Essence
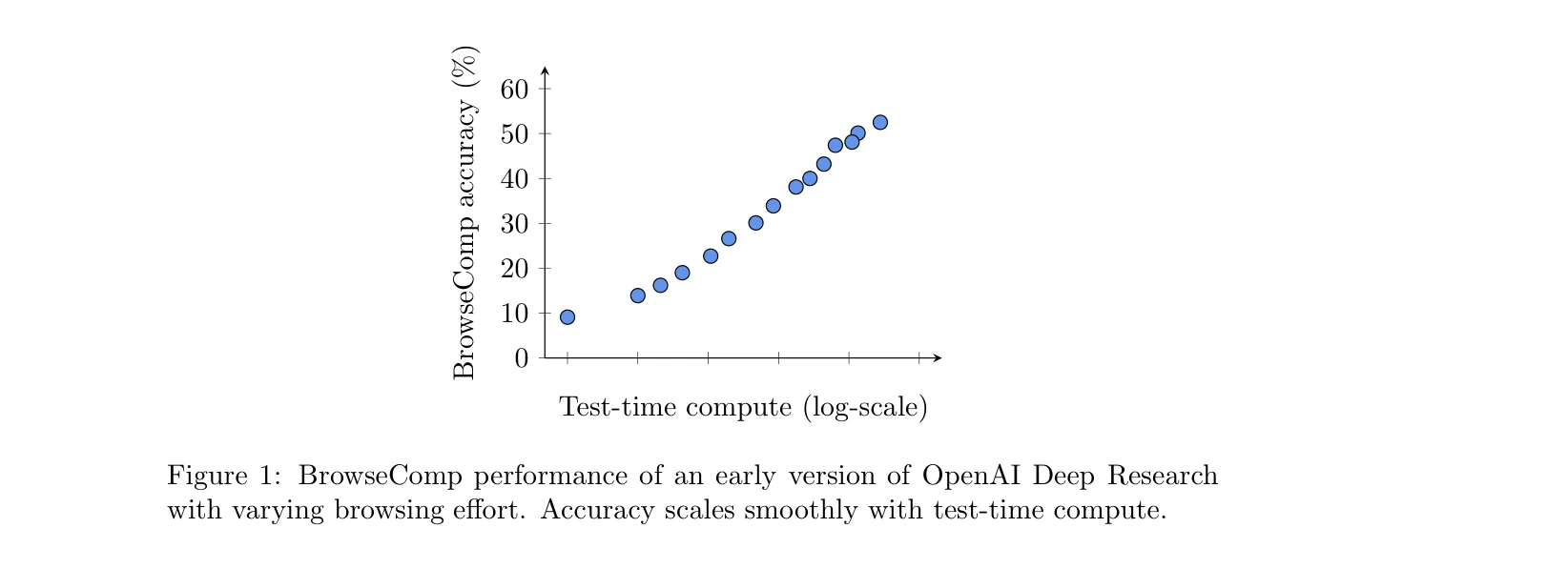
Figure 1: 테스트 시 계산량(browsing effort)에 따른 OpenAI Deep Research의 BrowseComp 성능. 정확도가 계산량에 비례하여 증가
웹 에이전트의 능력을 평가하기 위해 1,266개의 어려운 질문으로 구성된 BrowseComp 벤치마크를 제시한다. 이 벤치마크는 깊이 있는 웹 탐색과 창의적인 검색 능력을 요구하면서도 답변이 짧고 검증이 용이한 특징을 갖는다.
저자: J. Wei, Zhiqing Sun, Spencer Papay, Steve McKinney, Jeffrey S. Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, Amelia Glaese | 날짜: 2025 | DOI: N/A
Figure 1: 테스트 시 계산량(browsing effort)에 따른 OpenAI Deep Research의 BrowseComp 성능. 정확도가 계산량에 비례하여 증가
웹 에이전트의 능력을 평가하기 위해 1,266개의 어려운 질문으로 구성된 BrowseComp 벤치마크를 제시한다. 이 벤치마크는 깊이 있는 웹 탐색과 창의적인 검색 능력을 요구하면서도 답변이 짧고 검증이 용이한 특징을 갖는다.
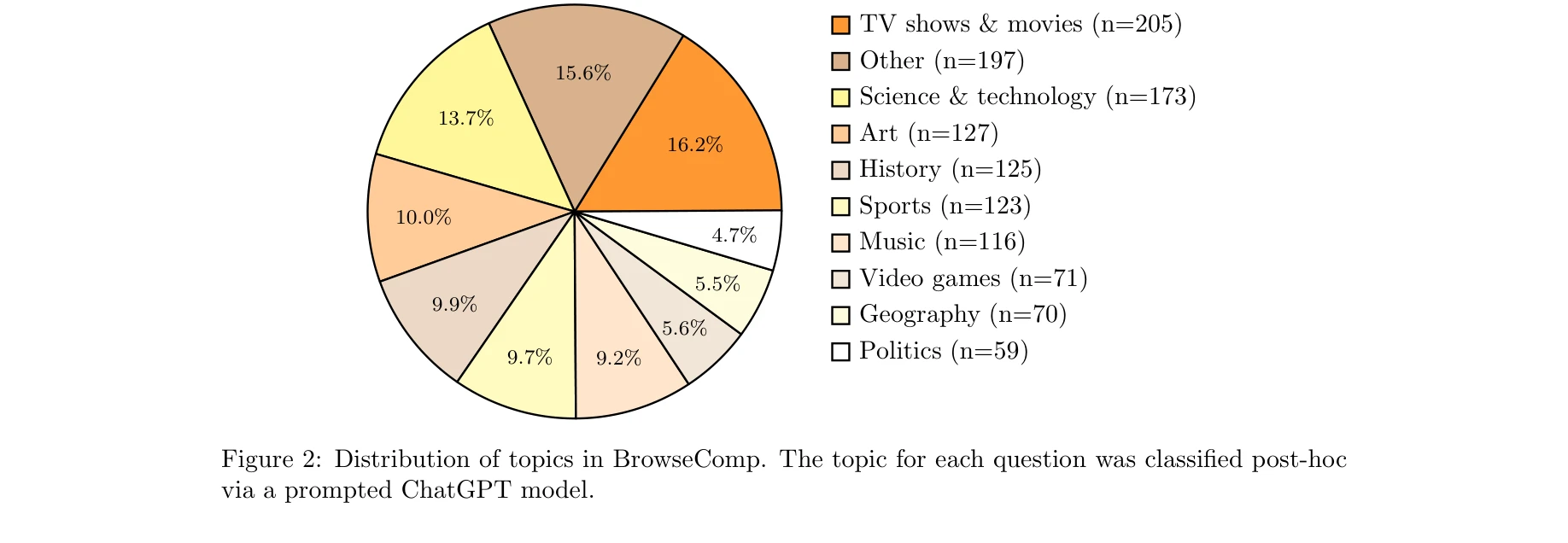
Figure 2: BrowseComp의 주제 분포. TV/영화(16.2%), 과학기술(13.7%), 미술(10.0%) 등 다양한 영역 커버
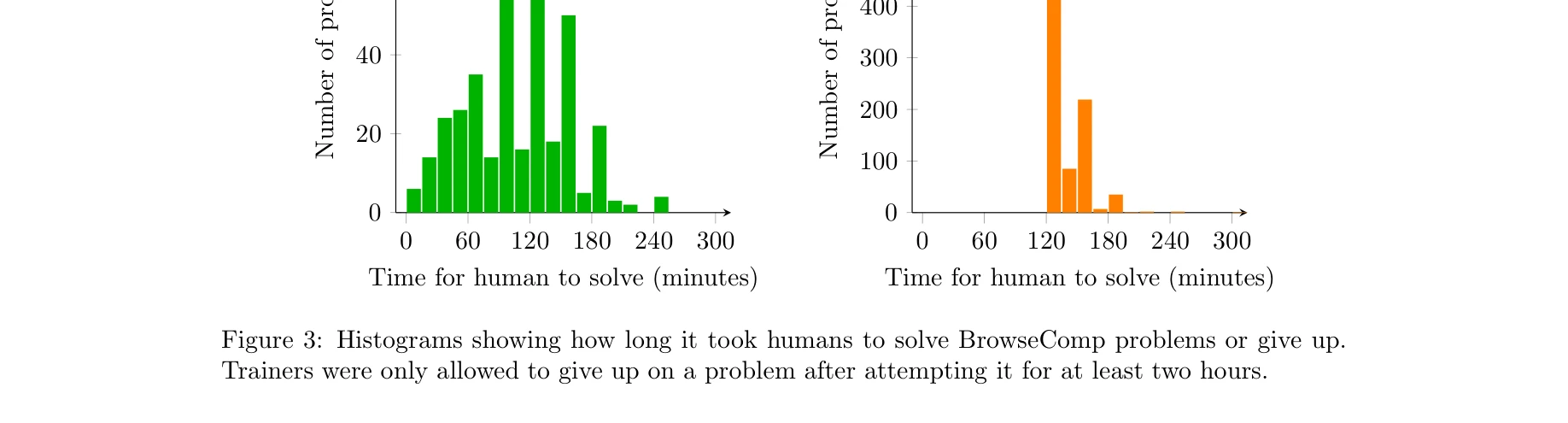
Figure 3: 인간이 문제를 해결한 시간 분포(좌)와 포기한 시간 분포(우). 해결된 문제는 1시간부터 3시간까지 분산, 포기된 경우 대부분 2시간 근처
데이터 수집 및 검증 방법론:
총평: BrowseComp는 급성장하는 웹 에이전트 분야에 명확한 표준을 제공하는 실용적이고 잘 설계된 벤치마크이지만, 실제 사용자 요구(긴 답변, 모호성 해결)를 포함한 확장이 향후 필요하다.