습니다.
1. sample data
- 예제 데이터는
xs=[x1, x2, x3, x4, x5],ys=[y1, y2, y3, y4, y5]로 미리 정의되었습니다.- 여기에서 다운로드 받으실 수 있습니다.
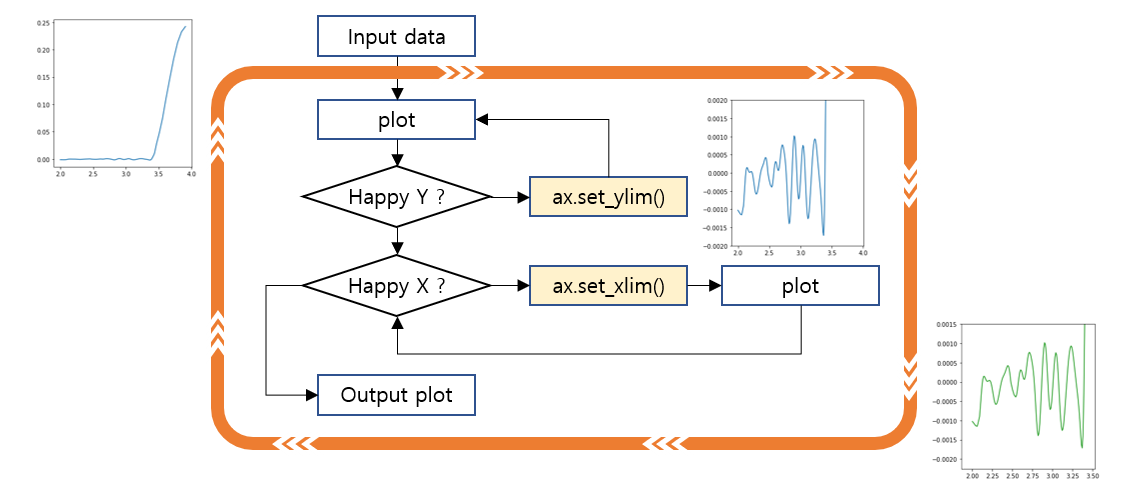
xs와ys의 원소는 모두 1차원numpy.ndarray()입니다.- 첫 번째와 마지막을 제외하면 y값이 특정 범위에 몰려 있음을 알 수 있습니다.
1 | for i in range(1,6): # 변수 이름을 동적으로 할당 |
- 몇 차례의 iteration을 통해 얻은 최적 범위로 그림을 그리면 이렇게 됩니다.
1 | ax[1].set_ylim(-0.015,0) # iteration 3회 결과 |
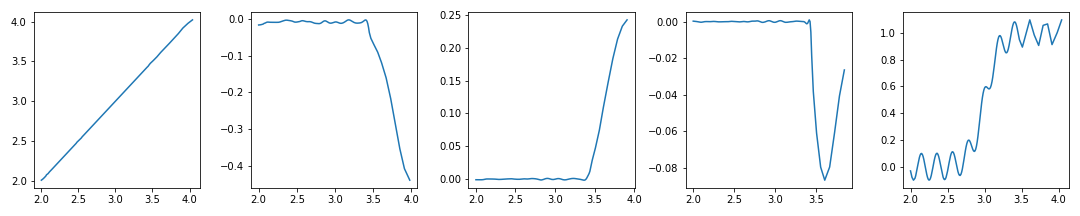
- 두 번째 ~ 네 번째 그래프에서 전체 범위에 묻혀있던 관심영역이 잘 드러났습니다.
- 첫 번째와 마지막 그래프는 전체가 관심영역이므로 가려지면 안 됩니다.
- 이런 범위 설정 작업을 반복하지 않도록 자동화하고 싶습니다.
2. data distribution
- 두 번째 ~ 네 번째 그래프에서 관심영역 외 부분이 단조증가 또는 감소하고 있습니다.
- 데이터의 빈도를 이용해 이 부분을 제거하고 관심영역에 집중합시다.
numpy.histogram()으로 y 데이터의 구간별 데이터 수를 확인합니다.
1 | res = 1000 |
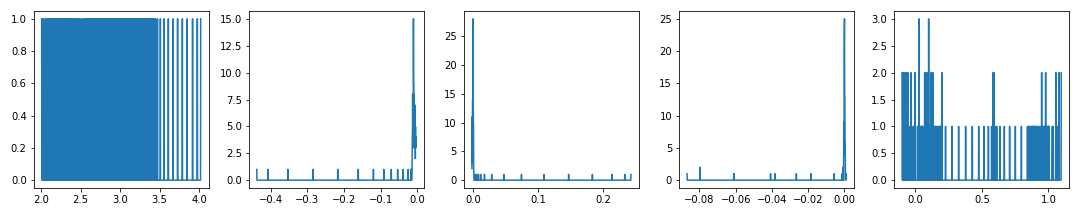
- 두 번째 이후의 그래프에서, 진동하는 구간에 많은 데이터가 몰린 것을 확인할 수 있습니다.
- 1000개 구간으로 충분히 잘게 나누었기 때문에 데이터가 없는 구간도 있습니다.
3. setting $$y$$ range by bin filtering
- 구간별 데이터 수가 일정(
yth) 이상인 구간만 추립니다. - 그러나 첫 번째 그래프처럼 데이터 수는 적어도 전체를 다 보여줘야 하는 경우가 있습니다.
- 이럴 때를 대비하여 관심영역이 딱히 없다면 전체 구간을 잡도록 예외처리합니다.
1 | res = 1000 |
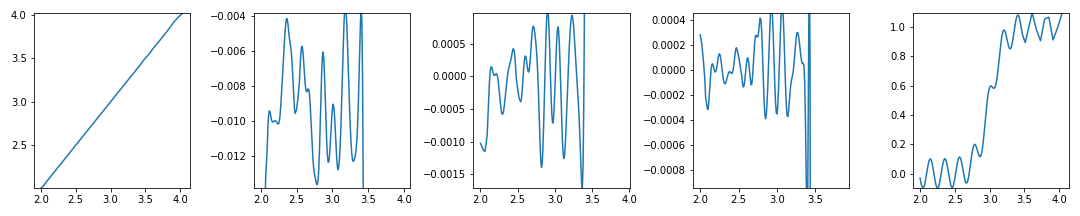
- y 범위가 너무 빡빡하게 잡혔네요. 여유를 좀 줍시다.
- y range를 계산해서, 사전에 정의된 여유분(
ymargin) 비율만큼 위아래로 더해줍니다.
1 | res = 1000 |
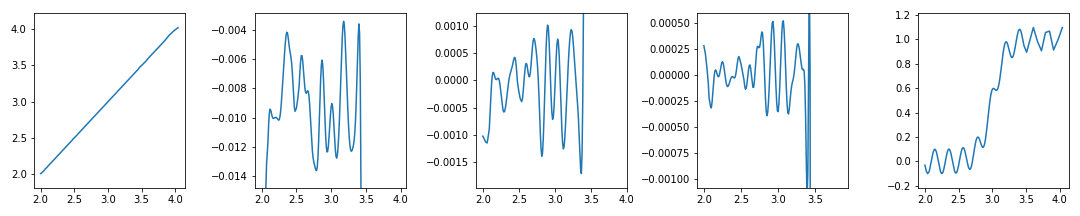
4. setting $$x$$ range by $$y$$ range
-
두 번째 ~ 네 번째 그래프 오른쪽이 비어있습니다.
-
관심영역이 왼쪽으로 치우친 탓입니다. x 범위도 다시 설정해서 그림을 꽉 차게 만들어줍시다.
-
위에서 만든 코드를 다시 사용하기 좋도록 함수로 정의하겠습니다. 주석도 달고요.
-
(2020.05.24) 버그를 발견하여 Bresenham’s line algorithm을 추가했습니다.
1 | class bresenham: |
- 이렇게 함수를 만들어두면 본 코드가 매우 짧아집니다.
1 | fig, axes = plt.subplots(ncols=5, figsize=(12,3)) |
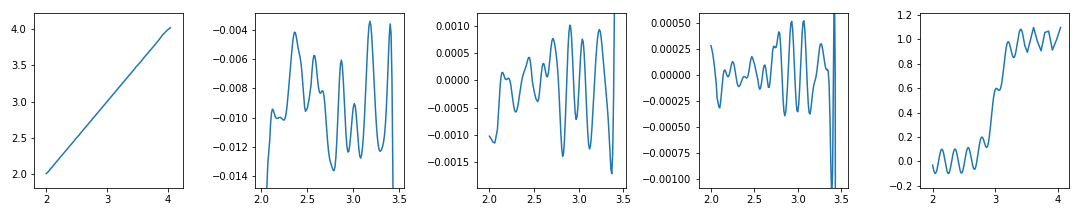
-
모든 그림이 관심영역에 집중되었습니다.
-
그러나 네번째 그림이 위쪽에 치우친 것이 영 마음에 걸리네요.
-
데이터 수로 구간을 설정해서 네 번째 데이터 우측의 진동이 잡혀버렸습니다.
-
네 번째 그래프에만 인자를 다르게 설정해서 가운데로 옮깁시다.
-
훨씬 엄격한 조건(
yth=3)과 관대한 여백(ymargin=0.2)을 조합합니다.
1 | fig, axes = plt.subplots(ncols=5, figsize=(12,3)) |
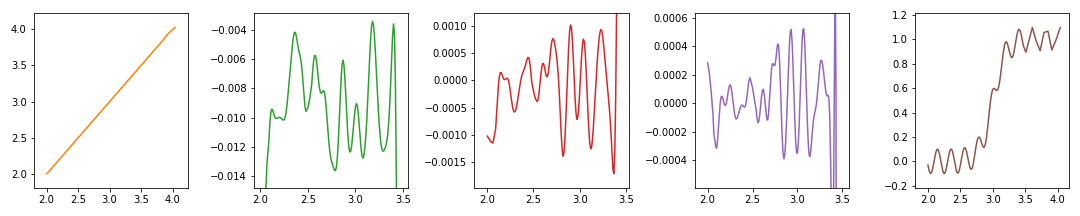
- 이제 웬만한 그래프는 자동으로 관심영역을 확대할 수 있습니다.
- 그러나 관심영역 밖에 중요한 메시지가 있을 수 있습니다.
- 반드시 전체를 먼저 확인한 후에 확대하고, 확대 후에도 제대로 됐는지 확인합시다.
5. Bug fix : missing bins (2020.05.24.)
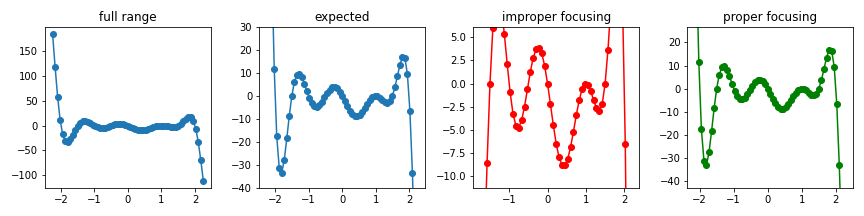
- 간혹 아래와 같이 전혀 의도치 않은 구간으로 확대되는 경우가 있었습니다.
1 | x = np.linspace(-2.25, 2.25, 61) |
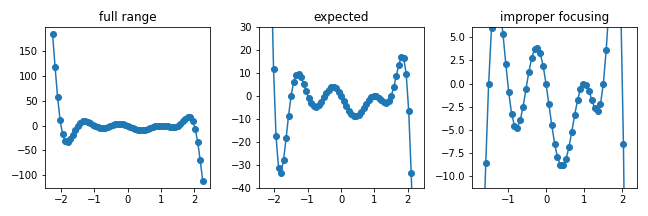
- 데이터를 선그래프로 표현하면 점과 점 사이가 이어져 데이터가 밀집한 구간을 히스토그램으로 처리할 수 있을 듯 하지만, 실제로 선에 해당하는 구간은 데이터가 존재하지 않아 빈도 측정시 관심영역으로 감지될 수 없습니다.
- 데이터가 교묘하게(?) 조금씩 위아래로 어긋나있을 때 이런 일들이 발생하는데, 이를 방지하기 위해 선을 전부 데이터로 채워주었습니다.
- 무한한 경우의 수를 모두 채울 수는 없으므로 공간을 적당히 이산화하고, 여기에 Bresenham’s line algorithm을 차용하였습니다.
5.1. Data quantization in different scales
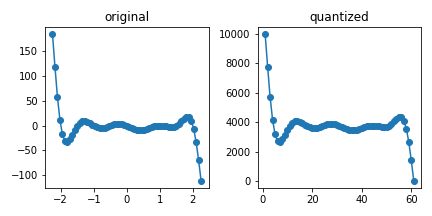
- 데이터를 정수 공간으로 매핑합니다: x, y scale이 달라졌습니다.
1 | xd = np.digitize(x, np.linspace(x.min(), x.max(), len(x))) |
5.2. Application of Bresenham’s line algorithm
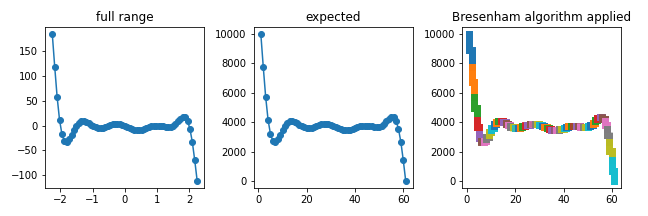
- 정수 공간에서 점 사이를 메웁니다.
1 | points = list(zip(xd, yd)) |
5.3. Map to Original scale
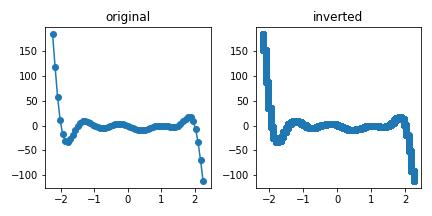
- 정수 공간에 메워진 데이터를 다시 원래의 공간으로 가져옵니다.
1 | def scale_inv(xscaled, x_num, x_arr): |
5.4. apply (previous) get_focus()
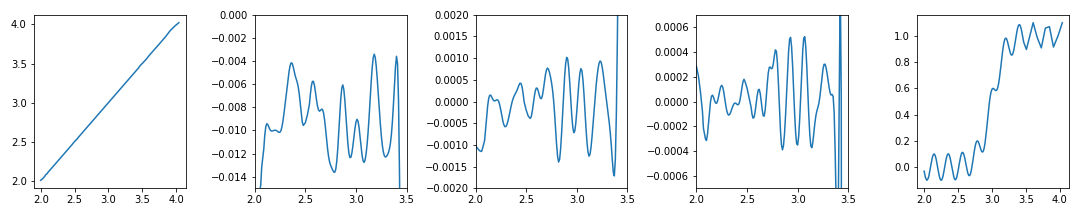
- 변환된 데이터에 앞의
get_focus()를 그대로 적용합니다. - 기대한 그래프(expected)와 비교했을 때 상당히 합리적인 범위로 조정되었음을 알 수 있습니다.
1 | ax[3].plot(x, y, 'o-', c='g') |
6. summary
- 위 5.1.~5.4.를
get_focus()안에 모두 탑재하였습니다. - 본 기능을 사용하실 때는
class bresenham과 함께get_focus()를 그대로 사용하시면 됩니다.
