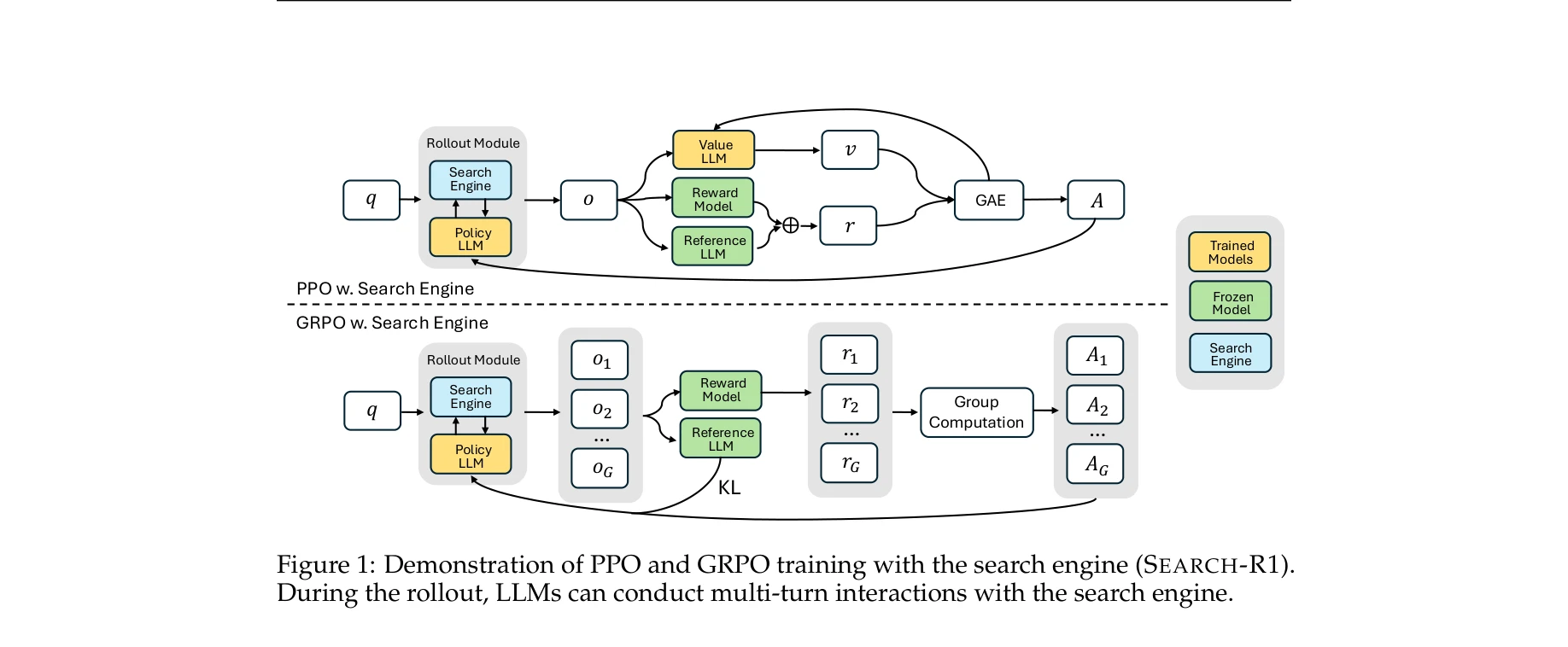
How
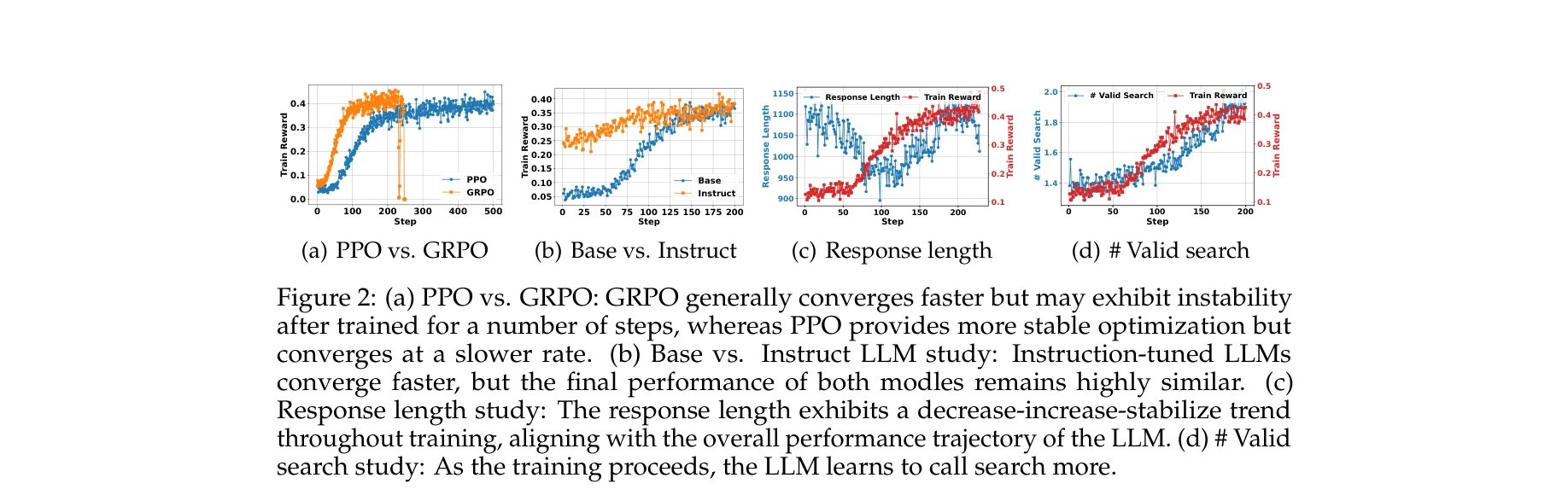
Figure 2: PPO vs GRPO 수렴 비교
RL 객체 함수 (검색 엔진 통합):
- 정책 LLM πθ가 입력 x에서 검색 엔진 R과의 상호작용을 포함한 출력 y 샘플링
- KL 발산으로 참조 정책으로부터의 편향 제어
핵심 기술:
- 손실 마스킹: 검색된 토큰(I(yt)=0)은 정책 그래디언트 계산에서 제외, LLM 생성 토큰만 최적화
- PPO 적용: 식 (2)에서 클리핑된 정책 비율을 사용한 제약된 목적 함수
```
J_PPO(θ) = min(πθ/π_old · A, clip(πθ/π_old, 1-ε, 1+ε) · A)
```
- GRPO 적용: 그룹 상대 정책 최적화로 비평가 모델 제거, 그룹 점수에서 베이스라인 추정
- 토큰 구조:
- 보상 함수: 결과 기반 보상(rϕ)만 사용 (과정 기반 보상 미사용)
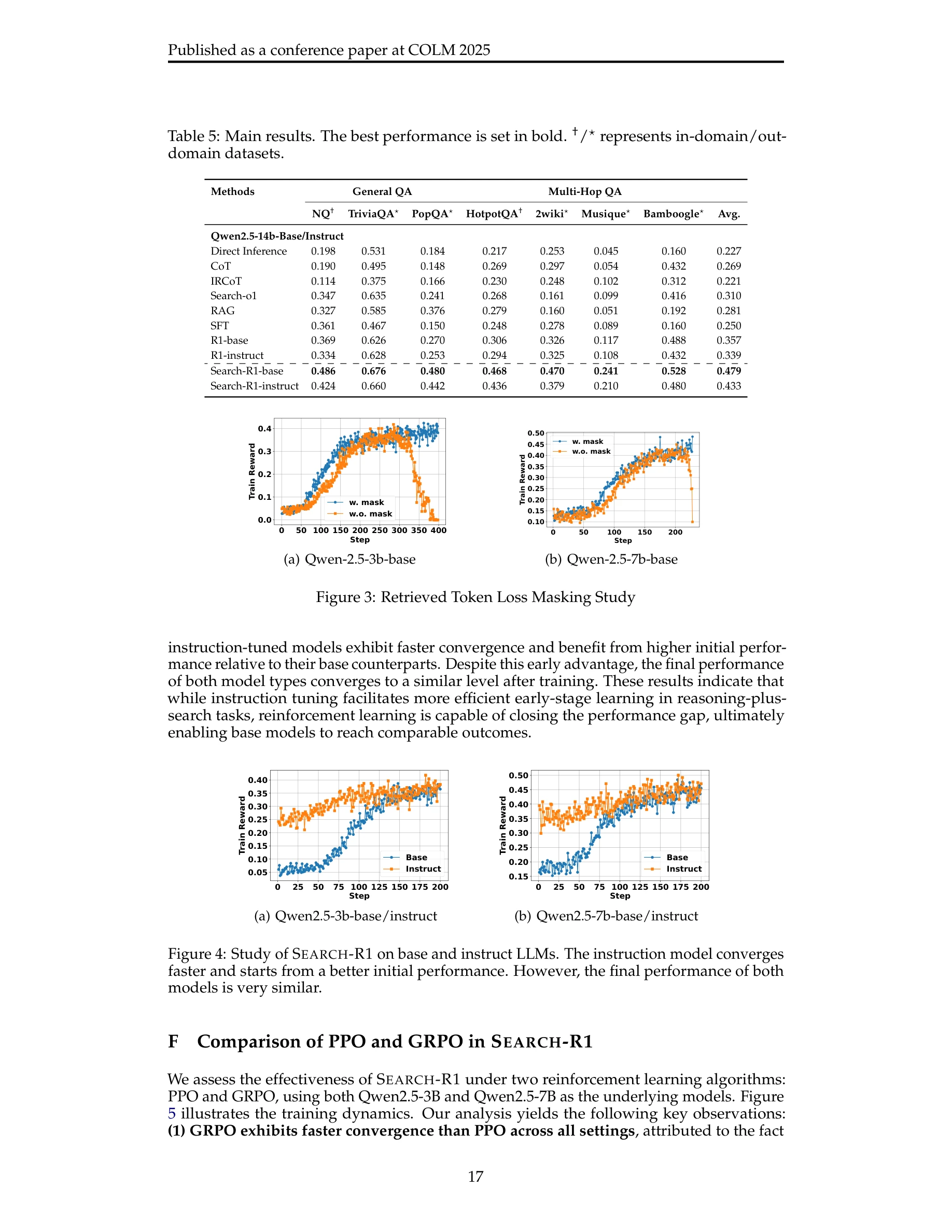
Figure 3: 검색된 토큰 손실 마스킹 연구
Evaluation
총평: Search-R1은 검색 엔진 호출을 RL 최적화에 체계적으로 통합한 실용적 프레임워크로, 강력한 실험 결과와 구현 상세함이 강점이나, 이론적 깊이와 계산 효율성에 대한 추가 분석이 요구된다.