Essence
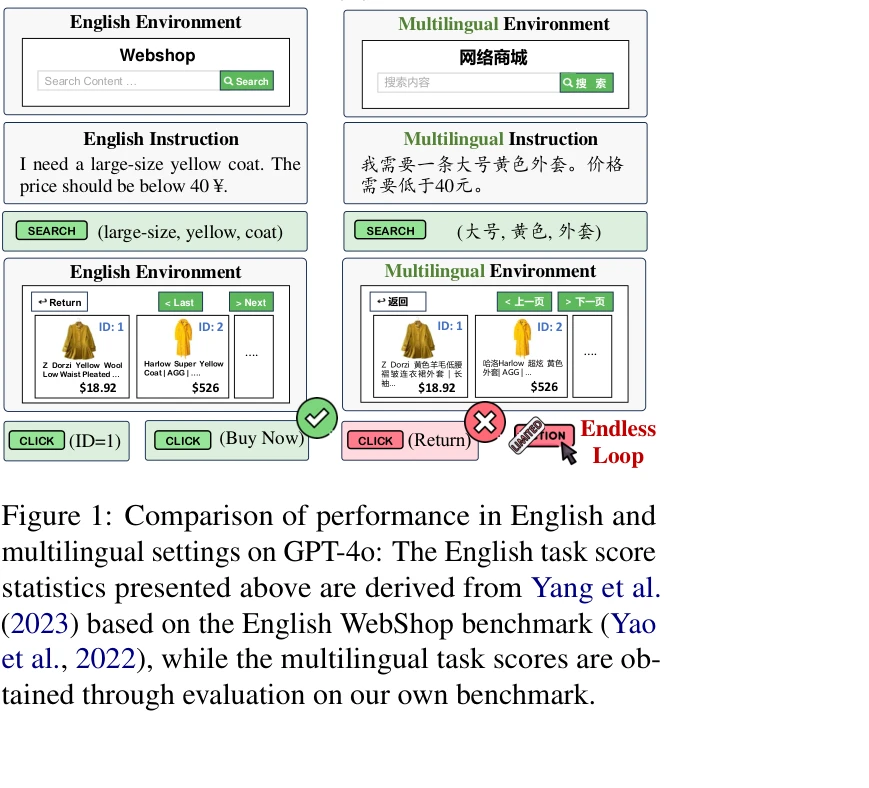
영어 환경과 다국어 환경에서 GPT-4o의 성능 비교: 다국어 환경에서 20% 이상 성능 저하 발생
본 논문은 대규모 언어모델(LLM) 기반 에이전트의 다국어 성능을 평가하기 위해 14개 언어, 2,800개의 지시문, 589,946개의 상품을 포함한 X-WebAgentBench 벤치마크를 제시한다. 기존 에이전트 벤치마크들이 영어 중심이었던 반면, 이 연구는 다국어 지시문과 다국어 환경을 동시에 포함한 최초의 종합적인 다국어 에이전트 평가 벤치마크를 구축하였다.
Achievement
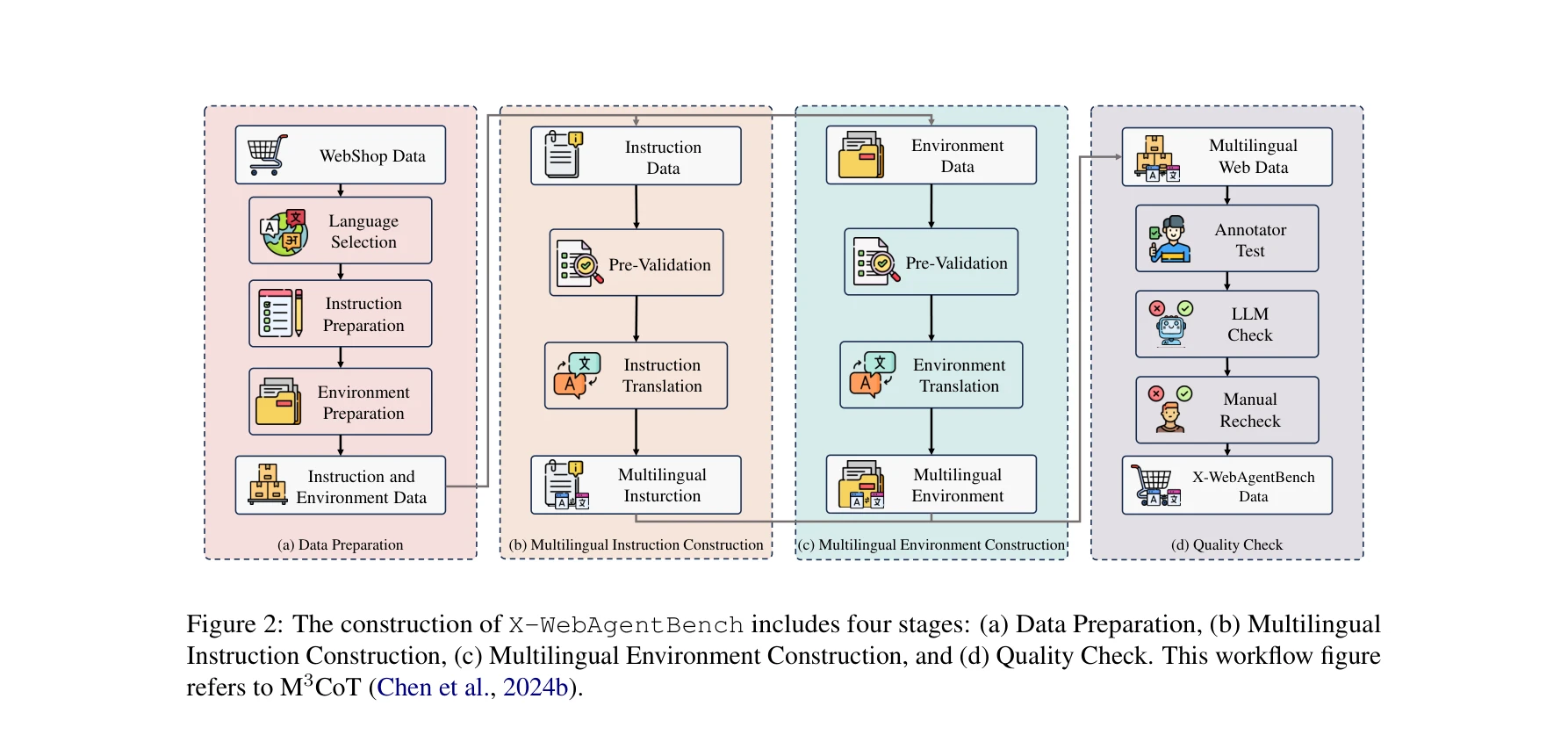
X-WebAgentBench 구축의 4단계: (a) 데이터 준비, (b) 다국어 지시문 구성, (c) 다국어 환경 구성, (d) 품질 검증
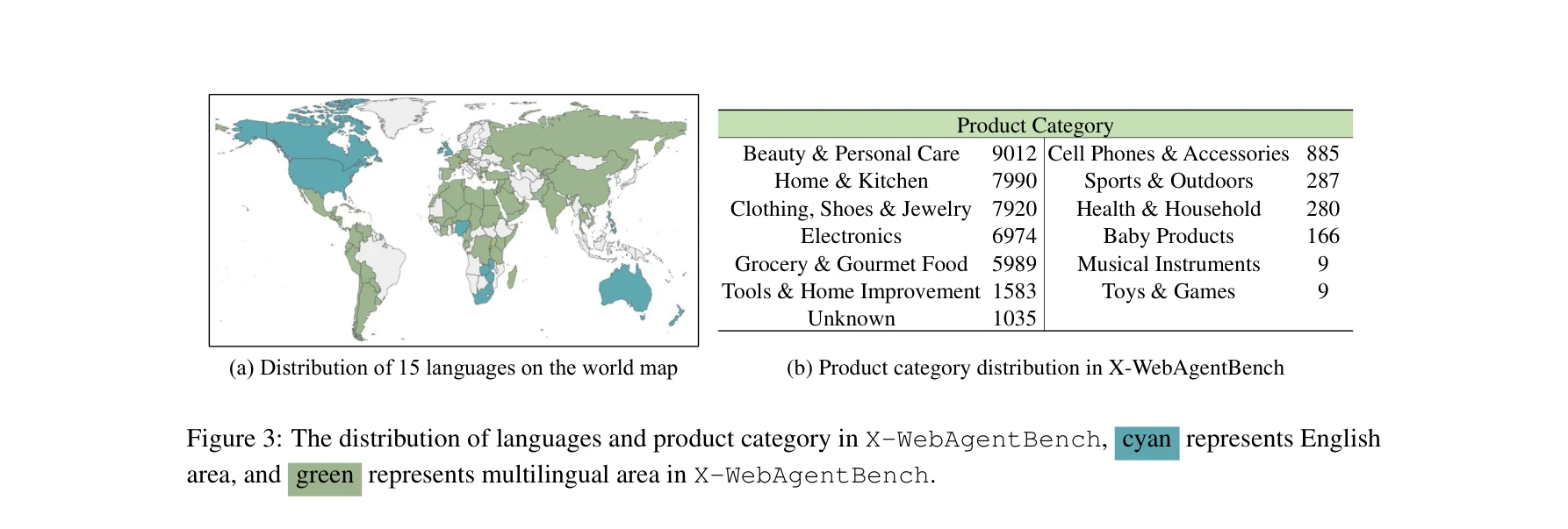
X-WebAgentBench의 언어 분포(15개 언어, 청색=영어 영역, 녹색=다국어 영역) 및 상품 카테고리 분포
- 벤치마크 구축: 14개 언어에 걸쳐 2,800개의 다국어 지시문과 589,946개의 다국어 상품 데이터를 포함한 첫 번째 종합적 다국어 에이전트 벤치마크 개발
- 성능 분석: 다양한 LLM과 교차언어 정렬(cross-lingual alignment) 방법의 효과를 체계적으로 평가하여, (a) 큰 모델의 경우 고급 교차언어 정렬이 성능을 크게 향상시키고, (b) 작은 모델의 경우 다국어 환경을 영어로 번역하는 것이 효과적이며, (c) 기존 에이전트 기법과 교차언어 기법의 단순 조합은 불충분함을 입증
- 품질 보증: 50개 제품에 대한 사전 검증을 통해 Google Translate(90% 이상)와 GPT-4 (74%)의 번역 정확도를 비교하고, 환경 데이터 번역에는 GPT-4를 선택하여 문맥적 뉘앙스를 정확히 포착
Evaluation
Novelty: 4.5/5 Technical Soundness: 4/5 Significance: 4.5/5 Clarity: 4/5 Overall: 4.2/5
총평: X-WebAgentBench는 다국어 에이전트 연구의 중요한 공백을 채운 첫 번째 종합적 벤치마크로서 학술적·실무적 가치가 높으며, 체계적인 품질 관리 방식이 돋보인다. 다만 전자상거래 도메인 중심, 상대적으로 작은 지시문 규모, 자동 번역의 근본적 한계 등으로 인해 추가 확장과 개선 여지가 있다.