Essence
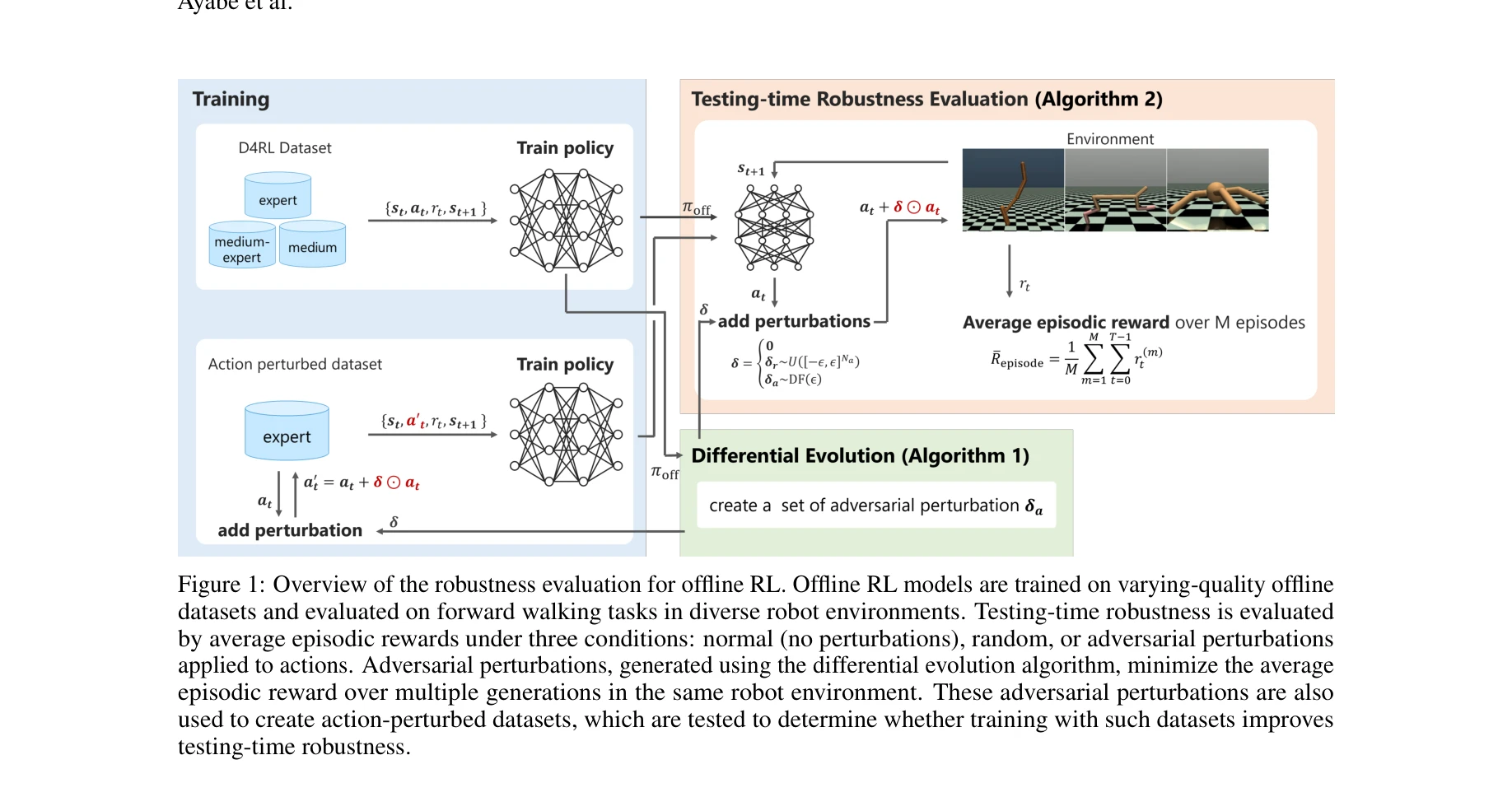
오프라인 RL의 견고성 평가 개요: 다양한 품질의 오프라인 데이터셋에서 학습한 모델을 정상, 랜덤, 적대적 행동 섭동 조건에서 평가
본 논문은 오프라인 강화학습(Offline RL)이 로봇 제어에서 행동 공간의 섭동(action perturbations)에 대해 얼마나 취약한지를 체계적으로 평가하고, 기존의 온라인 RL 방법보다 더 큰 약점을 가짐을 실증적으로 증명한다.
저자: Shingo Ayabe, Takuto Otomo, Hiroshi Kera, Kazuhiko Kawamoto (Chiba University) | 날짜: 2024 | DOI: arXiv:2412.18781
오프라인 RL의 견고성 평가 개요: 다양한 품질의 오프라인 데이터셋에서 학습한 모델을 정상, 랜덤, 적대적 행동 섭동 조건에서 평가
본 논문은 오프라인 강화학습(Offline RL)이 로봇 제어에서 행동 공간의 섭동(action perturbations)에 대해 얼마나 취약한지를 체계적으로 평가하고, 기존의 온라인 RL 방법보다 더 큰 약점을 가짐을 실증적으로 증명한다.
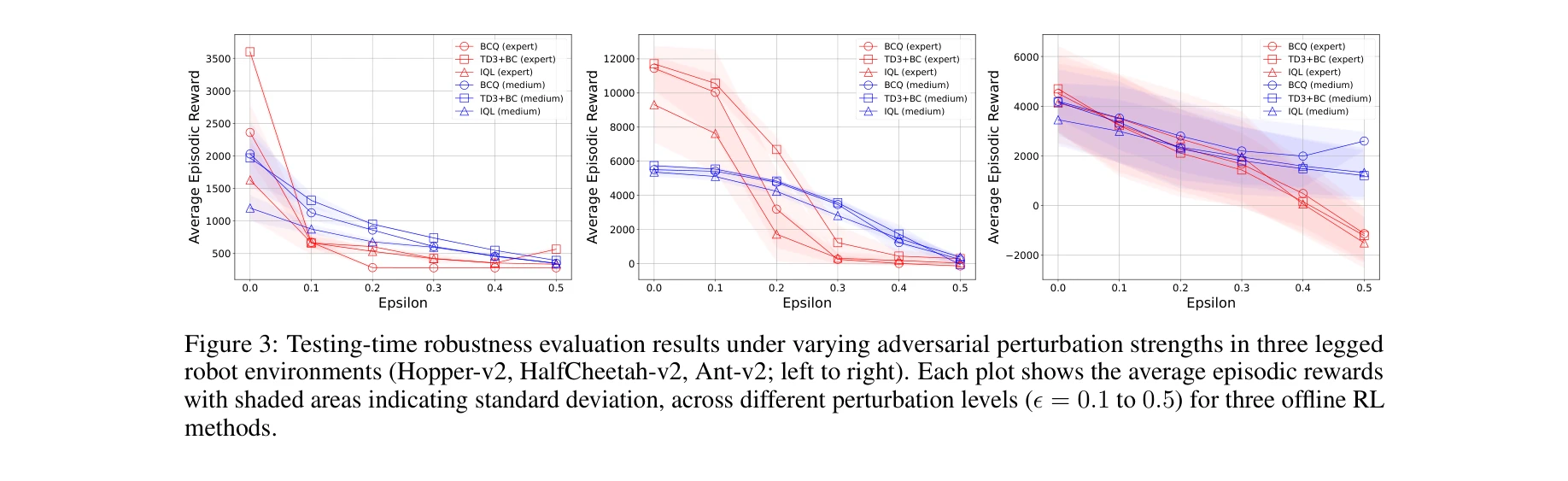
세 가지 다리 로봇에서 적대적 섭동 강도 변화에 따른 테스트 시간 견고성 평가 결과

훈련 데이터셋의 행동 분포 및 상태-행동 커버리지: 더 나은 커버리지를 가진 데이터셋이 더 견고한 정책을 생성
총평: 본 논문은 오프라인 RL의 행동 공간 섭동에 대한 취약성을 처음으로 체계적으로 드러냄으로써 중요한 안전성 문제를 제기한다. 다만 문제 제시에 머물고 해결책이 부족하며, 실제 로봇 환경에서의 검증이 필요하다는 점이 제약이다.