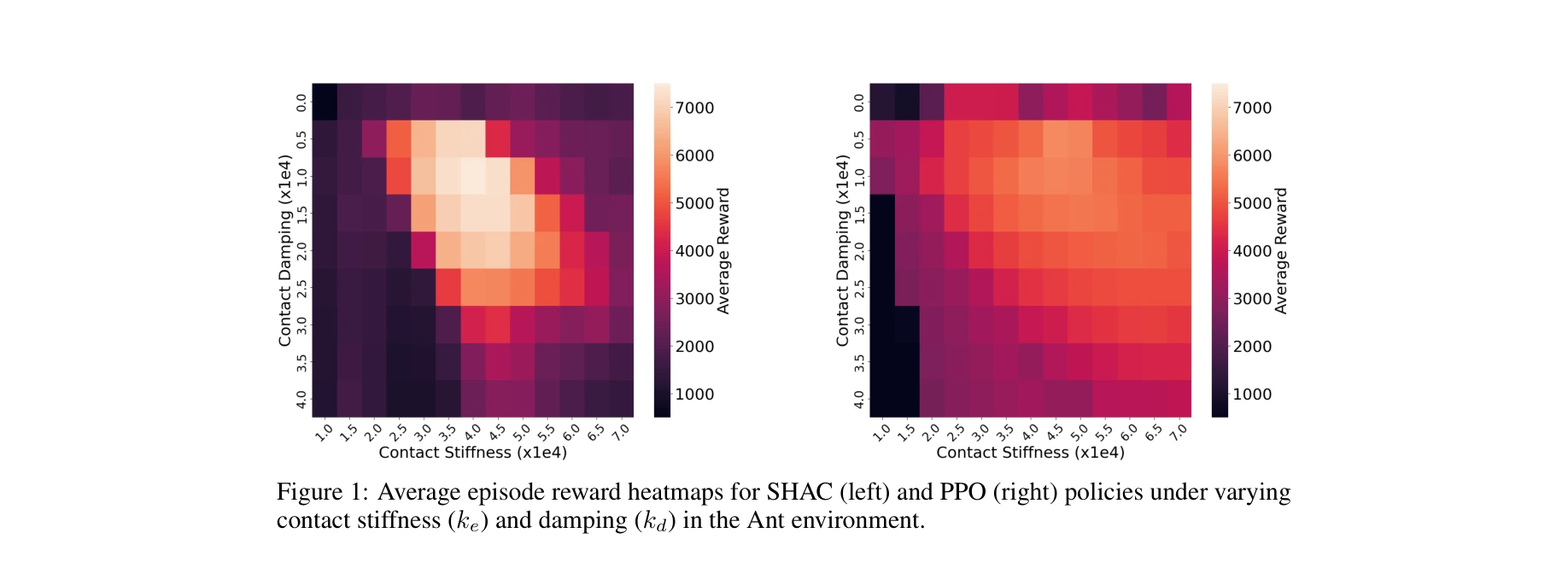
Achievement
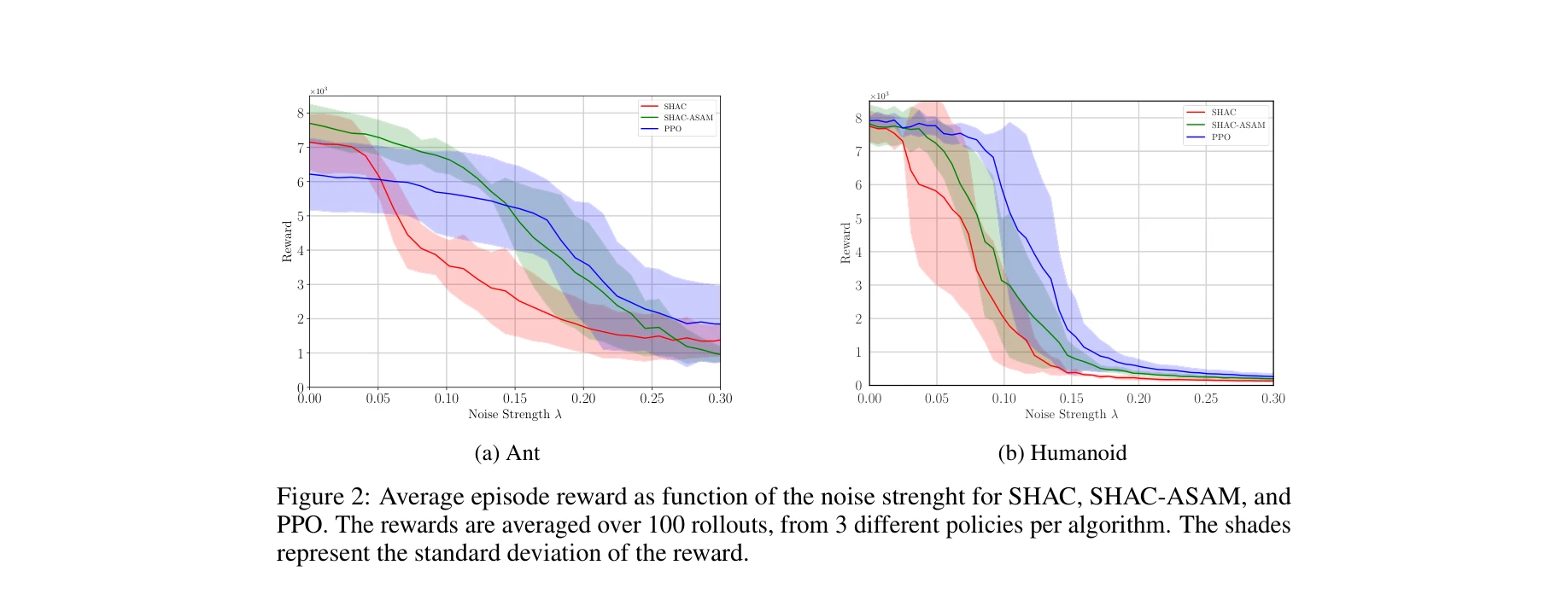
액션 노이즈 강도에 따른 평균 에피소드 보상 비교
- 강건성 향상: SHAC-ASAM이 표준 SHAC 대비 액션 노이즈(action noise)에 대해 유의미하게 높은 허용 범위 달성. 특히 Ant와 Humanoid 환경에서 노이즈가 증가해도 성능 저하가 적음
- 일반화 성능: 0차 방법(PPO)과 유사한 수준의 일반화 성능을 달성하면서도 1차 방법의 샘플 효율성 유지
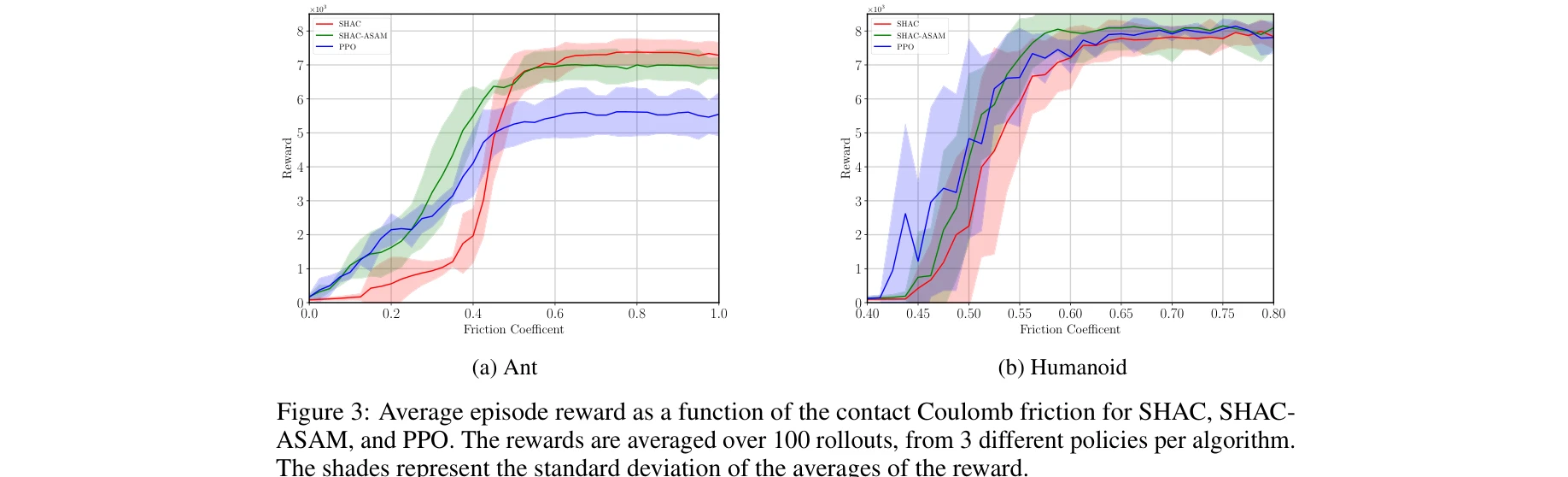
접촉 마찰 계수 변화에 따른 성능 비교
- 환경 변동성 대응: 쿨롱 마찰(Coulomb friction) 등 환경 파라미터 변화에 대한 적응 능력 향상