Achievement
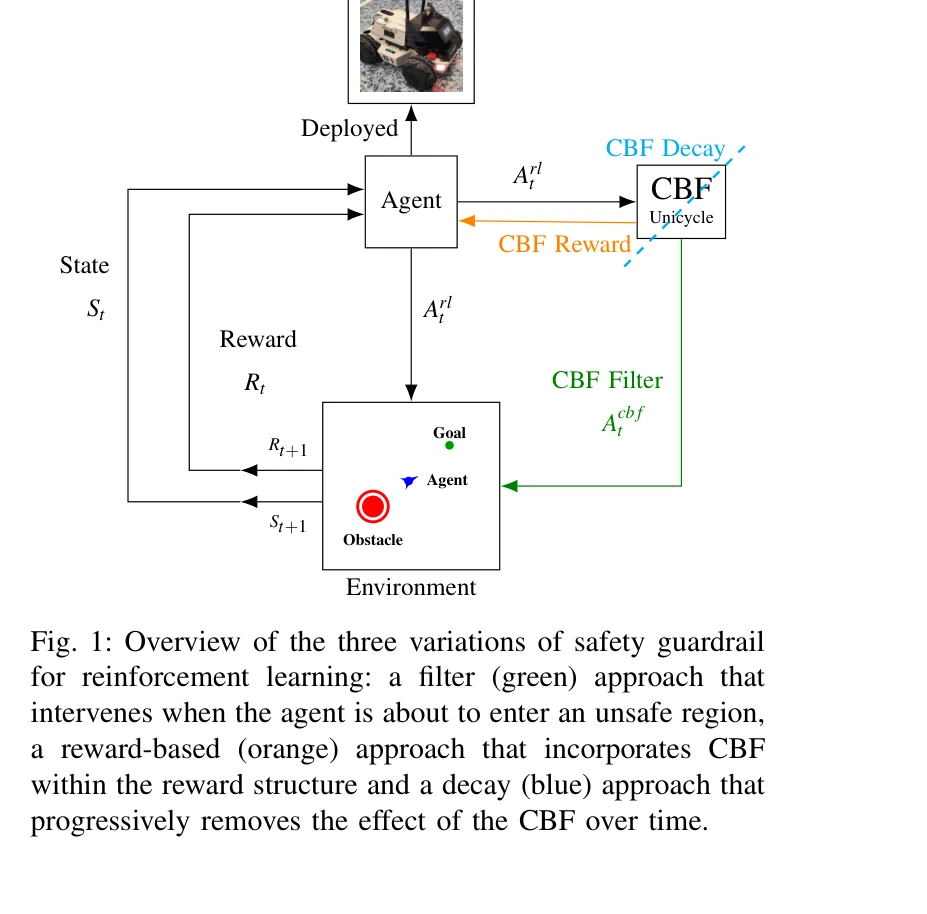
그림 1: 세 가지 안전 가드레일 변형 - 필터(초록색), 보상 기반(주황색), 감쇠(파란색)
- 세 가지 CBF-RL 통합 방식 제안:
- CBF Filter: 에이전트가 위험 영역에 진입 시 액션을 최소한으로 개입하여 교정
- CBF Reward: CBF 제안 액션으로부터의 편차를 보상 함수에 포함시켜 페널티 부여
- CBF Decay: 커리큘럼 학습 방식으로 훈련 과정에서 CBF의 영향을 점진적으로 제거
- 실제 적용 가능성 입증:
- 단순 유니사이클(unicycle) 모델로 추상화하여 다양한 로봇 동역학에 적용 가능
- 시뮬레이션에서 훈련한 정책을 4륜 차동 구동 로봇(four-wheel differential drive robot)에 성공적으로 배포
- 시뮬레이션-현실 이전(sim2real transfer) 성능 평가
