Essence
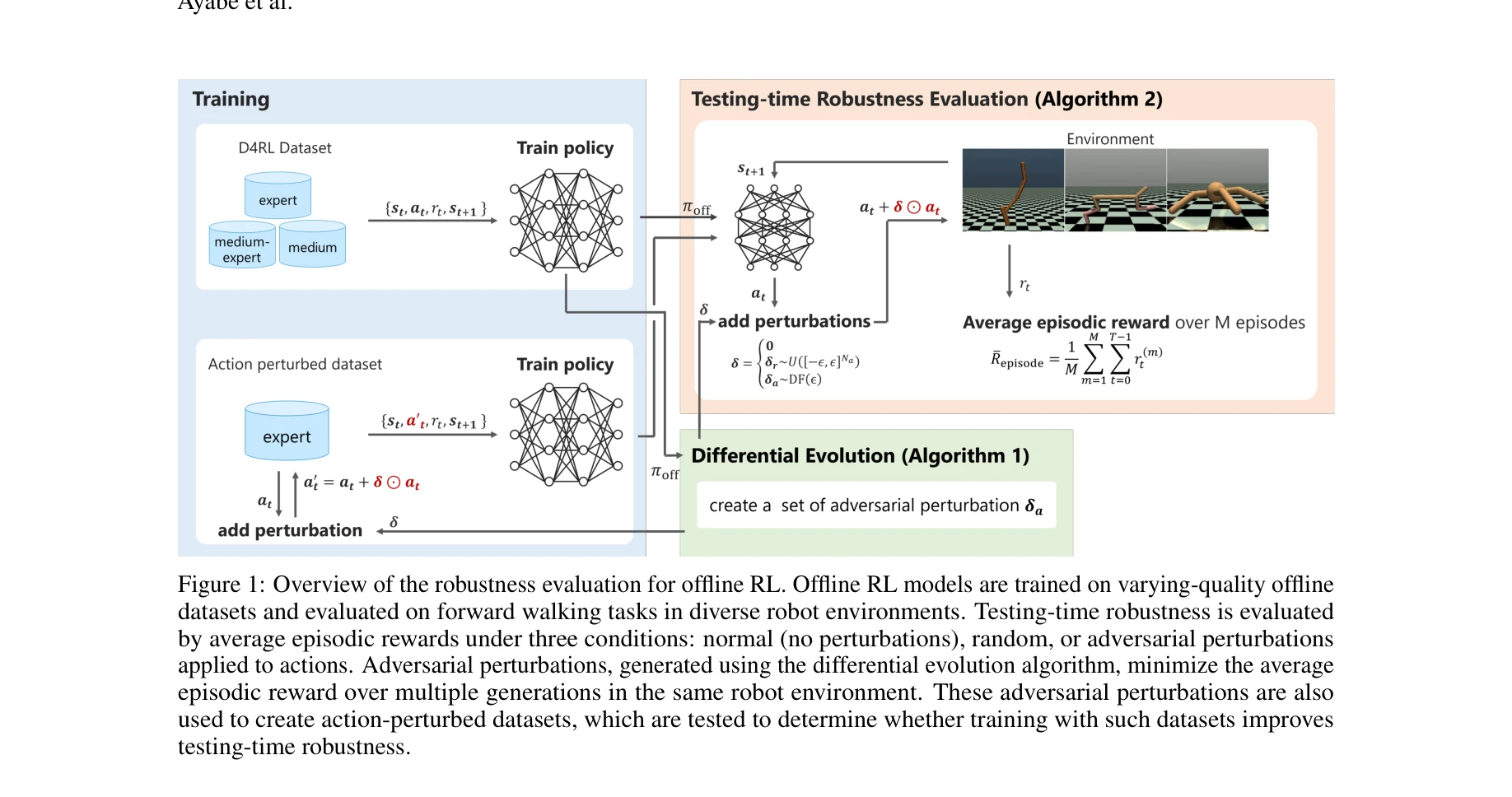
오프라인 강화학습의 견고성 평가 개요: 다양한 품질의 오프라인 데이터셋으로 학습된 모델을 정상, 랜덤, 적대적 섭동 조건에서 평가
본 논문은 오프라인 강화학습(Offline RL) 기반 로봇 제어 시스템의 행동 공간 섭동에 대한 견고성을 체계적으로 평가하며, 기존 오프라인 RL 방법들이 액추에이터 고장과 같은 실제 운영 환경의 도전에 얼마나 취약한지를 실증적으로 증명한다.
저자: Shingo Ayabe, Takuto Otomo, Hiroshi Kera, Kazuhiko Kawamoto | 날짜: 2025 | DOI: arXiv:2412.18781
오프라인 강화학습의 견고성 평가 개요: 다양한 품질의 오프라인 데이터셋으로 학습된 모델을 정상, 랜덤, 적대적 섭동 조건에서 평가
본 논문은 오프라인 강화학습(Offline RL) 기반 로봇 제어 시스템의 행동 공간 섭동에 대한 견고성을 체계적으로 평가하며, 기존 오프라인 RL 방법들이 액추에이터 고장과 같은 실제 운영 환경의 도전에 얼마나 취약한지를 실증적으로 증명한다.
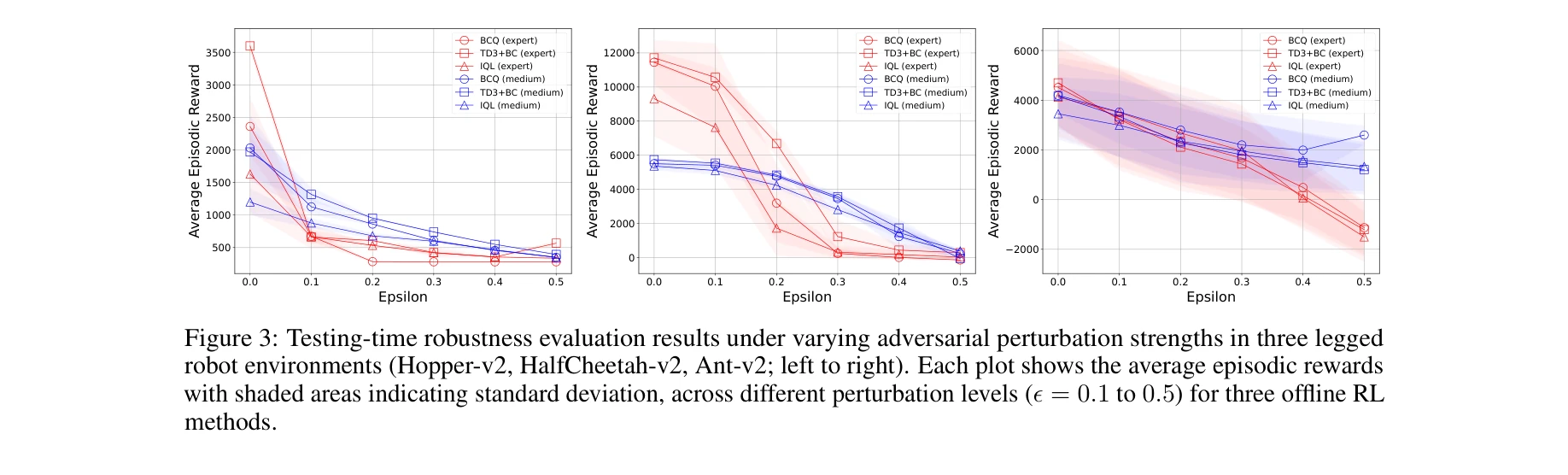
세 종류의 다리 로봇(Hopper, HalfCheetah, Ant)에서 적대적 섭동 강도에 따른 테스트 타임 견고성 평가 결과
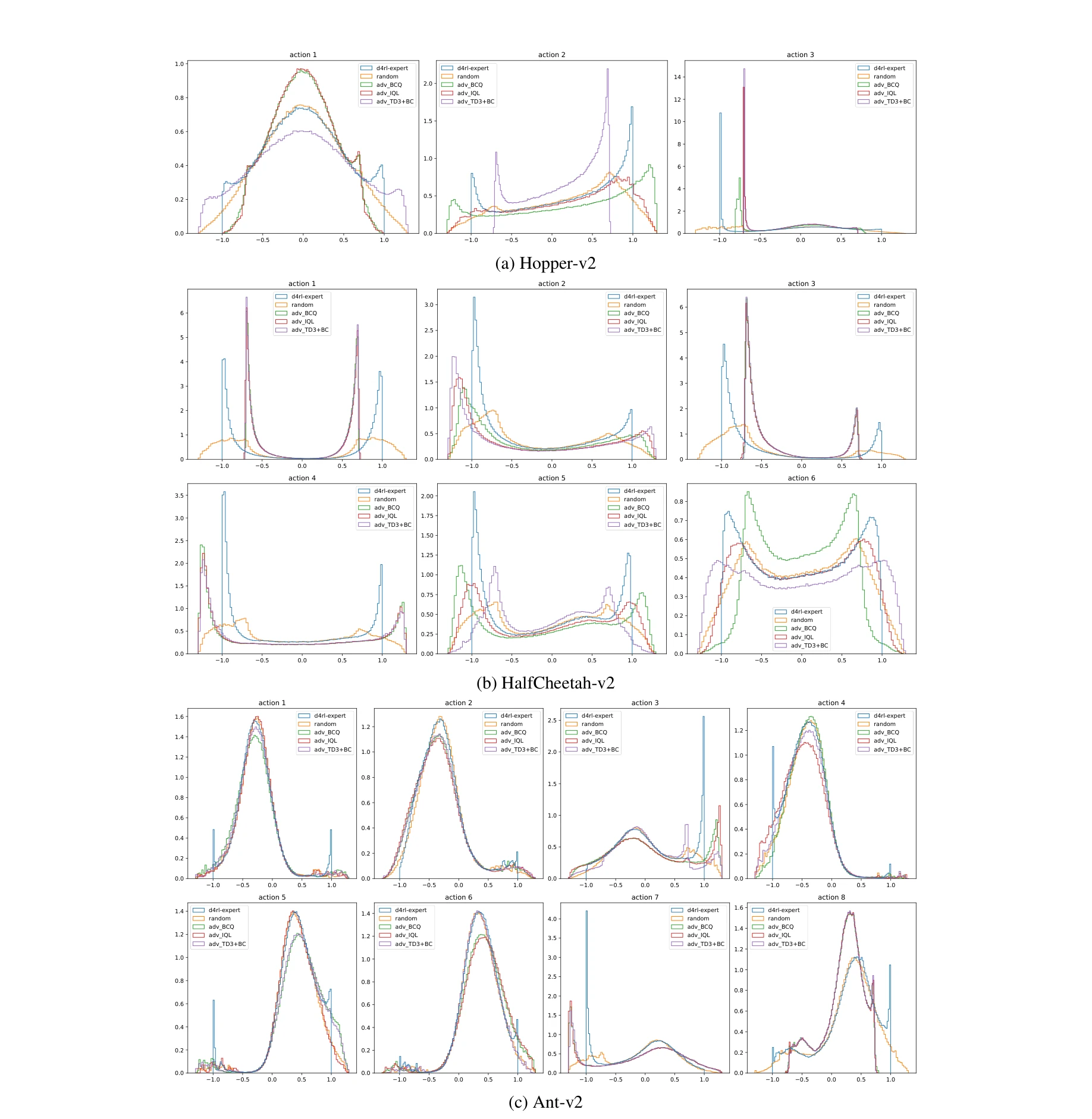
Hopper, HalfCheetah, Ant의 훈련 데이터셋에서의 행동 분포 비교: 히스토그램으로 표시된 상태-행동 커버리지
총평: 본 논문은 오프라인 강화학습의 실제 운영 환경에서의 적용 가능성에 중요한 의문을 제기하며, 행동 공간 섭동에 대한 체계적 취약성 평가를 통해 실무적 가치를 제공한다. 특히 데이터셋 커버리지와 견고성의 상관관계 규명은 향후 더 견고한 오프라인 RL 알고리즘 개발의 기초가 될 수 있다. 다만 문제 진단에는 탁월하지만 해결책 제시는 미흡하며, 실제 로봇 검증과 더 다양한 공격 형태 분석을 통한 심화가 필요하다.