Essence
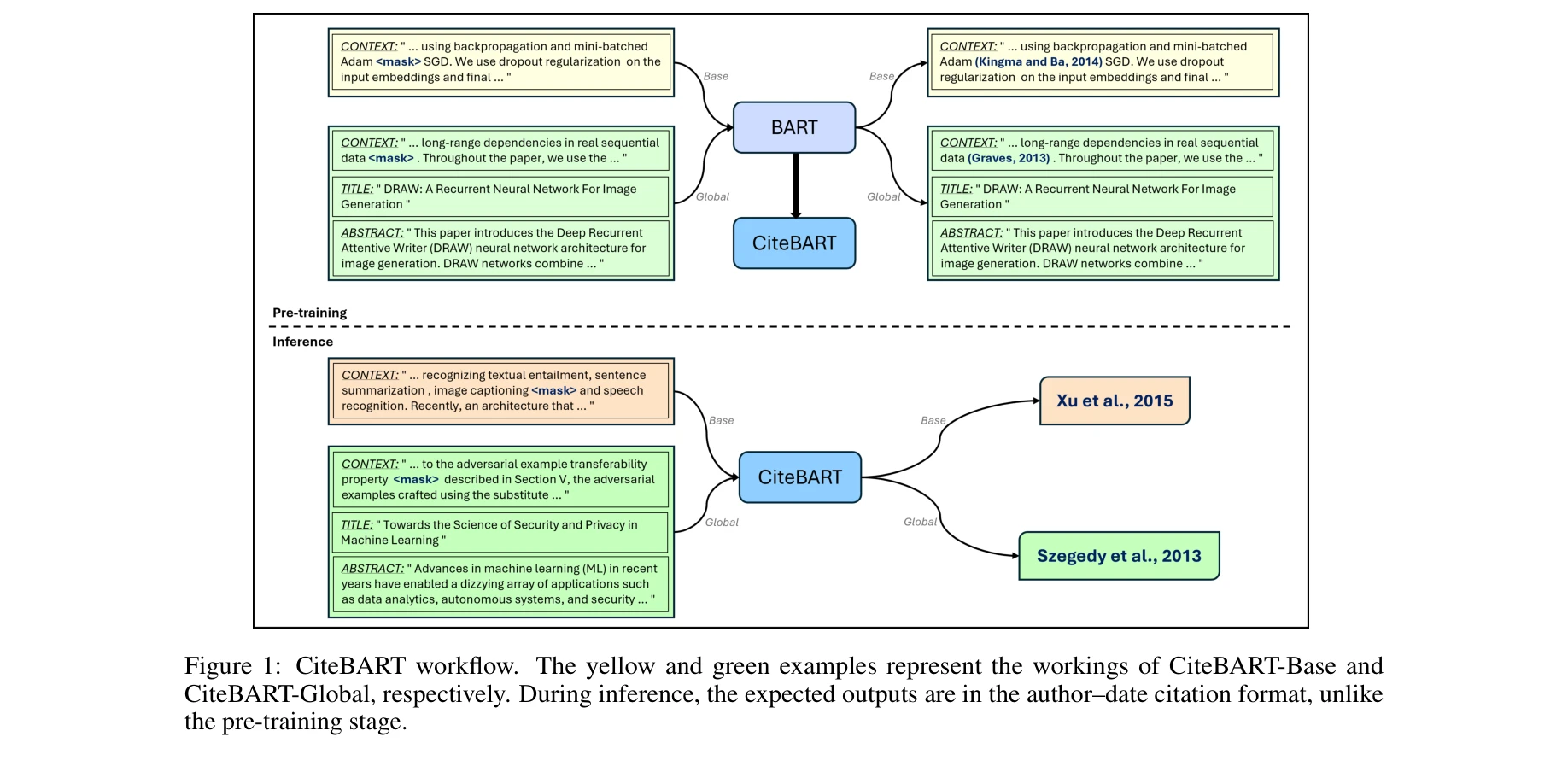
CiteBART의 워크플로우. 노란색과 녹색 예시는 각각 CiteBART-Base와 CiteBART-Global의 작동 방식을 나타낸다.
본 논문은 인용 토큰(citation token)을 마스킹하는 사용자 정의 사전학습을 통해 로컬 인용 추천(Local Citation Recommendation, LCR) 작업을 수행하는 생성형 모델 CiteBART를 제안한다. 기존의 사전-검색 및 재순위(pre-fetch and re-rank) 파이프라인과 달리 엔드-투-엔드 학습 시스템으로 우수한 성능을 달성한다.