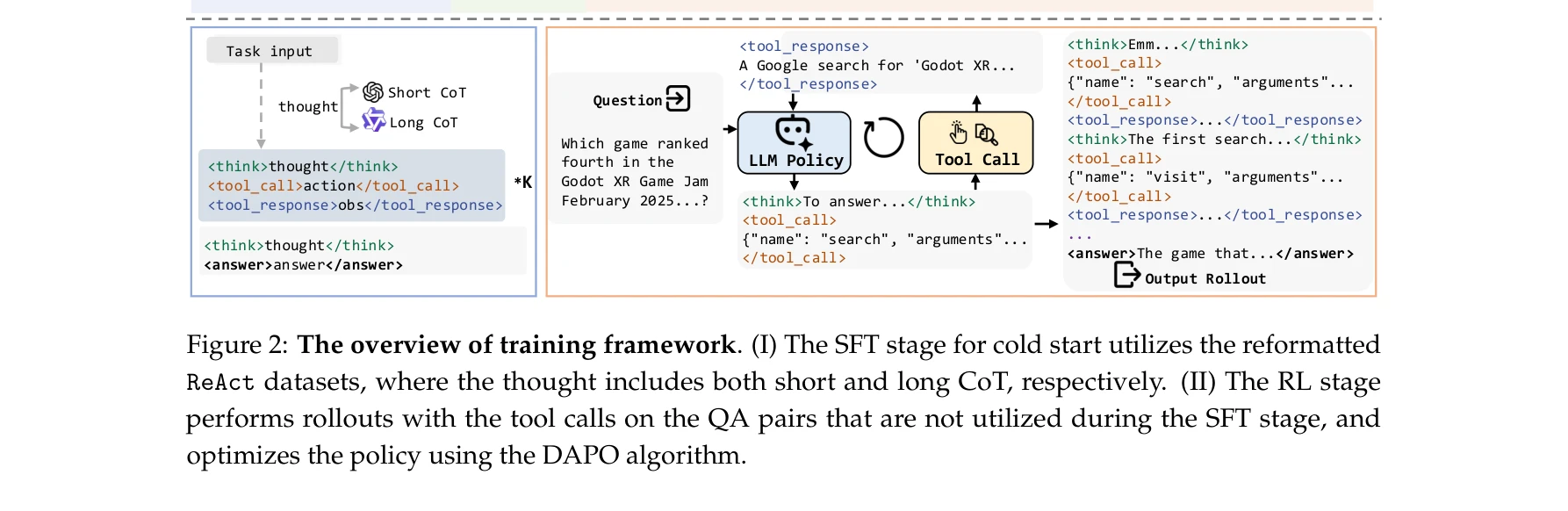
Essence
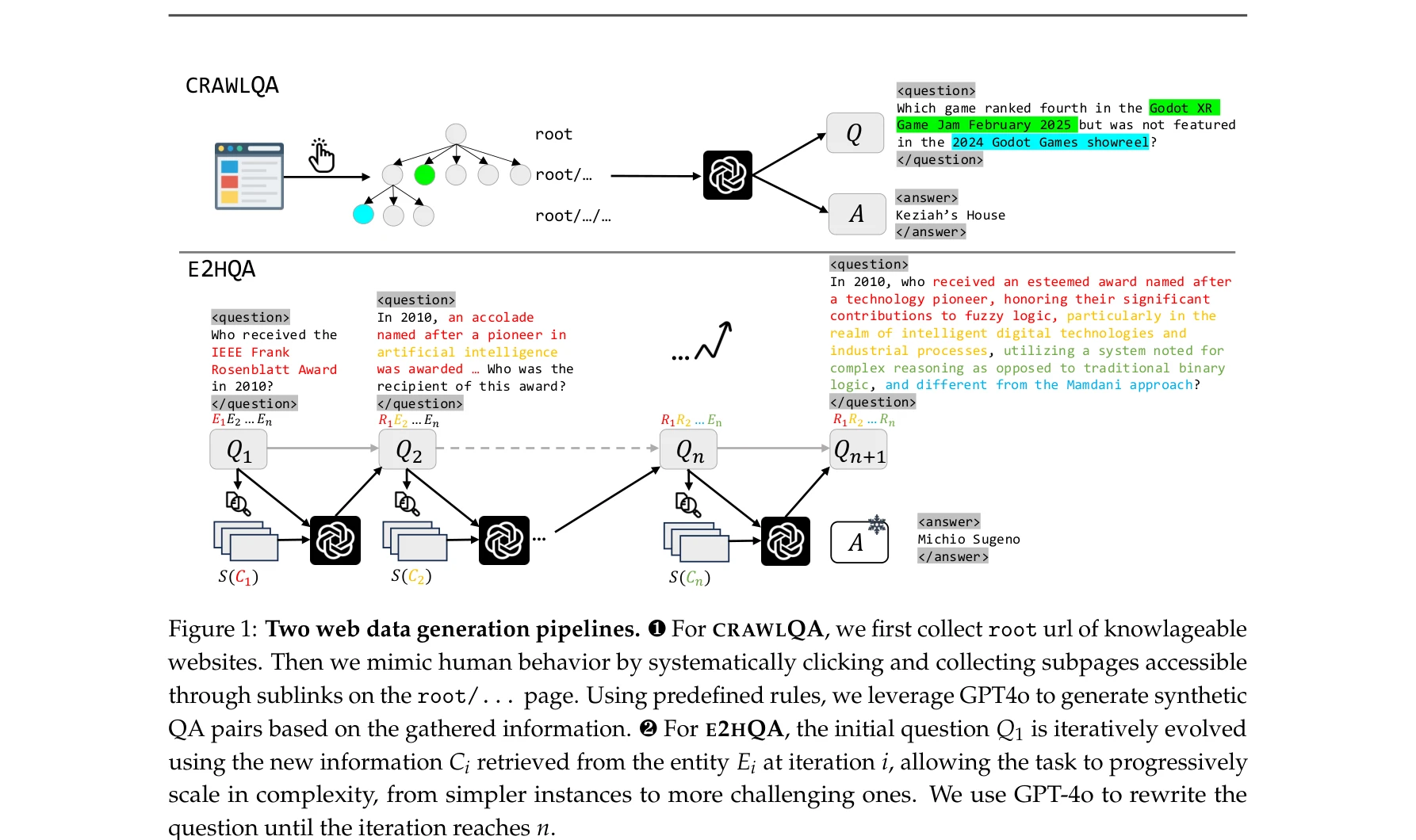
그림 1: CRAWLQA와 E2HQA 두 가지 웹 데이터 생성 파이프라인. CRAWLQA는 웹 페이지 크롤링을 통해 깊이 있는 질문을 구성하고, E2HQA는 간단한 질문을 반복적으로 복잡하게 변환하여 멀티스텝 추론을 요구하는 QA 쌍을 생성한다.
본 논문은 웹 환경에서 자율적 정보 탐색을 수행하는 에이전트(WebDancer)를 구축하기 위한 체계적 파이프라인을 제시한다. 데이터 중심의 관점에서 고품질 탐색 데이터와 궤적(trajectory)을 생성하고, 감독학습(SFT)과 강화학습(RL)을 순차적으로 적용하여 멀티스텝 정보 탐색 능력을 갖춘 에이전트를 학습시킨다.