How
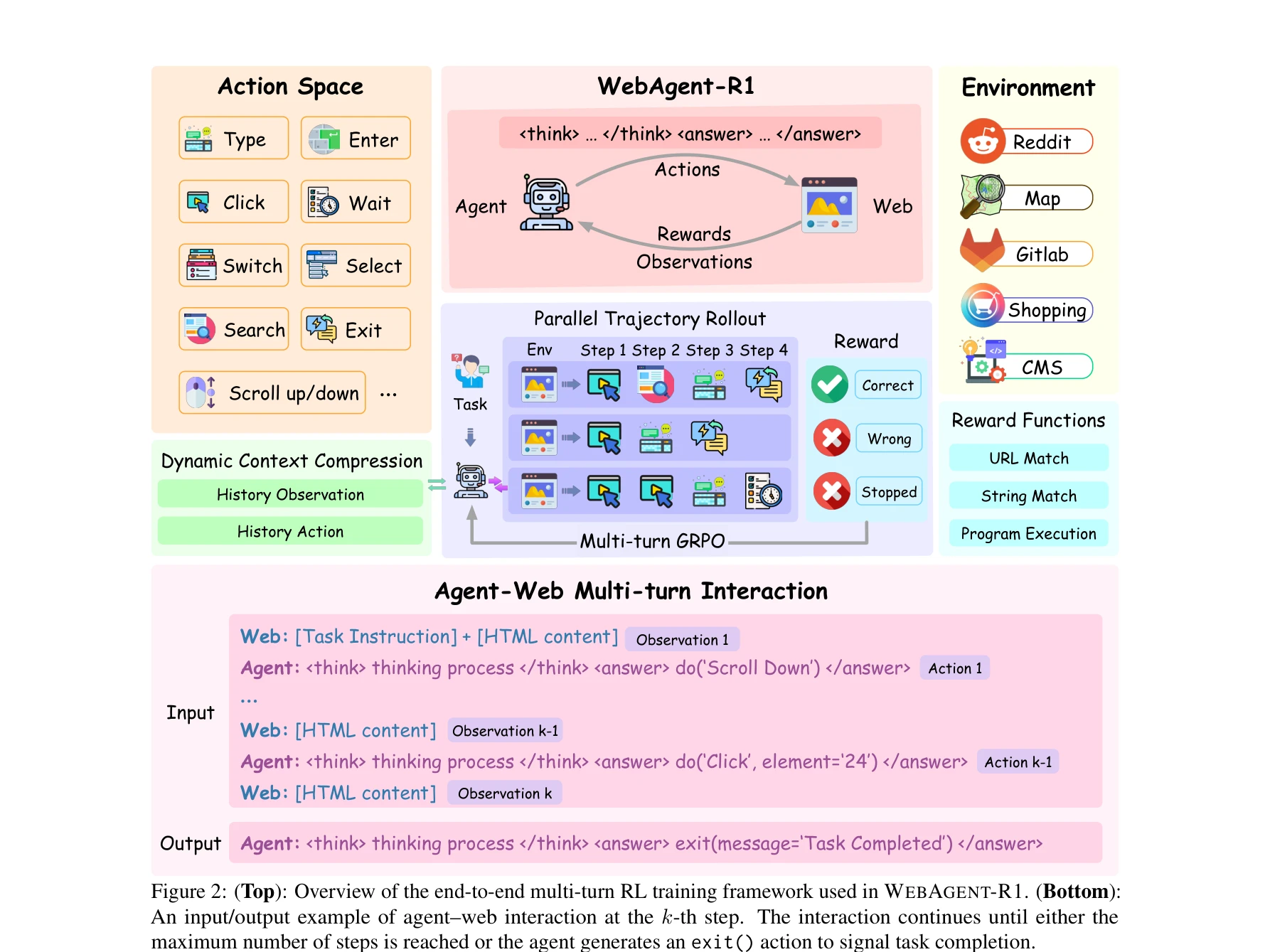
WebAgent-R1의 종단 간 다중턴 RL 훈련 프레임워크 개요
핵심 메커니즘
- 행동 복제 초기화: 전문가 데이터셋을 이용한 SFT로 기본적인 웹 상호작용 능력 습득 (s1, a1, s2, a2, ... st 형태의 상호작용 히스토리 학습)
- 동적 컨텍스트 압축: 이전 관측값들을 단순화된 템플릿(예: "Simplified HTML")으로 축약하면서 전체 행동 히스토리는 보존. 메모리 오버헤드를 줄이면서도 충분한 컨텍스트 유지
- 병렬 궤적 롤아웃: 여러 궤적을 병렬로 생성하여 샘플링 효율 증대 및 다양한 탐색 전략 학습
- M-GRPO 알고리즘: GRPO(Group Relative Policy Optimization)를 다중턴 설정으로 확장. 이진 결과 보상(Binary Outcome Reward)을 기반으로 정책 최적화
- 앙상블 보상 함수: 문자열 매칭(String Match), URL 매칭, 프로그램 실행(Program Execution) 등 규칙 기반 보상으로 외부 모델 의존성 제거
상호작용 형식
```
Web: [Task] + [HTML content]
Agent: reasoning do('Action')
Web: [Updated HTML]
...반복...
Agent: exit(message='Task Completed')
```
Evaluation
총평: 본 논문은 웹 에이전트 학습의 실무적 과제(메모리, 외부 감독)를 창의적으로 해결하여 상당한 성능 향상을 달성했으며, 온폴리 강화학습의 다중턴 상호작용 환경으로의 확장을 성공적으로 입증한 의미 있는 기여이다.
