Essence
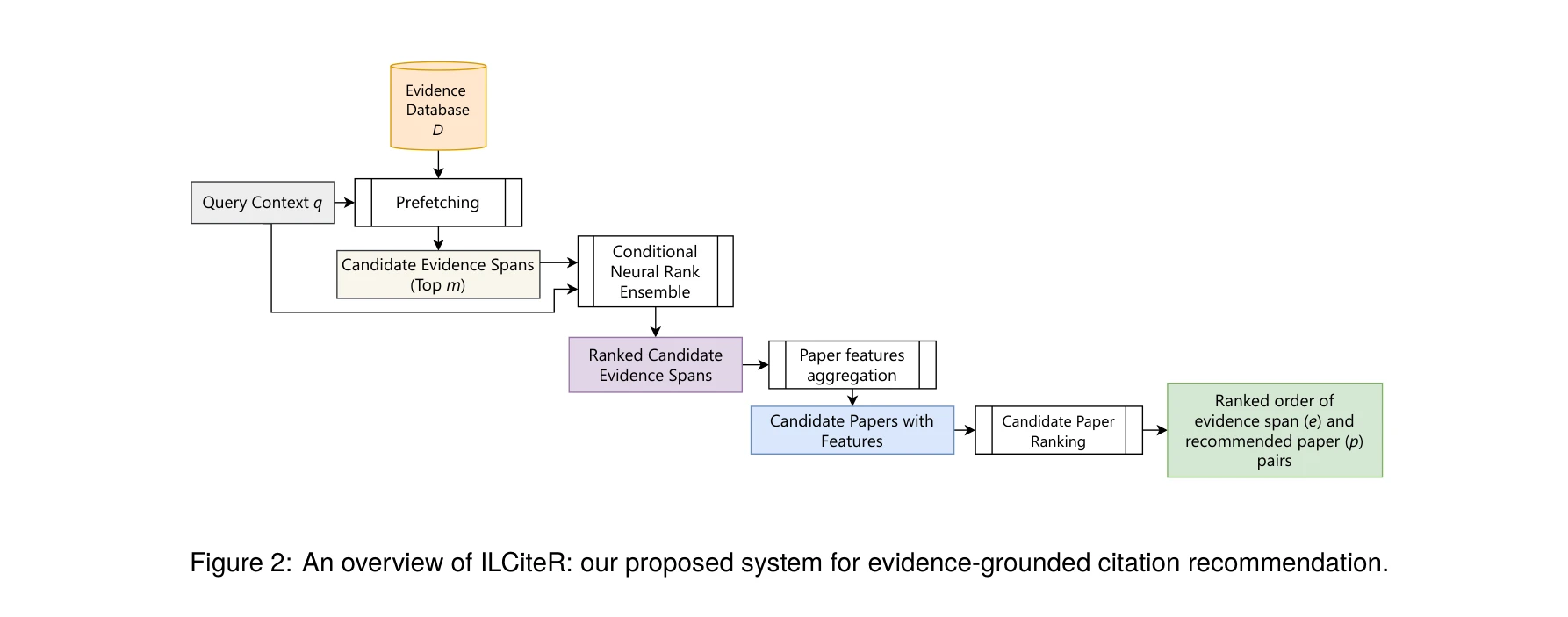
ILCiteR 시스템의 개요: 증거 데이터베이스 사전 로딩, 조건부 신경 순위 앙상블을 통한 증거 스팬 재순위화, 논문 순위화의 3단계 프로세스
본 논문은 학술 논문 인용 추천 작업에 해석가능성(interpretability)을 도입하기 위해, 쿼리(claim 또는 entity mention)에 대해 인용할 논문을 추천할 때 기존 문헌에서 추출한 유사한 증거 스팬(evidence span)을 근거로 제시하는 새로운 접근방식 ILCiteR을 제안한다.
How

조건부 신경 순위 앙상블: 여러 유사도 점수를 결합하여 증거 스팬 재순위화
증거 데이터베이스 구축 (Section 5):
- S2ORC 데이터셋에서 정규화된 전문 텍스트를 가진 20,000개 이상의 Computer Science 논문 수집
- 각 논문에서 최소 하나의 인용([REF] 태그)을 포함하는 문장 추출
- 각 문장에서 관련 텍스트 스팬을 증거로 추출하고, 동일 증거에 대한 인용 횟수를 support로 기록
2단계 재순위화 프로세스 (Section 6):
- 증거 스팬 재순위화:
- 어휘 유사도(BM25)로 m개의 후보 증거 스팬 사전 로딩
- 조건부 신경 순위 앙상블을 이용해 시맨틱 유사도(SBERT 임베딩)와 어휘 유사도 결합
- 논문 순위화:
- 선택된 증거 스팬들과 연관된 모든 논문 후보 추출
- 각 논문에 대해: (1) 최적 관련 증거 스팬의 순위, (2) 누적 support 수, (3) 출판 연도(최신성)를 종합 고려하여 최종 순위 결정
