Essence
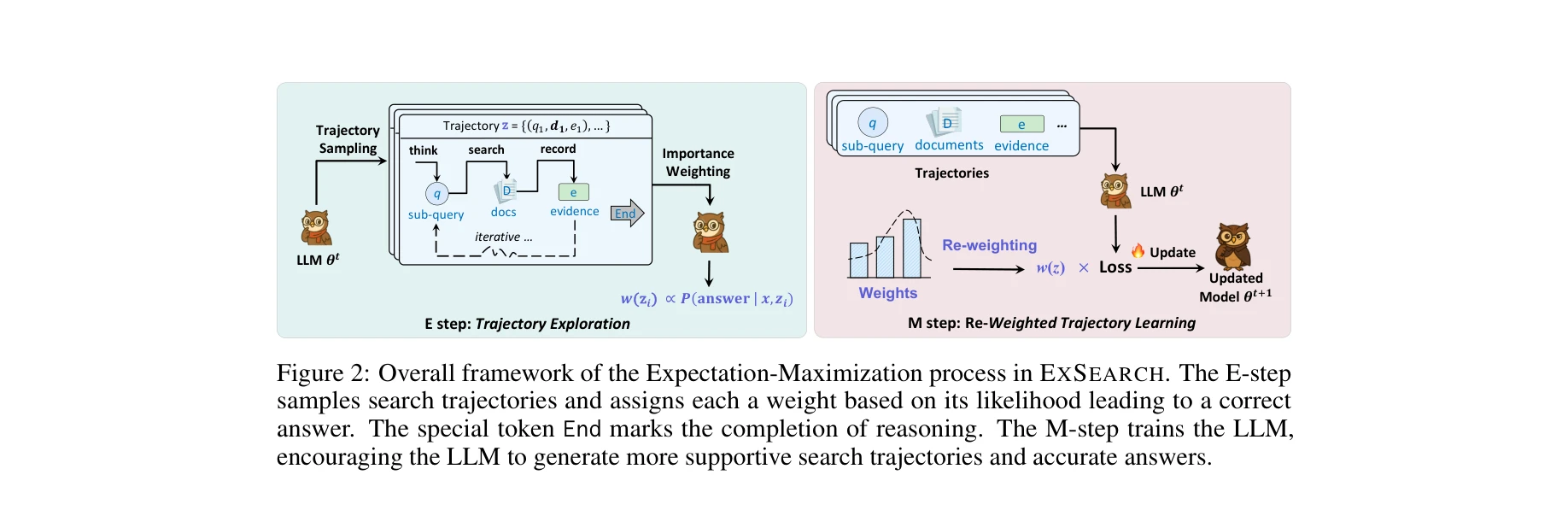
그림 2: EXSEARCH의 Expectation-Maximization 프로세스 개요. E-step에서는 탐색 궤적을 샘플링하고 가중치를 할당하며, M-step에서는 재가중치 손실함수로 LLM을 학습시킨다.
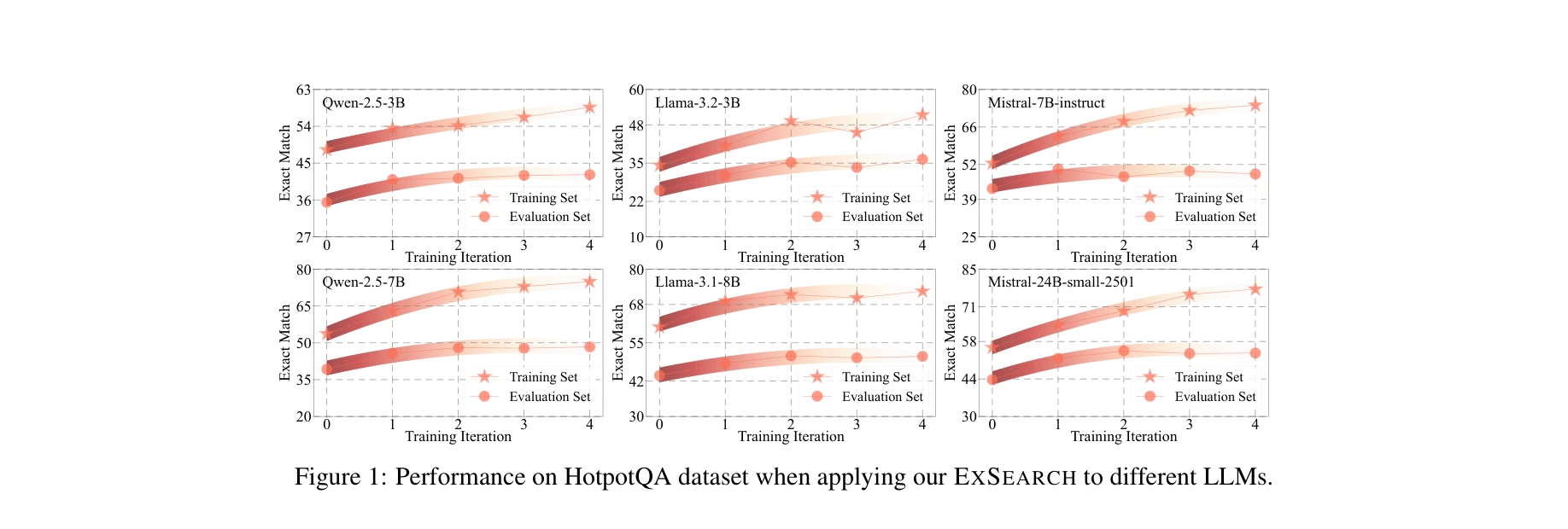
본 논문은 대규모 언어모델(LLM)을 정보 검색 에이전트로 자동 개선하는 자기-인센티브화 기반 탐색 프레임워크(EXSEARCH)를 제안한다. 일반화 EM 알고리즘을 통해 검색 궤적을 잠재변수로 취급하고, LLM이 생성한 데이터로부터 반복적으로 학습하는 자기 루프를 형성한다.
How
핵심 방법론:
- 검색 궤적 모델링: 각 단계에서 사고(thinking: 쿼리 생성) → 검색(search: 외부 리트리버 호출) → 기록(recording: 세부 증거 추출)의 3가지 액션을 반복 수행
$$p(z | x; \theta) = \prod_{i=1}^{|z|} p(x_i | x, z_{
- E-step (궤적 탐색): 현재 LLM(θ_t)이 생성한 후보 궤적 z에 대해 중요도 가중치 할당
$$w(z) \propto p(y | x, z; \theta_t)$$
(궤적이 정답을 얼마나 잘 지원하는지 반영)
- M-step (재가중 학습): ELBO 최대화로 모델 업데이트
$$\max_\theta \mathbb{E}_{z \sim p(z|x;\theta_t)} [w(z) \log p(z|x;\theta) + w(z) \log p(y|x,z;\theta)]$$
여기서 첫 항은 검색 학습(L_R), 두 번째 항은 답변 생성 학습(L_A)을 담당
- 자기-인센티브 루프: E-step과 M-step을 반복 수행하여 LLM이 자신의 생성 데이터로부터 점진적으로 학습